Reconocimiento de patrones en series temporales [cerrado]
Al procesar un gráfico de series temporales, me gustaría detectar patrones que se parecen a este:
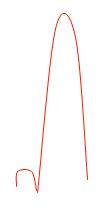
Usando una serie temporal de muestra como ejemplo, me gustaría poder detectar los patrones marcados aquí:
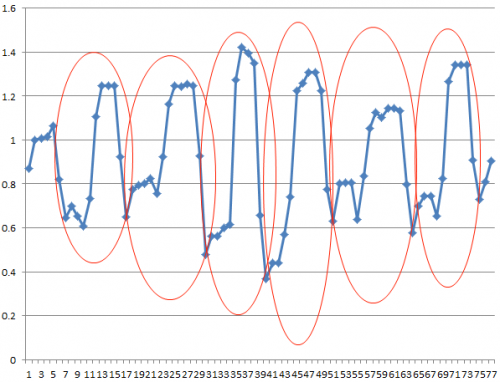
¿Qué tipo de algoritmo de IA (asumo las técnicas de aprendizaje de marchine) necesito usar para lograr esto? ¿Hay alguna biblioteca (en C/C++) que pueda usar?
5 answers
Aquí hay un resultado de muestra de un pequeño proyecto que hice para particionar datos de ecg.
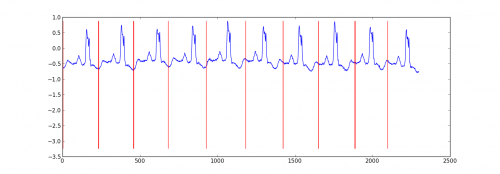
Mi enfoque fue un "HMM autorregresivo de conmutación" (google esto si no has oído hablar de él) donde cada punto de datos se predice desde el punto de datos anterior utilizando un modelo de regresión bayesiana. Creé 81 estados ocultos: un estado basura para capturar datos entre cada latido, y 80 estados ocultos separados correspondientes a diferentes posiciones dentro del patrón de latido. El patrón 80 estados fueron construye directamente a partir de un croma solo ritmo y tuvo dos transiciones - un auto de transición y la transición al siguiente estado en el patrón. El estado final en el patrón pasó a sí mismo o al estado basura.
Entrené el modelo con Viterbi training, actualizando solo los parámetros de regresión.
Los resultados fueron adecuados en la mayoría de los casos. Un Campo Aleatorio Condicional de estructura similar probablemente funcionaría mejor, pero la capacitación de un CRF requeriría etiquetado manual de patrones en el conjunto de datos si aún no tiene datos etiquetados.
Editar:
Aquí hay un ejemplo de código python - no es perfecto, pero da el enfoque general. Implementa EM en lugar de entrenamiento Viterbi, que puede ser un poco más estable. El conjunto de datos del ecg es de http://www.cs.ucr.edu / ~eamonn/discords/ECG_data.zip
import numpy as np
import numpy.random as rnd
import matplotlib.pyplot as plt
import scipy.linalg as lin
import re
data=np.array(map(lambda l: map(float,filter(lambda x: len(x)>0,re.split('\\s+',l))),open('chfdb_chf01_275.txt'))).T
dK=230
pattern=data[1,:dK]
data=data[1,dK:]
def create_mats(dat):
'''
create
A - an initial transition matrix
pA - pseudocounts for A
w - emission distribution regression weights
K - number of hidden states
'''
step=5 #adjust this to change the granularity of the pattern
eps=.1
dat=dat[::step]
K=len(dat)+1
A=np.zeros( (K,K) )
A[0,1]=1.
pA=np.zeros( (K,K) )
pA[0,1]=1.
for i in xrange(1,K-1):
A[i,i]=(step-1.+eps)/(step+2*eps)
A[i,i+1]=(1.+eps)/(step+2*eps)
pA[i,i]=1.
pA[i,i+1]=1.
A[-1,-1]=(step-1.+eps)/(step+2*eps)
A[-1,1]=(1.+eps)/(step+2*eps)
pA[-1,-1]=1.
pA[-1,1]=1.
w=np.ones( (K,2) , dtype=np.float)
w[0,1]=dat[0]
w[1:-1,1]=(dat[:-1]-dat[1:])/step
w[-1,1]=(dat[0]-dat[-1])/step
return A,pA,w,K
#initialize stuff
A,pA,w,K=create_mats(pattern)
eta=10. #precision parameter for the autoregressive portion of the model
lam=.1 #precision parameter for the weights prior
N=1 #number of sequences
M=2 #number of dimensions - the second variable is for the bias term
T=len(data) #length of sequences
x=np.ones( (T+1,M) ) # sequence data (just one sequence)
x[0,1]=1
x[1:,0]=data
#emissions
e=np.zeros( (T,K) )
#residuals
v=np.zeros( (T,K) )
#store the forward and backward recurrences
f=np.zeros( (T+1,K) )
fls=np.zeros( (T+1) )
f[0,0]=1
b=np.zeros( (T+1,K) )
bls=np.zeros( (T+1) )
b[-1,1:]=1./(K-1)
#hidden states
z=np.zeros( (T+1),dtype=np.int )
#expected hidden states
ex_k=np.zeros( (T,K) )
# expected pairs of hidden states
ex_kk=np.zeros( (K,K) )
nkk=np.zeros( (K,K) )
def fwd(xn):
global f,e
for t in xrange(T):
f[t+1,:]=np.dot(f[t,:],A)*e[t,:]
sm=np.sum(f[t+1,:])
fls[t+1]=fls[t]+np.log(sm)
f[t+1,:]/=sm
assert f[t+1,0]==0
def bck(xn):
global b,e
for t in xrange(T-1,-1,-1):
b[t,:]=np.dot(A,b[t+1,:]*e[t,:])
sm=np.sum(b[t,:])
bls[t]=bls[t+1]+np.log(sm)
b[t,:]/=sm
def em_step(xn):
global A,w,eta
global f,b,e,v
global ex_k,ex_kk,nkk
x=xn[:-1] #current data vectors
y=xn[1:,:1] #next data vectors predicted from current
#compute residuals
v=np.dot(x,w.T) # (N,K) <- (N,1) (N,K)
v-=y
e=np.exp(-eta/2*v**2,e)
fwd(xn)
bck(xn)
# compute expected hidden states
for t in xrange(len(e)):
ex_k[t,:]=f[t+1,:]*b[t+1,:]
ex_k[t,:]/=np.sum(ex_k[t,:])
# compute expected pairs of hidden states
for t in xrange(len(f)-1):
ex_kk=A*f[t,:][:,np.newaxis]*e[t,:]*b[t+1,:]
ex_kk/=np.sum(ex_kk)
nkk+=ex_kk
# max w/ respect to transition probabilities
A=pA+nkk
A/=np.sum(A,1)[:,np.newaxis]
# solve the weighted regression problem for emissions weights
# x and y are from above
for k in xrange(K):
ex=ex_k[:,k][:,np.newaxis]
dx=np.dot(x.T,ex*x)
dy=np.dot(x.T,ex*y)
dy.shape=(2)
w[k,:]=lin.solve(dx+lam*np.eye(x.shape[1]), dy)
#return the probability of the sequence (computed by the forward algorithm)
return fls[-1]
if __name__=='__main__':
#run the em algorithm
for i in xrange(20):
print em_step(x)
#get rough boundaries by taking the maximum expected hidden state for each position
r=np.arange(len(ex_k))[np.argmax(ex_k,1)<3]
#plot
plt.plot(range(T),x[1:,0])
yr=[np.min(x[:,0]),np.max(x[:,0])]
for i in r:
plt.plot([i,i],yr,'-r')
plt.show()
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-04-13 12:44:17
¿Por qué no usar un filtro emparejado simple? O su contraparte estadística general llamada correlación cruzada. Dado un patrón conocido x (t) y una serie de tiempo compuesta ruidosa que contiene su patrón desplazado en a,b,..., z como y(t) = x(t-a) + x(t-b) +...+ x(t-z) + n(t). La función de correlación cruzada entre x e y debería dar picos en a, b,..., z
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-09-27 10:02:16
Weka es una poderosa colección de software de aprendizaje automático, y es compatible con algunas herramientas de análisis de series temporales, pero no sé lo suficiente sobre el campo para recomendar un mejor método. Sin embargo, está basado en Java; y puede llamar código Java desde C/C++ sin gran alboroto.
Los paquetes para la manipulación de series temporales se dirigen principalmente al mercado de valores. Sugerí Cronos en los comentarios; no tengo idea de cómo hacer el reconocimiento de patrones con él, más allá de lo obvio: cualquier buen modelo de una longitud de su serie debe ser capaz de predecir que, después de pequeños golpes a una cierta distancia hasta el último pequeño golpe, grandes golpes siguen. Es decir, su serie exhibe auto-similitud, y los modelos utilizados en Cronos están diseñados para modelarla.
Si no le importa C#, debe solicitar una versión de TimeSearcher2 de la gente de HCIL - pattern recognition es, para este sistema, dibujar cómo se ve un patrón, y luego verificar si su modelo es general suficiente para capturar la mayoría de las instancias con una baja tasa de falsos positivos. Probablemente el enfoque más fácil de usar que encontrará; todos los demás requieren bastante experiencia en estadísticas o estrategias de reconocimiento de patrones.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-05-23 10:31:17
No estoy seguro de qué paquete funcionaría mejor para esto. Hice algo similar en un momento en la universidad donde traté de detectar automáticamente ciertas formas similares en un eje x-y para un montón de diferentes gráficos. Podrías hacer algo como lo siguiente.
Etiquetas de clase como:
- ninguna clase
- inicio de la región
- centro de la región
- fin de la región
Características como:
- eje y relativo diferencia relativa y absoluta de cada uno de la puntos circundantes en una ventana 11 puntos de ancho
- Características como diferencia del promedio
- Diferencia relativa entre el punto anterior y el punto posterior
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-08-02 18:02:01
Estoy usando deep learning si es una opción para ti. Se hace en Java, Deeplearning4j. Estoy experimentando con LSTM. Probé 1 capa oculta y 2 capas ocultas para procesar series de tiempo.
return new NeuralNetConfiguration.Builder()
.seed(HyperParameter.seed)
.iterations(HyperParameter.nItr)
.miniBatch(false)
.learningRate(HyperParameter.learningRate)
.biasInit(0)
.weightInit(WeightInit.XAVIER)
.momentum(HyperParameter.momentum)
.optimizationAlgo(
OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT // RMSE: ????
)
.regularization(true)
.updater(Updater.RMSPROP) // NESTEROVS
// .l2(0.001)
.list()
.layer(0,
new GravesLSTM.Builder().nIn(HyperParameter.numInputs).nOut(HyperParameter.nHNodes_1).activation("tanh").build())
.layer(1,
new GravesLSTM.Builder().nIn(HyperParameter.nHNodes_1).nOut(HyperParameter.nHNodes_2).dropOut(HyperParameter.dropOut).activation("tanh").build())
.layer(2,
new GravesLSTM.Builder().nIn(HyperParameter.nHNodes_2).nOut(HyperParameter.nHNodes_2).dropOut(HyperParameter.dropOut).activation("tanh").build())
.layer(3, // "identity" make regression output
new RnnOutputLayer.Builder(LossFunctions.LossFunction.MSE).nIn(HyperParameter.nHNodes_2).nOut(HyperParameter.numOutputs).activation("identity").build()) // "identity"
.backpropType(BackpropType.TruncatedBPTT)
.tBPTTBackwardLength(100)
.pretrain(false)
.backprop(true)
.build();
Encontré algunas cosas:
- LSTM o RNN es muy bueno para seleccionar patrones en series temporales.
- Probado en una serie de tiempo, y un grupo de diferentes series de tiempo. Patrón fueron elegidos fácilmente.
- También está tratando de elegir patrones no solo para uno cadencia. Si hay patrones por semana y por mes, ambos serán aprendidas por la red.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-06-14 11:17:12