Roscado vs hilo simple
¿Siempre se garantiza que una aplicación multihilo se ejecutará más rápido que una sola aplicación threaded?
Tengo dos subprocesos que rellena datos de una fuente de datos, pero diferentes entidades (por ejemplo: base de datos, de dos tablas diferentes), parece que la versión de subproceso único de la aplicación se está ejecutando más rápido que la versión con dos subprocesos.
¿Por qué sería la razón? cuando miro el monitor de rendimiento, ambas cpu son muy puntiagudas ? es esto debido al contexto ¿cambiar?
¿Cuáles son las mejores prácticas para conectar la CPU y utilizarla completamente?
Espero que esto no sea ambiguo.
8 answers
Una analogía podría ayudar.
Tienes un montón de cartas que necesitas entregadas a varias direcciones alrededor de la ciudad. Así que contratas a un tipo con una motocicleta para entregar tus cartas.
Las señales de tráfico en su ciudad son señales de tráfico perfectas. Siempre son verdes a menos que haya alguien en la intersección.
El tipo de la motocicleta da vueltas entregando un montón de cartas. Ya que no hay nadie más en el camino, cada luz es verde, lo cual es increíble. Pero crees que esto podría ser más rápido. Lo sé, contrataré a otro conductor.El problema es que **solo tienes una motocicleta*. Así que ahora su primer conductor conduce alrededor en la motocicleta por un tiempo, y luego de vez en cuando se detiene, se baja, y el segundo conductor corre hacia arriba, salta y conduce alrededor.
¿Esto es más rápido? No, por supuesto que no. Eso es más lento . Agregar más hilos no hace nada más rápido. Los hilos no son mágicos . Si un procesador es capaz para hacer mil millones de operaciones por segundo, agregar otro hilo no hace que de repente otros mil millones de operaciones por segundo estén disponibles. Más bien, roba recursos de otros hilos. Si una motocicleta puede ir 100 millas por hora, detener la bicicleta y tener otro conductor subir no hace que sea más rápido! Claramente, en promedio, las cartas no se entregan más rápido en este esquema, solo se entregan en un orden diferente.
Bien, ¿qué pasa si contratas a dos conductores y dos motocicletas? Ahora tienes dos procesadores y un hilo por procesador, por lo que va a ser más rápido, ¿verdad? No, porque nos olvidamos de los semáforos. Antes, solo había una motocicleta conduciendo a velocidad a la vez. Ahora hay dos conductores y dos motocicletas, lo que significa que ahora a veces una de las motocicletas tendrá que esperar porque la otra está en la intersección. De nuevo, agregar más hilos te ralentiza porque pasas más tiempo disputando bloqueos. El más los procesadores que añades, peor se pone; terminas con más y más tiempo esperando en las luces rojas y menos y menos tiempo manejando mensajes.
Agregar más subprocesos puede causar una escalabilidad negativa si al hacerlo hace que los bloqueos se disputen. Cuantos más hilos, más contención, más lentas van las cosas.
Supongamos que haces que los motores sean más rápidos now ahora tienes más procesadores, más subprocesos y procesadores más rápidos. ¿Eso siempre lo hace más rápido? NO. Con frecuencia lo hace ni. Aumentar la velocidad del procesador puede hacer que los programas multiproceso sean más lentos. De nuevo, piensa en el tráfico.
Supongamos que tenemos una ciudad con miles de conductores y sesenta y cuatro motocicletas, todos los conductores corriendo de ida y vuelta entre las motocicletas, algunas de las motocicletas en las intersecciones bloqueando otras motocicletas. Ahora haces que todas esas motocicletas corran más rápido. ¿Eso ayuda? Bueno, en la vida real, cuando estás conduciendo, ¿llegas a donde vas el doble de rápido en un Porsche como en un Honda Civic? Por supuesto que no; la mayor parte del tiempo en la ciudad de conducción que está atascado en el tráfico.
Si puedes conducir más rápido, a menudo terminas esperando en el tráfico más tiempo porque terminas conduciendo hacia la congestión más rápido. Si todo el mundo conduce hacia la congestión más rápido, entonces la congestión empeora.
El rendimiento multiproceso puede ser profundamente contradictorio. Si desea un alto rendimiento extremo, recomiendo no ir con un solución multihilo a menos que tenga una aplicación que sea "vergonzosamente paralela" that es decir, alguna aplicación que obviamente sea susceptible de lanzar múltiples procesadores, como la computación de conjuntos de Mandelbrot o hacer ray tracing o algo así. Y luego, no arroje más hilos al problema de los que tiene procesadores. Pero para muchas aplicaciones, iniciar más subprocesos te ralentiza.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-05-25 07:25:36
Mi opinión
No, no se garantiza que una aplicación multihilo se ejecute más rápido que una aplicación de un solo subproceso. El problema principal es distribuir correctamente la carga de trabajo a todos los núcleos disponibles y minimizar el bloqueo y el cambio de contexto.
Creo que algunas de las peores cosas que la gente puede hacer es ir y tratar de multiproceso cada poco de sus tareas intensivas en CPU. A veces terminan creando cientos de hilos y cada hilo está intentando para realizar una gran cantidad de cálculos de uso intensivo de CPU. Lo mejor que se puede hacer en esa situación es crear uno (o tal vez dos) hilos por núcleo.
En los casos en los que hay una interfaz de usuario involucrada, casi siempre se prefiere delegar todo el trabajo intensivo de la CPU en subprocesos para mantener la interfaz de usuario sensible. Este es probablemente el uso más popular para hilos.
...parece una versión de rosca única de la aplicación se está ejecutando más rápido que la versión con dos hilo.
¿Ha realizado algún análisis de rendimiento? Si no lo has hecho, entonces lo que has observado es algo irrelevante.
¿Cuáles son las mejores prácticas para jack la CPU y utilizarlo plenamente?
Dada la descripción de su problema, no parece que sus problemas de rendimiento estén vinculados a la CPU, sino a la E/S... su comunicación con la base de datos es mucho más lenta que su caché de procesador y si se trata de una base de datos de red, es incluso más lenta que su disco duro. Su cuello de botella de rendimiento está con su base de datos, por lo que todo lo que necesita hacer es crear suficientes subprocesos para maximizar el rendimiento de su conexión a la base de datos.
Directamente desde Wikipedia:
Ventajas
Algunas ventajas incluyen:
- Si un subproceso recibe muchos errores de caché, el otro subproceso puede continuar, aprovechando los recursos informáticos no utilizados, lo que puede conducir a una ejecución general más rápida, ya que estos recursos habría estado inactivo si solo se ejecutara un solo subproceso.
- Si un subproceso no puede utilizar todos los recursos informáticos de la CPU (porque las instrucciones dependen del resultado del otro), ejecutar otro subproceso permite no dejarlos inactivos.
- Si varios subprocesos funcionan en el mismo conjunto de datos, pueden compartir su caché, lo que lleva a un mejor uso de la caché o sincronización de sus valores.
Desventajas
Algunas críticas al multihilo incluir:
- Múltiples subprocesos pueden interferir entre sí cuando se comparten recursos de hardware como cachés o buffers de lookaside de traducción (TLBs).
- Los tiempos de ejecución de un solo subproceso no se mejoran, pero se pueden degradar, incluso cuando solo se ejecuta un subproceso. Esto se debe a frecuencias más lentas y/o etapas de tubería adicionales que son necesarias para acomodar el hardware de conmutación de hilo.
- El soporte de hardware para Multihilo es más visible para el software, por lo tanto requiere más cambios tanto en los programas de aplicación como en los sistemas operativos que el Multiprocesamiento.
Actualizar
Además, el servidor de base de datos está en el la misma máquina que el código está ejecutando. no es un servidor sql. es un nosql dbms. así que por favor no asumas nada acerca del servidor de base de datos.
Algunos sistemas NoSQL están basados en disco y la lectura desde disco de múltiples subprocesos está casi garantizada para disminuir el rendimiento. El disco duro puede tener que mover el dirígete a diferentes sectores del disco al saltar entre hilos y eso es malo!
Entiendo el punto que quería make es la velocidad IO. pero aún así es la misma máquina. ¿Por qué IO es tan lento ?
Su sistema NoSQL puede estar basado en disco, por lo tanto, todos sus datos se almacenan en el disco en lugar de cargarse en la memoria (como SQL Server). Además, piense en la arquitectura: el disco es una caché para la RAM, la RAM es el almacenamiento en caché para la caché de la CPU, y la caché de la CPU es para la CPU se registra. Así que Disco - > Ram - > Caché de CPU - > Registros, hay 3 niveles de almacenamiento en caché antes de llegar a los registros. Dependiendo de la cantidad de datos que está utilizando, es posible que obtenga una gran cantidad de errores de caché para ambos hilos en cada uno de esos niveles... una falta de caché en la caché de la CPU cargará más datos de la RAM, una falta de caché en la RAM cargará más datos del disco, todo esto se traduce en rendimiento reducido.
En otros críticos " crear lo suficiente hilos a utilizar .."la creación de muchos los hilos también tomarán tiempo. ¿verdad?
En realidad no... sólo tienes dos hilos. ¿Cuántas veces estás creando los hilos? ¿Con qué frecuencia los estás creando? Si solo está creando dos subprocesos y está haciendo todo su trabajo en esos dos subprocesos durante toda la vida útil de la aplicación, entonces prácticamente no hay sobrecarga de rendimiento desde la creación de los subprocesos que debería preocuparle.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-05-25 07:57:55
Si su programa es pesado E/S y pasa la mayor parte del tiempo esperando E/S (como la operación de la base de datos), por lo que el subproceso no se ejecutaría más rápido.
Si hace mucho cálculo en CPU, por lo que tendrá beneficio o no, dependerá de cómo lo escribas.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-05-25 05:46:28
Por supuesto que no. El enhebrado impone una sobrecarga, por lo que si los beneficios de la aplicación dependen de cómo paralelo es.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-05-25 05:37:34
No, no lo es. Porque cuando haces multi-threading, tu CPU tiene que cambiar entre hilo, memoria, registro, y eso cuesta. Hay algunas tareas que son divisibles como merge sort, pero hay algunas tareas que pueden no ser divisibles para sub tareas como verificar si un número es primo o no (es solo mi ejemplo repentino), y luego si intentas separarlo, simplemente se ejecuta como un problema de subproceso único.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-09-07 06:57:46
La sobrecarga de cambio de contexto no es un problema hasta que tenga cientos de subprocesos. El problema del cambio de contexto se sobrestima a menudo (ejecute el administrador de tareas y notifique cuántos hilos ya se han iniciado). Los picos que se observan dependen de las comunicaciones de red que son bastante inestables en comparación con los cálculos de cpu locales.
Sugeriría escribir aplicaciones escalables en SEDA (Staged Event Driven Architecture) cuando el sistema está compuesto de varios (5-15) componentes y cada componente tiene su propia cola de mensajes con grupo de subprocesos delimitado. Puede ajustar el tamaño de los grupos e incluso aplicar algoritmos que cambian el tamaño de los grupos de subprocesos para hacer que algunos componentes sean más productivos que otros (ya que todos los componentes comparten las mismas CPU). Puede ajustar el tamaño de los grupos para hardware específico que hace que las aplicaciones SEDA sean extremadamente sintonizables.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-05-25 05:50:05
He visto ejemplos del mundo real donde el código se ha desempeñado tan mal con más procesadores añadidos (horrible contención de bloqueo entre subprocesos) que el sistema necesitaba tener procesadores eliminados para restaurar el rendimiento; así que sí, es posible hacer que el código funcione peor agregando más subprocesos de ejecución.
IO aplicaciones restringidas son otro buen ejemplo, mencionado anteriormente.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-05-25 07:39:11
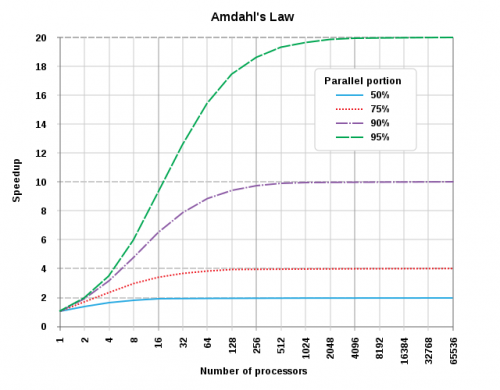
De acuerdo con la ley de Amdahl la velocidad máxima depende de la proporción del algoritmo que puede ser paralelizado. Si el algoritmo es altamente paralelo al aumento de la cantidad de CPU y subprocesos tendrá un gran aumento. Si el algoritmo no es paralelo (hay mucho control de flujo de código o contención de datos), entonces no hay ganancia o incluso puede suceder que exista disminución del rendimiento.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-06-07 10:24:09