¿Por qué la inserción del compilador produce un código más lento que la inserción manual?
Antecedentes
El siguiente bucle crítico de una pieza de software numérico, escrito en C++, básicamente compara dos objetos por uno de sus miembros:
for(int j=n;--j>0;)
asd[j%16]=a.e<b.e;
a y b son de clase ASD:
struct ASD {
float e;
...
};
Estaba investigando el efecto de poner esta comparación en una función de barra ligera:
bool test(const ASD& y)const {
return e<y.e;
}
Y usándolo así:
for(int j=n;--j>0;)
asd[j%16]=a.test(b);
El compilador está insertando esta función, pero el problema es que el código ensamblador será diferente y causa >10% de sobrecarga de tiempo de ejecución. Tengo que preguntar:
Preguntas
¿Por qué el compilador está produciendo un código de ensamblado diferente?
¿Por qué el montaje producido es más lento?
EDITAR: La segunda pregunta ha sido respondida implementando la sugerencia de @KamyarSouri (j%16). El código de ensamblado ahora se ve casi idéntico (ver http://pastebin.com/diff.php?i=yqXedtPm ). Las únicas diferencias son las líneas 18, 33, 48:
000646F9 movzx edx,dl
Material
- El código de prueba: http://pastebin.com/03s3Kvry
- La salida de ensamblaje en MSVC10 con / Ox / Ob2 / Ot / arch: SSE2:
- Versión en línea del compilador: http://pastebin.com/yqXedtPm
- Versión en línea manual: http://pastebin.com/pYSXL77f
- Diferencia http://pastebin.com/diff.php?i=yqXedtPm
Este gráfico muestra el FLOP/s (hasta una escala factor) para 50 pruebas de mi código.
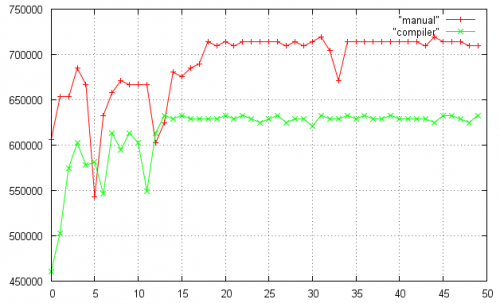
El script gnuplot para generar la trama: http://pastebin.com/8amNqya7
Opciones del compilador:
/ Zi / W3 / WX - / MP / Ox /Ob2 /Oi /Ot /Oy /GL /D "WIN32" /D "NDEBUG" /D "_CONSOLE" / D "_UNICODE" / D " UNICODE "/Gm - /EHsc /MT /GS - /Gy /arch:SSE2 /fp:precise /Zc:wchar_t /Zc:forScope /Gd / analyze-
Opciones del enlazador: / INCREMENTAL: NO HAY " kernel32.lib "" user32.lib "" gdi32.lib "" winspool.lib" "comdlg32.lib "" advapi32.lib "" shell32.lib "" ole32.lib "" oleaut32.lib "" uuid.lib "" odbc32.lib "" odbccp32.lib" /ALLOWISOLATION /MANIFESTUAC:"level='asInvoker' UIAccess='false'" /SUBSISTEMA:CONSOLE /OPT:REF /OPT:ICF /LTCG /TLBID:1 /DYNAMICBASE /NXCOMPAT /MACHINE:X86 /ERRORREPORT:QUEUE
2 answers
Respuesta corta:
Su matriz asd se declara así:
int *asd=new int[16];
Por lo tanto, use int como el tipo de retorno en lugar de bool.
Alternativamente, cambie el tipo de matriz a bool.
En cualquier caso, haga que el tipo de retorno de la función test coincida con el tipo de la matriz.
Saltar a la parte inferior para más detalles.
Respuesta larga:
En la versión en línea manual, el "núcleo" de una iteración se ve como esto:
xor eax,eax
mov edx,ecx
and edx,0Fh
mov dword ptr [ebp+edx*4],eax
mov eax,dword ptr [esp+1Ch]
movss xmm0,dword ptr [eax]
movss xmm1,dword ptr [edi]
cvtps2pd xmm0,xmm0
cvtps2pd xmm1,xmm1
comisd xmm1,xmm0
La versión en línea del compilador es completamente idéntica excepto por la primera instrucción.
Donde en lugar de:
xor eax,eax
Tiene:
xor eax,eax
movzx edx,al
Bien, entonces es una instrucción extra. Ambos hacen lo mismo: poner a cero un registro. Esta es la única diferencia que veo...
La instrucción movzx tiene una latencia de ciclo único y 0.33 ciclo de rendimiento recíproco en todas las arquitecturas más nuevas. Así que no puedo imaginar cómo esto podría hacer una diferencia del 10%.
En ambos casos, el resultado de la reducción a cero se utiliza solo 3 instrucciones más tarde. Así que es muy posible que esto podría estar en el camino crítico de la ejecución.
Aunque no soy un ingeniero de inteligencia, aquí está mi conjetura:
La mayoría de los procesadores modernos se ocupan de operaciones de reducción a cero (como xor eax,eax) a través de cambiar el nombre de registro a un banco de registros cero. Pasa por alto completamente las unidades de ejecución. Sin embargo, es posible que este un manejo especial podría causar una burbuja de canalización cuando se accede al registro (parcial) a través de movzx edi,al.
Además, también hay una false dependencia de eax en la versión inlineada del compilador:
movzx edx,al
mov eax,ecx // False dependency on "eax".
Si la ejecución fuera de orden es capaz de resolver esto está más allá de mí.
Bien, esto se está convirtiendo básicamente en una cuestión de ingeniería inversa del compilador MSVC...
Aquí voy a explicar por qué ese movzx extra se genera, así como por qué permanece.
La clave aquí es el valor devuelto bool. Aparentemente, bool los tipos de datos son probablemente como valores almacenados de 8 bits dentro de la representación interna de MSVC.
Por lo tanto, cuando se convierte implícitamente de bool a int aquí:
asd[j%16] = a.test(b);
^^^^^^^^^ ^^^^^^^^^
type int type bool
Hay una promoción de enteros de 8 bits> 32 bits. Esta es la razón por la que MSVC genera la instrucción movzx.
Cuando la inserción se realiza manualmente, el compilador tiene suficiente información para optimice esta conversión y mantenga todo como un tipo de datos IR de 32 bits.
Sin embargo, cuando el código se pone en su propia función con un valor devuelto bool, el compilador no es capaz de optimizar el tipo de datos intermedio de 8 bits. Por lo tanto, el movzx permanece.
Cuando hace que ambos tipos de datos sean iguales (ya sea int o bool), no se necesita conversión. Por lo tanto, el problema se evita por completo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-12-21 03:39:33
lea esp,[esp] ocupa 7 bytes de i-cache y está dentro del bucle. Algunas otras pistas hacen que parezca que el compilador no está seguro de si se trata de una compilación de lanzamiento o una compilación de depuración.
Editar:
El lea esp,[esp] no está en el bucle. La posición entre las instrucciones circundantes me engañó. Ahora parece que intencionalmente desperdició 7 bytes, seguido de otro desperdiciado 2 bytes, con el fin de iniciar el bucle real en un límite de 16 bytes. Lo que significa que esto realmente acelera las cosas, como se observa por Johennes Gerer.
El compilador todavía parece estar inseguro si se trata de una compilación de depuración o liberación.
Otra edición:
La diferencia de pastebin es diferente de la diferencia de pastebin que vi antes. Esta respuesta podría eliminarse ahora, pero ya tiene comentarios, así que la dejaré.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-12-21 02:12:40