Uso de las instrucciones de la CPU AVX: Rendimiento deficiente sin " / arch: AVX"
Mi código C++ usa SSE y ahora quiero mejorarlo para que admita AVX cuando esté disponible. Así que detecto cuando AVX está disponible y llamo a una función que usa comandos AVX. Uso Win7 SP1 + VS2010 SP1 y una CPU con AVX.
Para usar AVX, es necesario incluir esto:
#include "immintrin.h"
Y luego puede usar funciones AVX intrínsecas como _mm256_mul_ps, _mm256_add_ps etc.
El problema es que por defecto, VS2010 produce código que funciona muy lentamente y muestra la advertencia:
Advertencia C4752: Extensiones Vectoriales avanzadas de Intel(R) encontradas; considere usando / arch: AVX
Parece que VS2010 en realidad no usa instrucciones AVX, sino que las emula. Agregué /arch:AVX a las opciones del compilador y obtuve buenos resultados. Pero esta opción le dice al compilador que use comandos AVX en todas partes cuando sea posible. Así que mi código puede bloquearse en la CPU que no es compatible con AVX!
Entonces, la pregunta es cómo hacer que el compilador VS2010 produzca código AVX, pero solo cuando especifico intrínsecos AVX directamente. Para SSE funciona, solo uso funciones intrínsecas de SSE y produce código SSE sin ninguna opción de compilador como /arch:SSE. Pero para AVX no funciona por alguna razón.
2 answers
El comportamiento que está viendo es el resultado de un costoso cambio de estado.
Véase la página 102 del manual de Agner Fog:
Http://www.agner.org/optimize/microarchitecture.pdf
Cada vez que cambie incorrectamente entre las instrucciones SSE y AVX, pagará una penalización de ciclo extremadamente alta (~70).
Cuando compila sin /arch:AVX, VS2010 generará instrucciones SSE, pero seguirá utilizando AVX dondequiera que tenga intrínsecos AVX. Por lo tanto, obtendrá código que tiene instrucciones SSE y AVX, que tendrán esas penalizaciones de cambio de estado. (VS2010 sabe esto, por lo que emite esa advertencia que estás viendo.)
Por lo tanto, debe usar all SSE o all AVX. Especificar /arch:AVX le dice al compilador que use todo AVX.
Parece que estás intentando crear varias rutas de código: una para SSE y otra para AVX.
Para esto, le sugiero que separe su código SSE y AVX en dos unidades de compilación diferentes. (una compilado con /arch:AVX y uno sin) Luego enlázalos juntos y crea un despachador para elegir basado en el hardware en el que se está ejecutando.
Si necesidad para mezclar SSE y AVX, asegúrese de usar _mm256_zeroupper() o _mm256_zeroall() apropiadamente para evitar las penalizaciones de cambio de estado.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-10-20 19:52:48
Tl; dr
Uso _mm256_zeroupper(); o _mm256_zeroall(); alrededor de secciones de código usando AVX (antes o después dependiendo de los argumentos de la función). Use la opción /arch:AVX solo para archivos de origen con AVX en lugar de para un proyecto completo para evitar romper el soporte para rutas de código SSE codificadas heredadas.
Causa
Creo que la mejor explicación está en el artículo de Intel, "Evitar Penalizaciones de transición AVX-SSE" (PDF ). Abstracto estados:
La transición entre las instrucciones Intel® AVX de 256 bits y las instrucciones Intel® SSE heredadas dentro de un programa puede causar penalizaciones de rendimiento porque el hardware debe guardar y restaurar los 128 bits superiores de los registros YMM.
Separar su código AVX y SSE en diferentes unidades de compilación puede NO ayudar si cambia entre llamar código desde archivos objeto habilitados para SSE y habilitados para AVX, porque la transición puede ocurrir cuando AVX las instrucciones o el ensamblaje se mezclan con cualquiera de (del documento de Intel):
- instrucciones intrínsecas de 128 bits
- Ensamblaje en línea SSE
- Código de coma flotante C/C++ compilado para Intel® SSE
- Llamadas a funciones o bibliotecas que incluyan cualquiera de las anteriores
Esto significa que incluso puede haber penalizaciones cuando se enlaza con código externo utilizando SSE.
Detalles
Hay 3 estados de procesador definido por las instrucciones AVX, y uno de los estados es donde se dividen todos los registros YMM, permitiendo que la mitad inferior sea utilizada por las instrucciones SSE. El documento de Intel " Transiciones de estado Intel® AVX: Migración de código SSE a AVX " proporciona un diagrama de estos estados:
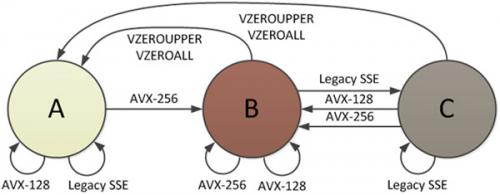
Cuando está en el estado B (modo AVX-256), todos los bits de los registros YMM están en uso. Cuando se llama una instrucción SSE, debe ocurrir una transición al estado C, y esto es donde hay un castigo. La mitad superior de todos los registros YMM debe guardarse en un búfer interno antes de que pueda comenzar SSE, incluso si resultan ser ceros. El costo de las transiciones está en el "orden de 50-80 ciclos de reloj en hardware de Sandy Bridge". También hay una penalización que va desde C - > A, como se muestra en la Figura 2.
También puede encontrar detalles sobre la penalización por cambio de estado que causa esta desaceleración en la página 130, Sección 9.12, " Transiciones entre VEX y no VEX modes " inAgner Fog's optimization guide (of version updated 2014-08-07), referenced inMystic's answer . Según su guía, cualquier transición hacia / desde este estado toma "alrededor de 70 ciclos de reloj en Sandy Bridge". Tal como indica el documento de Intel, esta es una penalización de transición evitable.
Resolución
Para evitar las penalizaciones de transición, puede eliminar todo el código SSE heredado, indicar al compilador que convierta todas las instrucciones SSE a su forma codificada VEX de instrucciones de 128 bits (si el compilador es capaz), o poner los registros YMM en un estado cero conocido antes de la transición entre el código AVX y SSE. Esencialmente, para mantener la ruta separada del código SSE, debe poner a cero los 128 bits superiores de todos los 16 registros YMM (emitiendo una instrucción VZEROUPPER) después de cualquier código que use instrucciones AVX. Poner a cero estos bits manualmente fuerza una transición al estado A, y evita la costosa penalización ya que los valores YMM no necesitan ser almacenado en un búfer interno por hardware. Lo intrínseco que realiza esta instrucción es _mm256_zeroupper. La descripción de este intrínseco es muy informativa:
Esto intrínseco es útil para borrar los bits superiores de los registros YMM cuando se realiza la transición entre las instrucciones Intel® Advanced Vector Extensions (Intel® AVX) y las instrucciones heredadas Intel® Supplemental SIMD Extensions (Intel® SSE). No hay ninguna penalización de transición si una aplicación borra los bits superiores de todos los registros de YMM (se establecen en '0') a través de
VZEROUPPER, la instrucción correspondiente para este intrínseco, antes de la transición entre las instrucciones Intel® Advanced Vector Extensions (Intel® AVX) y las instrucciones heredadas Intel® Supplemental SIMD Extensions (Intel® SSE).
En Visual Studio 2010+ (tal vez incluso más antiguo), se obtiene este intrínseco con immintrin.h.
Tenga en cuenta que la puesta a cero de los bits con otros métodos no elimina la penalización - el VZEROUPPER o VZEROALL se deben utilizar las instrucciones.
Una solución automática implementada por el compilador Intel es insertar un VZEROUPPER al principio de cada función que contiene código Intel AVX si ninguno de los argumentos es un registro YMM o __m256/__m256d/__m256i datatype, y al final de funciones si el valor devuelto no es un registro YMM o __m256/__m256d/__m256i tipo de datos.
En la naturaleza
Esta solución VZEROUPPER es utilizada por FFTW para generar una biblioteca con compatibilidad con SSE y AVX. Véase simd-avx.h :
/* Use VZEROUPPER to avoid the penalty of switching from AVX to SSE.
See Intel Optimization Manual (April 2011, version 248966), Section
11.3 */
#define VLEAVE _mm256_zeroupper
Entonces VLEAVE(); se llama al final de cada función usando intrínsecos para instrucciones AVX.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-05-23 12:09:57