Similitud de coseno y tf-idf
Estoy confundido por el siguiente comentario acerca de TF-IDF y Coseno Similitud.
Estaba leyendo en ambos y luego en wiki bajo Similitud de Coseno encuentro esta oración "En caso de recuperación de información, la similitud de coseno de dos documentos variará de 0 a 1, ya que las frecuencias de término (pesos tf-idf) no pueden ser negativas. El ángulo entre dos vectores de frecuencia de término no puede ser mayor que 90."
Ahora me pregunto....no son 2 diferentes cosas?
¿tf-idf ya está dentro de la similitud del coseno? Si es así, entonces qué diablos-solo puedo ver los productos de puntos internos y longitudes euclidianas.
Pensé que tf-idf era algo que se podía hacer antes de ejecutar la similitud de coseno en los textos. ¿Me he perdido algo?
5 answers
Tf-idf es una transformación que se aplica a los textos para obtener dos vectores de valor real. A continuación, puede obtener la similitud coseno de cualquier par de vectores tomando su producto escalar y dividiendo por el producto de sus normas. Que produce el coseno del ángulo entre los vectores.
Si d2 y q son vectores tf-idf, entonces
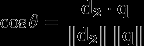
Donde θ es el ángulo entre los vectores. As θ ranges from 0 to 90 degrees, cos θ varía de 1 a 0. θ puede solo variar de 0 a 90 grados, porque los vectores tf-idf no son negativos.
No hay una conexión particularmente profunda entre tf-idf y el modelo de similitud de coseno/espacio vectorial; tf-idf simplemente funciona bastante bien con matrices de términos de documento. Sin embargo, tiene usos fuera de ese dominio y, en principio, podría sustituir otra transformación en un VSM.
(Fórmula tomada de la Wikipedia , de ahí la d2.)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-11-03 17:47:00
TF-IDF es solo una forma de medir la importancia de los tokens en el texto; es solo una forma muy común de convertir un documento en una lista de números (el término vector que proporciona un borde del ángulo del que está obteniendo el coseno).
Para calcular la similitud de coseno, necesita dos vectores de documento; los vectores representan cada término único con un índice, y el valor en ese índice es una medida de cuán importante es ese término para el documento y para el concepto general de similitud de documento en general.
Simplemente podría contar el número de veces que cada término ocurrió en el documento ( T erm F requency), y usar ese resultado entero para la puntuación del término en el vector, pero los resultados no serían muy buenos. Términos extremadamente comunes (como" es"," y "y" el") harían que muchos documentos parecieran similares entre sí. (Esos ejemplos particulares se pueden manejar usando una lista de palabras clave , pero otros términos comunes que no son lo suficientemente generales como para ser considerado una palabra clave causa el mismo tipo de problema. En Stackoverflow, la palabra "pregunta" podría caer en esta categoría. Si estuviera analizando recetas de cocina, probablemente se encontraría con problemas con la palabra "huevo".)
TF-IDF ajusta la frecuencia de los términos brutos teniendo en cuenta la frecuencia de cada término en general (el Document Frequency). Inverse Document Frequency es generalmente el registro del número de documentos dividido por el número de de documentos en los que aparece el término (imagen de Wikipedia):
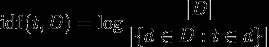
Piense en el 'registro' como un matiz menor que ayuda a que las cosas funcionen a largo plazo grows crece cuando su argumento crece, por lo que si el término es raro, el IDF será alto (muchos documentos divididos por muy pocos documentos), si el término es común, el IDF será bajo (muchos documentos divididos por muchos documentos ~= 1).
Digamos que tienes 100 recetas, y todas menos una requiere huevos, ahora tienes tres documentos más todos ellos contienen la palabra "huevo", una vez en el primer documento, dos veces en el segundo documento y una vez en el tercer documento. La frecuencia del término "huevo" en cada documento es 1 o 2, y la frecuencia del documento es 99 (o, posiblemente, 102, si se cuentan los nuevos documentos. Vamos a seguir con 99).
El TF-IDF de 'huevo' es:
1 * log (100/99) = 0.01 # document 1
2 * log (100/99) = 0.02 # document 2
1 * log (100/99) = 0.01 # document 3
Todos estos son números bastante pequeños; en contraste, veamos otra palabra que solo aparece en 9 de sus 100 corpus de recetas: 'rúcula'. Ocurre dos veces en el primer documento, tres veces en el segundo, y no aparece en el tercer documento.
El TF-IDF para 'rúcula' es:
1 * log (100/9) = 2.40 # document 1
2 * log (100/9) = 4.81 # document 2
0 * log (100/9) = 0 # document 3
'rúcula' es realmente importante para el documento 2, al menos comparado con 'huevo'. ¿A quién le importa cuántas veces ocurre el huevo? Todo contiene huevo! Estos vectores de término son mucho más informativos que los conteos simples, y darán como resultado que los documentos 1 y 2 estén mucho más cerca entre sí (con respecto al documento 3) de lo que estarían si contara un término simple fueron utilizados. En este caso, el mismo resultado probablemente surgiría (hey! solo tenemos dos términos aquí), pero la diferencia sería menor.
La conclusión aquí es que TF-IDF genera medidas más útiles de un término en un documento, por lo que no se enfoca en términos realmente comunes (palabras clave, 'huevo'), y pierde de vista los términos importantes ('rúcula').
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-11-30 17:20:29
El procedimiento matemático completo para la similitud de coseno se explica en estos tutoriales
Supongamos que si desea calcular la similitud de coseno entre dos documentos, el primer paso será calcular los vectores tf-idf de los dos documentos. y luego encontrar el producto escalar de estos dos vectores. Esos tutoriales te ayudarán:)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-01-20 11:59:16
La ponderación Tf/idf tiene algunos casos en los que fallan y generan un error NaN en el código durante la computación. Es muy importante leer esto: http://www.p-value.info/2013/02/when-tfidf-and-cosine-similarity-fail.html
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-06-07 22:43:18
Tf-idf se usa solo para encontrar los vectores de los documentos basados en tf - Term Frequency - que se usa para encontrar cuántas veces aparece el término en el documento y inverse document frequency - que da la medida de cuántas veces aparece el término en toda la colección.
Entonces puede encontrar la similitud de coseno entre los documentos.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-06-20 17:18:49