Rendimiento de bucle de código C
Tengo un núcleo de suma múltiple dentro de mi aplicación y quiero aumentar su rendimiento.
Utilizo un Intel Core i7-960 (reloj de 3,2 GHz) y ya he implementado manualmente el kernel utilizando intrínsecos SSE de la siguiente manera:
for(int i=0; i<iterations; i+=4) {
y1 = _mm_set_ss(output[i]);
y2 = _mm_set_ss(output[i+1]);
y3 = _mm_set_ss(output[i+2]);
y4 = _mm_set_ss(output[i+3]);
for(k=0; k<ksize; k++){
for(l=0; l<ksize; l++){
w = _mm_set_ss(weight[i+k+l]);
x1 = _mm_set_ss(input[i+k+l]);
y1 = _mm_add_ss(y1,_mm_mul_ss(w,x1));
…
x4 = _mm_set_ss(input[i+k+l+3]);
y4 = _mm_add_ss(y4,_mm_mul_ss(w,x4));
}
}
_mm_store_ss(&output[i],y1);
_mm_store_ss(&output[i+1],y2);
_mm_store_ss(&output[i+2],y3);
_mm_store_ss(&output[i+3],y4);
}
Sé que puedo usar vectores fp empaquetados para aumentar el rendimiento y ya lo hice con éxito, pero quiero saber por qué el código escalar único no es capaz de cumplir con el rendimiento máximo del procesador.
El rendimiento de este núcleo en mi máquina es ~1.6 operaciones FP por ciclo, mientras que el máximo sería 2 operaciones FP por ciclo (ya que FP add + FP mul se puede ejecutar en paralelo).
Si estoy en lo correcto al estudiar el código de ensamblaje generado, el horario ideal se vería como sigue, donde la instrucción mov toma 3 ciclos, la latencia del interruptor del dominio de carga al dominio FP para las instrucciones dependientes toma 2 ciclos, la multiplicación de FP toma 4 ciclos y la adición de FP toma 3 ciclos. (Tenga en cuenta que el la dependencia de multiplicar - > agregar no incurre en ninguna latencia de conmutación porque las operaciones pertenecen al mismo dominio).
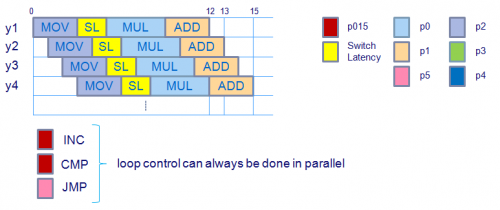
De acuerdo con el rendimiento medido (~80% del rendimiento teórico máximo) hay una sobrecarga de ~3 instrucciones por 8 ciclos.
Estoy tratando de:
- deshacerse de esta sobrecarga, o
- explicar de dónde viene
Por supuesto, existe el problema con los errores de caché y la desalineación de datos ¿qué puede aumentar la latencia de las instrucciones de movimiento, pero hay otros factores que podrían jugar un papel aquí? ¿Como los puestos de lectura de registros o algo así?
Espero que mi problema esté claro, gracias de antemano por sus respuestas!
Actualización: El ensamblaje del bucle interno se ve de la siguiente manera:
...
Block 21:
movssl (%rsi,%rdi,4), %xmm4
movssl (%rcx,%rdi,4), %xmm0
movssl 0x4(%rcx,%rdi,4), %xmm1
movssl 0x8(%rcx,%rdi,4), %xmm2
movssl 0xc(%rcx,%rdi,4), %xmm3
inc %rdi
mulss %xmm4, %xmm0
cmp $0x32, %rdi
mulss %xmm4, %xmm1
mulss %xmm4, %xmm2
mulss %xmm3, %xmm4
addss %xmm0, %xmm5
addss %xmm1, %xmm6
addss %xmm2, %xmm7
addss %xmm4, %xmm8
jl 0x401b52 <Block 21>
...
3 answers
Noté en los comentarios que:
- El bucle tarda 5 ciclos en ejecutarse.
- Se "supone" tomar 4 ciclos. (puesto que hay 4 añade y 4 multiplies)
Sin embargo, su ensamblado muestra 5 instrucciones SSE movssl. De acuerdo con Las tablas de Agner Fog todas las instrucciones de movimiento SSE en coma flotante son al menos 1 inst / ciclo rendimiento recíproco para Nehalem.
Ya que tienes 5 de ellos, no puedes hacer mejor que 5 ciclos/iteración.
Así que para llegar al máximo rendimiento, necesita reducir el número de cargas que tiene. No puedo ver inmediatamente este caso en particular, pero podría ser posible.
Un enfoque común es usar mosaico. Donde se agregan niveles de anidamiento para mejorar la localidad. Aunque se usa principalmente para mejorar el acceso a la caché, también se puede usar en registros para reducir el # de carga / tiendas que se necesitan.
En última instancia, su el objetivo es reducir el número de cargas a ser menor que el número de add / muls. Así que este podría ser el camino a seguir.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-04-03 16:55:20
Muchas gracias por sus respuestas, esto explicó mucho. Continuando con mi pregunta, cuando uso instrucciones empaquetadas en lugar de instrucciones escalares, el código que usa intrínsecos se vería muy similar:
for(int i=0; i<size; i+=16) {
y1 = _mm_load_ps(output[i]);
…
y4 = _mm_load_ps(output[i+12]);
for(k=0; k<ksize; k++){
for(l=0; l<ksize; l++){
w = _mm_set_ps1(weight[i+k+l]);
x1 = _mm_load_ps(input[i+k+l]);
y1 = _mm_add_ps(y1,_mm_mul_ps(w,x1));
…
x4 = _mm_load_ps(input[i+k+l+12]);
y4 = _mm_add_ps(y4,_mm_mul_ps(w,x4));
}
}
_mm_store_ps(&output[i],y1);
…
_mm_store_ps(&output[i+12],y4);
}
El rendimiento medido de este núcleo es de aproximadamente 5.6 operaciones FP por ciclo, aunque esperaría que fuera exactamente 4 veces el rendimiento de la versión escalar, es decir,4.1, 6=6,4 FP ops por ciclo.
Teniendo en cuenta el movimiento del factor de peso (gracias por señalar que fuera), el horario se ve como:
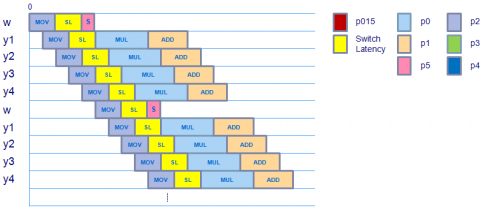
Parece que la programación no cambia, aunque hay una instrucción adicional después de la operación movss que mueve el valor de peso escalar al registro XMM y luego usa shufps para copiar este valor escalar en todo el vector. Parece que el vector de peso está listo para ser utilizado para el mulps en el tiempo teniendo en cuenta la latencia de conmutación de carga al dominio de punto flotante, por lo que esto no debería incurrir en ningún extra latencia.
El movaps (movimiento alineado, lleno),addps & mulps las instrucciones que se usan en este kernel (verificadas con código ensamblador) tienen la misma latencia y rendimiento que sus versiones escalares, por lo que esto tampoco debería incurrir en ninguna latencia adicional.
¿Alguien tiene una idea de dónde se gasta este ciclo adicional por 8 ciclos, asumiendo que el rendimiento máximo que este núcleo puede obtener es 6.4 FP ops por ciclo y se está ejecutando a 5.6 FP ops por ciclo?
Gracias de nuevo por todos sus ¡Socorro!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-04-04 07:41:12
Haciendo esto una respuesta de mi comentario.
En una distribución de Linux que no es un servidor, creo que el temporizador de interrupción generalmente se establece en 250 Hz por defecto, aunque eso varía según la distribución, casi siempre supera los 150. Esa velocidad es necesaria para proporcionar una GUI interactiva de más de 30 fps. Ese temporizador de interrupción se usa para adelantarse al código. Eso significa que más de 150 veces por segundo su código se interrumpe y el código del programador se ejecuta y decide a qué darle más tiempo. Suena como que lo estás haciendo muy bien simplemente obtener el 80% de velocidad máxima, no hay problemas. Si necesita una mejor instalación, por ejemplo, Ubuntu Server (100Hz por defecto) y ajustar el núcleo (preemption off) un poco
EDIT: En un sistema de más de 2 núcleos esto tiene mucho menos impacto, ya que su proceso casi definitivamente será abofeteado en un núcleo y más o menos dejado para hacer sus propias cosas.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-04-03 23:29:12