Tutorial para scipy.Cluster.jerarquía [cerrado]
Estoy tratando de entender cómo manipular un clúster de jerarquía, pero la documentación también lo es ... ¿técnico?... y no puedo entender cómo funciona.
¿Hay algún tutorial que me pueda ayudar para empezar, explicando paso a paso algunas tareas simples?
Digamos que tengo el siguiente conjunto de datos:
a = np.array([[0, 0 ],
[1, 0 ],
[0, 1 ],
[1, 1 ],
[0.5, 0 ],
[0, 0.5],
[0.5, 0.5],
[2, 2 ],
[2, 3 ],
[3, 2 ],
[3, 3 ]])
Puedo hacer fácilmente el clúster de jerarquía y trazar el dendrograma:
z = linkage(a)
d = dendrogram(z)
- Ahora, ¿cómo puedo recuperar un clúster específico? Digamos que el que tiene elementos
[0,1,2,4,5,6]en el dendrograma? - ¿Cómo puedo recuperar los valores de esos elementos?
1 answers
Hay tres pasos en la agrupación aglomerativa jerárquica (HAC):
- Cuantificar los datos (
metricargumento) - Datos de clúster (
methodargumento) - Elija el número de clusters
Haciendo
z = linkage(a)
Cumplirá los dos primeros pasos. Dado que no especificó ningún parámetro, utiliza los valores estándar
metric = 'euclidean'method = 'single'
Así que z = linkage(a) le dará un solo enlace aglomerativa hierática agrupación de a. Esta agrupación es una especie de jerarquía de soluciones. De esta jerarquía se obtiene información sobre la estructura de los datos. Lo que podrías hacer ahora es:
- Compruebe qué
metrices apropiado, por ejemplocityblockochebychevcuantificará sus datos de manera diferente (cityblock,euclideanychebychevcorresponden aL1,L2, yL_infnorma) - Compruebe las diferentes propiedades / comportamientos del
methdos(p. ej..single,completeandaverage) - Compruebe cómo determinar el número de clusters, por ejemplo, leyendo la wiki sobre ello {[50]]}
- Calcular índices en las soluciones encontradas (clusterings) como el coeficiente de silueta (con este coeficiente se obtiene una retroalimentación sobre la calidad de lo bien que un punto/observación se ajusta al clúster al que se le asigna la agrupación). Diferentes índices utilizan diferentes criterios para calificar una agrupación.
Aquí hay algo para comenzar con
import numpy as np
import scipy.cluster.hierarchy as hac
import matplotlib.pyplot as plt
a = np.array([[0.1, 2.5],
[1.5, .4 ],
[0.3, 1 ],
[1 , .8 ],
[0.5, 0 ],
[0 , 0.5],
[0.5, 0.5],
[2.7, 2 ],
[2.2, 3.1],
[3 , 2 ],
[3.2, 1.3]])
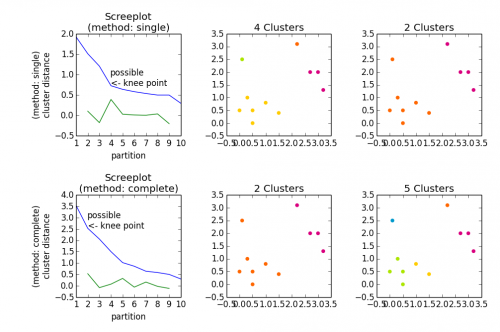
fig, axes23 = plt.subplots(2, 3)
for method, axes in zip(['single', 'complete'], axes23):
z = hac.linkage(a, method=method)
# Plotting
axes[0].plot(range(1, len(z)+1), z[::-1, 2])
knee = np.diff(z[::-1, 2], 2)
axes[0].plot(range(2, len(z)), knee)
num_clust1 = knee.argmax() + 2
knee[knee.argmax()] = 0
num_clust2 = knee.argmax() + 2
axes[0].text(num_clust1, z[::-1, 2][num_clust1-1], 'possible\n<- knee point')
part1 = hac.fcluster(z, num_clust1, 'maxclust')
part2 = hac.fcluster(z, num_clust2, 'maxclust')
clr = ['#2200CC' ,'#D9007E' ,'#FF6600' ,'#FFCC00' ,'#ACE600' ,'#0099CC' ,
'#8900CC' ,'#FF0000' ,'#FF9900' ,'#FFFF00' ,'#00CC01' ,'#0055CC']
for part, ax in zip([part1, part2], axes[1:]):
for cluster in set(part):
ax.scatter(a[part == cluster, 0], a[part == cluster, 1],
color=clr[cluster])
m = '\n(method: {})'.format(method)
plt.setp(axes[0], title='Screeplot{}'.format(m), xlabel='partition',
ylabel='{}\ncluster distance'.format(m))
plt.setp(axes[1], title='{} Clusters'.format(num_clust1))
plt.setp(axes[2], title='{} Clusters'.format(num_clust2))
plt.tight_layout()
plt.show()
Da
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-08-12 18:47:49