¿Puede alguien dar un ejemplo de la vida real de aprendizaje supervisado y aprendizaje no supervisado?
Recientemente estudié sobre el aprendizaje supervisado y el aprendizaje no supervisado. Desde la teoría, sé que supervisado significa obtener la información de conjuntos de datos etiquetados y sin supervisión significa agrupar los datos sin etiquetas.
Pero, el problema es que siempre me confundo al identificar si el ejemplo dado es aprendizaje supervisado o aprendizaje no supervisado durante mis estudios.
¿Puede alguien por favor dar un ejemplo de la vida real?
6 answers
Aprendizaje supervisado:
- obtienes un montón de fotos con información sobre lo que hay en ellas y entrenas a un modelo para reconocer nuevas fotos
- tienes un montón de moléculas y información que son drogas y entrenas un modelo para responder si la nueva molécula es también un medicamento
Aprendizaje no supervisado:
- tienes un montón de fotos de 6 personas pero sin información sobre quién está en cuál y quieres dividir este conjunto de datos en 6 pilas, cada una con fotos de un individuo
- tienes moléculas, parte de ellas son drogas y parte no lo son pero no sabes cuáles son cuáles y quieres que el algoritmo descubra las drogas
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-10-04 21:31:34
Aprendizaje Supervisado
Esto es simple y lo habrías hecho varias veces, por ejemplo:
- Cortana o cualquier sistema automatizado de voz en su teléfono móvil entrena su voz y luego comienza a funcionar en función de esta capacitación.
- Basado en varias características (récord pasado de cara a cara, lanzamiento, lanzamiento, jugador contra jugador) WASP predice el % ganador de ambos equipos.
- Entrena tu escritura a mano en el sistema OCR y una vez entrenado, podrá para convertir sus imágenes de escritura a mano en texto (hasta cierta precisión, obviamente)
- Basado en algún conocimiento previo (cuando está soleado, la temperatura es más alta; cuando está nublado, la humedad es más alta, etc.) las aplicaciones meteorológicas predicen los parámetros para un tiempo determinado.
-
Basado en información pasada sobre spams, filtrar un nuevo correo electrónico entrante en Bandeja de entrada (normal) o Carpeta de correo no deseado (Spam)
Sistemas biométricos de asistencia o ATM etc donde entrena la máquina después un par de entradas (de su identidad biométrica - ya sea el pulgar o el iris o el lóbulo de la oreja, etc.), la máquina puede validar su entrada futura e identificarle.
Aprendizaje no supervisado
Un amigo te invita a su fiesta donde se reúnen totalmente extraños. Ahora los clasificará utilizando aprendizaje no supervisado (sin conocimiento previo) y esta clasificación puede ser en función del género, grupo de edad, vestimenta, calificación educativa o de la manera que desee. ¿Por qué este aprendizaje es diferente del Aprendizaje Supervisado? Ya que no usaste ningún conocimiento pasado / previo sobre las personas y las clasificaste "sobre la marcha".
-
La NASA descubre nuevos cuerpos celestes y los encuentra diferentes de objetos astronómicos previamente conocidos: estrellas, planetas, asteroides, agujeros negros, etc. (es decir, no tiene conocimiento sobre estos nuevos cuerpos) y los clasifica de la manera que le gustaría (distancia de la vía láctea, intensidad, fuerza gravitacional, desplazamiento rojo/azul o lo que sea)
Supongamos que usted nunca ha visto un partido de Cricket antes y por casualidad ver un video en Internet, ahora se puede clasificar a los jugadores sobre la base de diferentes criterios: Los jugadores que llevan el mismo tipo de kits están en una clase, los jugadores de un estilo están en una clase (bateadores, jugador de bolos, jardineros), o sobre la base de la mano de juego (RH vs LH) o de cualquier manera que observaría [y clasificar].
Estamos realizando una encuesta de 500 preguntas sobre la predicción del coeficiente intelectual nivel de estudiantes en una universidad. Dado que este cuestionario es demasiado grande, por lo que después de 100 estudiantes, la administración decide recortar el cuestionario a menos preguntas y para ello utilizamos algún procedimiento estadístico como PCA para recortarlo.
Espero que este par de ejemplos explique la diferencia en detalle.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-04-27 15:26:32
Aprendizaje Supervisado:
- es como aprender con un maestro
- el conjunto de datos de entrenamiento es como un maestro
- el conjunto de datos de entrenamiento se utiliza para entrenar a la máquina
Ejemplo:
Clasificación: La máquina está entrenada para clasificar algo en alguna clase.
- clasificar si un paciente tiene enfermedad o no
- clasificar si un correo electrónico es spam o no
Regresión: La máquina está entrenada para predecir algún valor como el precio, el peso o la altura.
- predecir el precio de la casa/propiedad
- predecir el precio del mercado de valores
Aprendizaje no supervisado:
- es como aprender sin un maestro
- la máquina aprende a través de la observación y encuentra estructuras en los datos
Ejemplo:
Clustering: Un problema de clustering es donde desea descubrir las agrupaciones inherentes en los datos
- como agrupar clientes por comportamiento de compra
Asociación: Un problema de aprendizaje de reglas de asociación es cuando desea descubrir reglas que describen grandes porciones de sus datos
- como las personas que compran X también tienden a comprar Y
Leer más: Algoritmos de Aprendizaje Automático Supervisados y No supervisados
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-09-08 14:51:51
Aprendizaje Supervisado
El aprendizaje supervisado es bastante común en los problemas de clasificación porque el objetivo es a menudo conseguir que la computadora aprenda un sistema de clasificación que hemos creado. El reconocimiento de dígitos, una vez más, es un ejemplo común de aprendizaje de clasificación. Más generalmente, el aprendizaje de la clasificación es apropiado para cualquier problema donde deducir una clasificación es útil y la clasificación es fácil de determinar. En algunos casos, puede que ni siquiera sea necesario dé clasificaciones predeterminadas a cada instancia de un problema si el agente puede resolver las clasificaciones por sí mismo. Este sería un ejemplo de aprendizaje no supervisado en un contexto de clasificación.
El aprendizaje supervisado es la técnica más común para entrenar redes neuronales y árboles de decisión. Ambas técnicas dependen en gran medida de la información proporcionada por las clasificaciones predeterminadas. En el caso de las redes neuronales, la clasificación se utiliza para determinar el error de la red y luego ajustar la red para minimizarlo, y en árboles de decisión, las clasificaciones se utilizan para determinar qué atributos proporcionan la mayor información que se puede utilizar para resolver el rompecabezas de clasificación. Veremos ambos con más detalle, pero por ahora, debería ser suficiente saber que ambos ejemplos prosperan en tener alguna "supervisión" en forma de clasificaciones predeterminadas.
Reconocimiento de voz usando modelos ocultos de Markov y Bayesian networks también se basa en algunos elementos de supervisión para ajustar los parámetros para, como de costumbre, minimizar el error en las entradas dadas.
Observe algo importante aquí: en el problema de clasificación, el objetivo del algoritmo de aprendizaje es minimizar el error con respecto a las entradas dadas. Estos insumos, a menudo llamados el "conjunto de entrenamiento", son los ejemplos de los cuales el agente trata de aprender. Pero aprender bien el conjunto de entrenamiento no es necesariamente lo mejor que se puede hacer. Por ejemplo, si traté de enseñarte exclusivo-or, pero solo te mostré combinaciones que consistían en un verdadero y un falso, pero nunca ambos falsos o ambos verdaderos, podrías aprender la regla de que la respuesta siempre es verdadera. Del mismo modo, con los algoritmos de aprendizaje automático, un problema común es sobreajustar los datos y esencialmente memorizar el conjunto de entrenamiento en lugar de aprender una técnica de clasificación más general.
Aprendizaje no supervisado
El aprendizaje no supervisado parece mucho más difícil: el objetivo es que la computadora aprenda a hacer algo que nosotros no le decimos cómo hacer. En realidad, hay dos enfoques para el aprendizaje no supervisado. El primer enfoque es enseñar al agente no dando categorizaciones explícitas, sino usando algún tipo de sistema de recompensa para indicar el éxito. Tenga en cuenta que este tipo de capacitación generalmente encajará en el marco del problema de decisión porque el objetivo no es producir una clasificación sino tomar decisiones que maximicen las recompensas. Este el enfoque generaliza muy bien al mundo real, donde los agentes pueden ser recompensados por hacer ciertas acciones y castigados por hacer otras.
A menudo, una forma de aprendizaje por refuerzo se puede utilizar para el aprendizaje no supervisado, donde el agente basa sus acciones en las recompensas y castigos anteriores sin necesariamente ni siquiera aprender ninguna información sobre las formas exactas en que sus acciones afectan al mundo. En cierto modo, toda esta información es innecesaria porque al aprender una función de recompensa, el agente simplemente sabe qué hacer sin ningún procesamiento porque sabe la recompensa exacta que espera lograr por cada acción que podría tomar. Esto puede ser extremadamente beneficioso en los casos en que el cálculo de cada posibilidad consume mucho tiempo (incluso si se conocieran todas las probabilidades de transición entre los Estados del mundo). Por otro lado, puede llevar mucho tiempo aprender, esencialmente, por ensayo y error.
Pero este tipo de aprendizaje puede ser poderoso porque asume que no pre-discovered classification of examples. En algunos casos, por ejemplo, nuestras clasificaciones pueden no ser las mejores posibles. Un exmaple llamativo es que la sabiduría convencional sobre el juego de backgammon se volvió en su cabeza cuando una serie de programas informáticos (neuro-gammon y TD-gammon) que aprendió a través de aprendizaje sin supervisión se hizo más fuerte que los mejores jugadores de ajedrez humanos simplemente jugando a sí mismos una y otra vez. Estos programas descubrieron algunos principios que sorprendieron al backgammon expertos y realizado mejor que los programas de backgammon entrenados en ejemplos pre-clasificados.
Un segundo tipo de aprendizaje no supervisado se llama clustering. En este tipo de aprendizaje, el objetivo no es maximizar una función de utilidad, sino simplemente encontrar similitudes en los datos de entrenamiento. La suposición es a menudo que los clústeres descubiertos coincidirán razonablemente bien con una clasificación intuitiva. Por ejemplo, la agrupación de individuos basada en datos demográficos podría resultar en una agrupación de los ricos en un grupo y los pobres en otro.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-02-10 16:39:08
El aprendizaje supervisado tiene entrada y salida correcta. Por ejemplo: Tenemos los datos si a una persona le gustó la película o no. Sobre la base de entrevistar a las personas y reunir su respuesta si les gustó la película o no, vamos a predecir si la película va a ser golpeada o no.
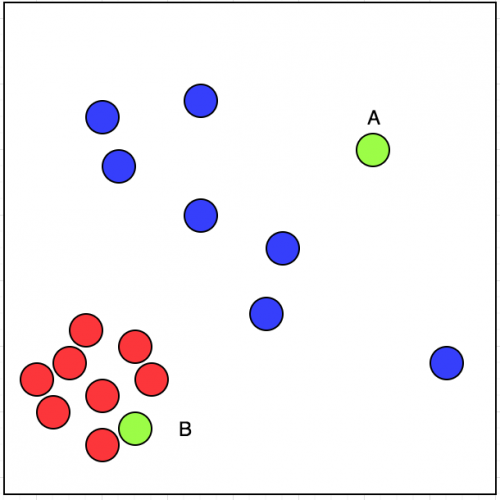
Veamos la imagen en el enlace de arriba. He visitado los restaurantes marcados con un círculo rojo. Los restaurantes que no he visitado están marcados con azul circulo.
Ahora, si tengo dos restaurantes para elegir, A y B, marcados con color verde, ¿cuál elegiré?
Simple. Podemos clasificar los datos dados linealmente en dos partes. Eso significa que podemos dibujar una línea segregando el círculo rojo y azul. Mira la imagen en el siguiente enlace:
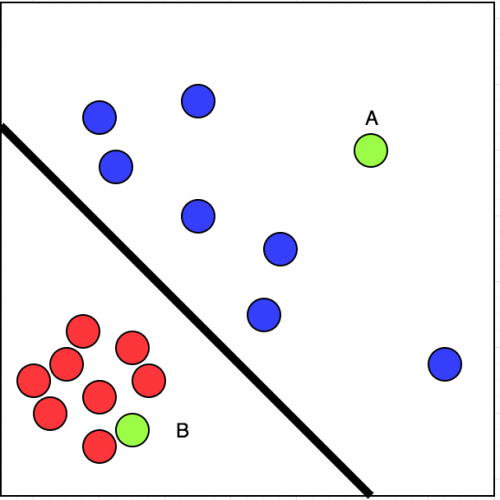
Ahora, podemos decir con cierta confianza que las posibilidades de mi visita B es más que A. Este es un caso de aprendizaje supervisado.
El aprendizaje no supervisado ha entrada. Supongamos que tenemos un taxista que tiene la opción de aceptar o rechazar las reservas. Hemos trazado su ubicación de reserva aceptada en el mapa con círculo azul y se muestra a continuación:
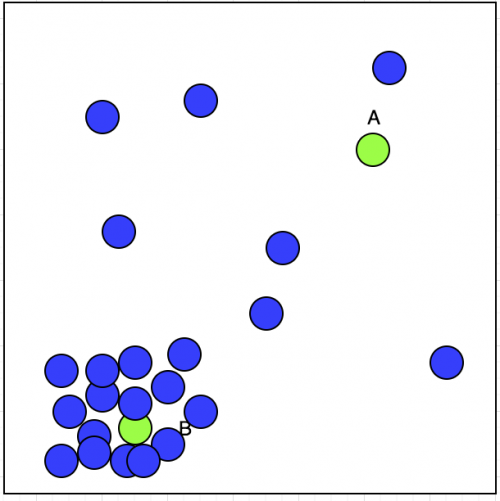
Ahora, Taxi driver tiene dos reservas A y B; ¿Cuál aceptará? Si observamos la parcela, podemos ver que su reserva aceptada muestra un grupo en la esquina inferior izquierda. Eso se puede mostrar en la imagen de abajo:
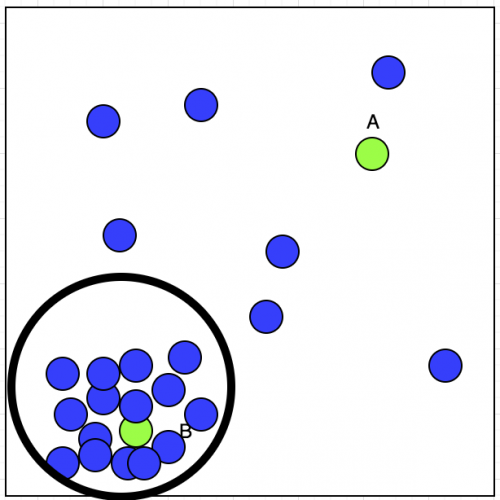
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-07-12 21:32:14
Aprendizaje Supervisado: En Términos Simples, usted tiene ciertas entradas y espera algunas salidas. Por ejemplo, usted tiene un dato del mercado de valores que es de datos anteriores y para obtener resultados de la entrada actual para los próximos años dando algunas instrucciones que puede darle la salida necesaria.
Aprendizaje no supervisado: Tiene parámetros como color, tipo, tamaño de algo y desea que un programa prediga que ya sea una fruta, planta, animal o lo que sea, aquí es donde se supervisa entra. Le da salida tomando algunas entradas.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-06-07 13:46:48