¿Por qué la velocidad de memcpy() disminuye drásticamente cada 4KB?
Probé la velocidad de memcpy() notando que la velocidad cae dramáticamente en i*4KB. El resultado es el siguiente: el eje Y es la velocidad (MB / segundo) y el eje X es el tamaño del búfer para memcpy(), aumentando de 1 KB a 2 MB. La subfigura 2 y la subfigura 3 detallan la parte de 1KB-150KB y 1KB-32KB.
Medio ambiente:
CPU: Intel(R) Xeon (R) CPU E5620 @ 2.40 GHz
OS: 2.6.35-22-generic #33-Ubuntu
Banderas del compilador GCC: - O3-msse4-DINTEL_SSE4-Wall - std = c99
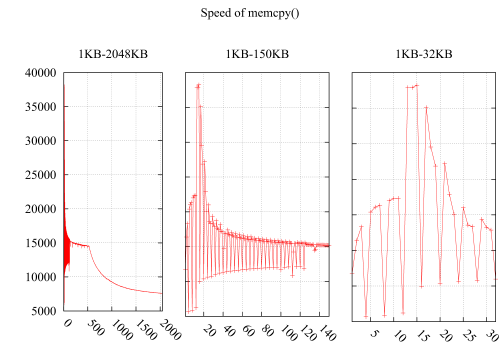
Supongo que debe estar relacionado con los cachés, pero no puedo encontrar una razón de los siguientes casos hostiles a la caché:
Dado que la degradación del rendimiento de estos dos casos son causados por bucles hostiles que leen dispersos bytes en la caché, desperdiciando el resto del espacio de una línea de caché.
Aquí está mi código:
void memcpy_speed(unsigned long buf_size, unsigned long iters){
struct timeval start, end;
unsigned char * pbuff_1;
unsigned char * pbuff_2;
pbuff_1 = malloc(buf_size);
pbuff_2 = malloc(buf_size);
gettimeofday(&start, NULL);
for(int i = 0; i < iters; ++i){
memcpy(pbuff_2, pbuff_1, buf_size);
}
gettimeofday(&end, NULL);
printf("%5.3f\n", ((buf_size*iters)/(1.024*1.024))/((end.tv_sec - \
start.tv_sec)*1000*1000+(end.tv_usec - start.tv_usec)));
free(pbuff_1);
free(pbuff_2);
}
ACTUALIZACIÓN
Considerando las sugerencias de @usr, @ChrisW y @Leeor, rehice la prueba con más precisión y el gráfico de abajo muestra los resultados. El tamaño del búfer es de 26KB a 38KB, y lo probé cada otro 64B(26KB, 26KB+64B, 26KB+128B, ......, 38KB). Cada prueba gira 100,000 veces en aproximadamente 0.15 segundos. Lo interesante es que la caída no solo se produce exactamente en 4KB límite, sino que también sale en 4 * i+2 KB, con una amplitud de caída mucho menor.
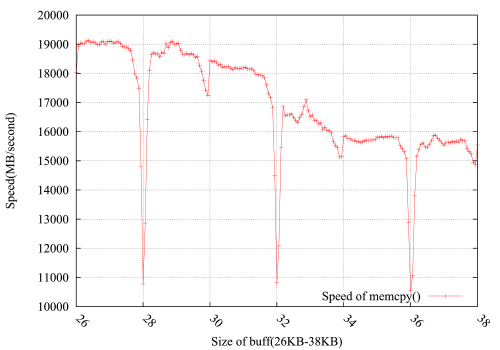
PS
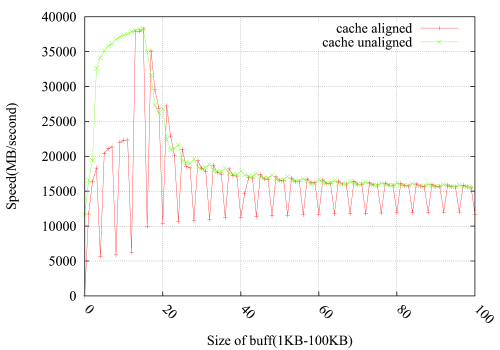
@Leeor ofreció una forma de rellenar la gota, añadiendo un búfer ficticio de 2 KB entre pbuff_1 y pbuff_2. Funciona, pero no estoy seguro de la explicación de Leeor.
3 answers
La memoria se organiza generalmente en páginas 4k (aunque también hay soporte para tamaños más grandes). El espacio de direcciones virtuales que ve su programa puede ser contiguo, pero no es necesariamente el caso en la memoria física. El sistema operativo, que mantiene una asignación de direcciones virtuales a físicas (en el mapa de páginas) generalmente intentaría mantener las páginas físicas juntas también, pero eso no siempre es posible y pueden fracturarse (especialmente en el uso prolongado donde pueden intercambiarse ocasionalmente).
Cuando su flujo de memoria cruza un límite de página 4k, la CPU necesita detenerse e ir a buscar una nueva traducción - si ya vio la página, puede estar almacenada en caché en el TLB, y el acceso está optimizado para ser el más rápido, pero si este es el primer acceso (o si tiene demasiadas páginas para que los TLBs las retengan), la CPU tendrá que detener el acceso a la memoria e iniciar un recorrido de página sobre las entradas del mapa de página-eso es relativamente largo ya que cada nivel es de hecho una memoria leída por sí misma (en las máquinas virtuales es aún más largo, ya que cada nivel puede necesitar una caminata de página completa en el host).
Su función memcpy puede tener otro problema: al asignar memoria por primera vez, el sistema operativo solo construiría las páginas en el mapa de páginas, pero las marcaría como no procesadas y sin modificar debido a optimizaciones internas. El primer acceso no solo puede invocar un recorrido de página, sino también posiblemente una ayuda que le diga al sistema operativo que la página se va a usar (y se almacena en, para las páginas de búfer de destino), lo que tomaría un transición costosa a algún controlador de sistema operativo.
Para eliminar este ruido, asigne los búferes una vez, realice varias repeticiones de la copia y calcule el tiempo amortizado. Eso, por otro lado, le daría un rendimiento "cálido" (es decir, después de haber calentado las cachés), por lo que verá que los tamaños de caché se reflejan en sus gráficos. Si desea obtener un efecto "frío" mientras no sufre de latencias de paginación, es posible que desee limpiar las cachés entre la iteración (solo asegúrese de no hacerlo tiempo que)
EDITAR
Vuelva a leer la pregunta, y parece que está haciendo una medición correcta. El problema con mi explicación es que debe mostrar un aumento gradual después de 4k*i, ya que en cada caída de este tipo se paga la penalización de nuevo, pero luego debe disfrutar del viaje gratis hasta el próximo 4k. No explica por qué hay tales "picos" y después de ellos la velocidad vuelve a la normalidad.
Creo que están enfrentándose a un problema similar al problema de la zancada crítica relacionado con su pregunta-cuando el tamaño de su búfer es un buen redondo 4k, ambos búferes se alinearán con los mismos conjuntos en la caché y se golpearán entre sí. Su L1 es 32k, por lo que no parece un problema al principio, pero suponiendo que los datos L1 tiene 8 formas, de hecho, es una envoltura 4k alrededor de los mismos conjuntos, y tiene bloques 2*4k con la misma alineación exacta (suponiendo que la asignación se hizo contiguamente) por lo que se superponen en los mismos conjuntos. Es suficiente que la LRU no funcione exactamente como esperas y seguirás teniendo conflicto.
Para comprobar esto, intentaría malloc un búfer ficticio entre pbuff_1 y pbuff_2, que sea 2k grande y espero que rompa la alineación.
EDIT2:
Ok, ya que esto funciona, es hora de elaborar un poco. Supongamos que asigna dos matrices 4k en rangos 0x1000-0x1fff y 0x2000-0x2fff. set 0 en su L1 contendrá las líneas en 0x1000 y 0x2000, set 1 contendrá 0x1040 y 0x2040, y así sucesivamente. En estos tamaños no tienes ningún problema con la paliza todavía, todos pueden coexistir sin desbordando la asociatividad del cache. Sin embargo, cada vez que realiza una iteración, tiene una carga y una tienda accediendo al mismo conjunto, supongo que esto puede causar un conflicto en el HW. Peor aún: necesitará varias iteraciones para copiar una sola línea, lo que significa que tiene una congestión de 8 cargas + 8 tiendas (menos si vectoriza, pero aún así mucho), todas dirigidas al mismo conjunto pobre, estoy bastante seguro de que hay un montón de colisiones ocultas allí.
También veo que Intel optimization guide tiene algo que decir específicamente sobre eso (ver 3.6.8.2):
El aliasing de memoria de 4-KByte se produce cuando el código accede a dos ubicaciones de memoria con un desplazamiento de 4 KByte entre ellas. El 4-KByte situación de aliasing puede manifestarse en una rutina de copia de memoria donde el las direcciones del buffer de origen y del buffer de destino mantienen un desplazamiento constante y el desplazamiento constante pasa a ser un múltiplo de el incremento de bytes de una iteración a la siguiente.
...
Las cargas tienen que esperar hasta que las tiendas se hayan retirado antes de que puedan continuar. Por ejemplo, en el desplazamiento 16, la carga de la siguiente iteración es 4-KByte aliased almacén de iteración actual, por lo tanto, el bucle debe esperar hasta que se complete la operación de la tienda, haciendo todo el bucle serializa. La cantidad de tiempo necesario para esperar disminuye con mayor offset until offset of 96 resuelve el problema (ya que no hay pendiente almacena en el momento de la carga con same dirección).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-09-30 08:02:57
Espero que sea porque:
- Cuando el tamaño del bloque es un múltiplo de 4 KB, entonces
mallocasigna nuevas páginas desde el O / S. - Cuando el tamaño del bloque no es un múltiplo de 4 KB, entonces
mallocasigna un rango desde su montón (ya asignado). - Cuando las páginas se asignan desde las O/S entonces son 'frías': tocarlas por primera vez es muy caro.
Mi conjetura es que, si haces un solo memcpy antes del primero gettimeofday entonces eso 'calentará' el asignado memoria y no verás este problema. En lugar de hacer un memcpy inicial, incluso escribir un byte en cada página de 4 KB asignada podría ser suficiente para precalentar la página.
Normalmente cuando quiero una prueba de rendimiento como la tuya la codifico como:
// Run in once to pre-warm the cache
runTest();
// Repeat
startTimer();
for (int i = count; i; --i)
runTest();
stopTimer();
// use a larger count if the duration is less than a few seconds
// repeat test 3 times to ensure that results are consistent
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-01-10 12:35:47
Dado que estás haciendo loops muchas veces, creo que los argumentos sobre las páginas que no están mapeadas son irrelevantes. En mi opinión, lo que está viendo es el efecto de hardware prefetcher no dispuesto a cruzar el límite de la página para no causar (potencialmente innecesarios) fallos de página.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-07-21 15:07:22