Obtener la coincidencia de cadena más cercana
Necesito una forma de comparar varias cadenas con una cadena de prueba y devolver la cadena que se parece mucho a ella:
TEST STRING: THE BROWN FOX JUMPED OVER THE RED COW
CHOICE A : THE RED COW JUMPED OVER THE GREEN CHICKEN
CHOICE B : THE RED COW JUMPED OVER THE RED COW
CHOICE C : THE RED FOX JUMPED OVER THE BROWN COW
(Si hice esto correctamente) La cadena más cercana a la "CADENA DE PRUEBA" debería ser "CHOICE C". ¿Cuál es la forma más fácil de hacer esto?
Planeo implementar esto en múltiples idiomas, incluyendo VB.net, Lua y JavaScript. En este punto, pseudo código es aceptable. Si puede proporcionar un ejemplo para un idioma específico, ¡esto también es apreciado!
10 answers
Se me presentó este problema hace aproximadamente un año cuando se trataba de buscar información del usuario ingresada sobre una plataforma petrolera en una base de datos de información diversa. El objetivo era hacer algún tipo de búsqueda de cadenas difusas que pudiera identificar la entrada de la base de datos con los elementos más comunes.
Parte de la investigación consistió en implementar el algoritmo Levenshtein distance , que determina cuántos cambios se deben hacer a una cadena o frase para convertirla en otra cadena o frase. frase.
La implementación que se me ocurrió fue relativamente simple, e implicó una comparación ponderada de la longitud de las dos frases, el número de cambios entre cada frase, y si cada palabra se podía encontrar en la entrada de destino.
El artículo está en un sitio privado, así que haré todo lo posible para agregar los contenidos relevantes aquí:
La coincidencia de cadenas difusas es el proceso de realizar una estimación similar a la humana de la similitud de dos palabras o frases. En muchos casos, implica identificar palabras o frases que son más similares entre sí. Este artículo describe una solución interna al problema de coincidencia de cadenas difusas y su utilidad para resolver una variedad de problemas que nos pueden permitir automatizar tareas que anteriormente requerían la tediosa participación del usuario.
Introducción
La necesidad de hacer coincidencias de cadenas difusas surgió originalmente durante el desarrollo de la herramienta Validador del Golfo de México. Lo que existía era una base de datos de plataformas y plataformas petroleras del golfo de México, y la gente que compraba seguros nos daba información mal escrita sobre sus activos y teníamos que cotejarla con la base de datos de plataformas conocidas. Cuando había muy poca información dada, lo mejor que podíamos hacer es confiar en un asegurador para "reconocer" a la que se referían y llamar a la información adecuada. Aquí es donde esta solución automatizada es útil.
Pasé un día investigando métodos de coincidencia de cadenas difusas, y finalmente se topó con el muy útil algoritmo de distancia de Levenshtein en Wikipedia.
Aplicación
Después de leer sobre la teoría detrás de ella, implementé y encontré formas de optimizarla. Así es como se ve mi código en VBA:
'Calculate the Levenshtein Distance between two strings (the number of insertions,
'deletions, and substitutions needed to transform the first string into the second)
Public Function LevenshteinDistance(ByRef S1 As String, ByVal S2 As String) As Long
Dim L1 As Long, L2 As Long, D() As Long 'Length of input strings and distance matrix
Dim i As Long, j As Long, cost As Long 'loop counters and cost of substitution for current letter
Dim cI As Long, cD As Long, cS As Long 'cost of next Insertion, Deletion and Substitution
L1 = Len(S1): L2 = Len(S2)
ReDim D(0 To L1, 0 To L2)
For i = 0 To L1: D(i, 0) = i: Next i
For j = 0 To L2: D(0, j) = j: Next j
For j = 1 To L2
For i = 1 To L1
cost = Abs(StrComp(Mid$(S1, i, 1), Mid$(S2, j, 1), vbTextCompare))
cI = D(i - 1, j) + 1
cD = D(i, j - 1) + 1
cS = D(i - 1, j - 1) + cost
If cI <= cD Then 'Insertion or Substitution
If cI <= cS Then D(i, j) = cI Else D(i, j) = cS
Else 'Deletion or Substitution
If cD <= cS Then D(i, j) = cD Else D(i, j) = cS
End If
Next i
Next j
LevenshteinDistance = D(L1, L2)
End Function
Simple, rápido y una métrica muy útil. Usando esto, creé dos métricas separadas para evaluar la similitud de dos cadenas. A una la llamo "Valuefrase" y a otra la llamo "valueWords". Valuefrase es solo el Levenshtein distancia entre las dos frases, y valueWords divide la cadena en palabras individuales, basado en delimitadores como espacios, guiones y cualquier otra cosa que desee, y compara cada palabra entre sí, resumiendo la distancia más corta de Levenshtein que conecta dos palabras cualesquiera. Esencialmente, mide si la información en una "frase" está realmente contenida en otra, al igual que una permutación en cuanto a palabras. Pasé unos días como proyecto paralelo ideando la forma más eficiente posible de dividir una cadena basada en delimitadores.
ValueWords, Valuefrase y función Dividida:
Public Function valuePhrase#(ByRef S1$, ByRef S2$)
valuePhrase = LevenshteinDistance(S1, S2)
End Function
Public Function valueWords#(ByRef S1$, ByRef S2$)
Dim wordsS1$(), wordsS2$()
wordsS1 = SplitMultiDelims(S1, " _-")
wordsS2 = SplitMultiDelims(S2, " _-")
Dim word1%, word2%, thisD#, wordbest#
Dim wordsTotal#
For word1 = LBound(wordsS1) To UBound(wordsS1)
wordbest = Len(S2)
For word2 = LBound(wordsS2) To UBound(wordsS2)
thisD = LevenshteinDistance(wordsS1(word1), wordsS2(word2))
If thisD < wordbest Then wordbest = thisD
If thisD = 0 Then GoTo foundbest
Next word2
foundbest:
wordsTotal = wordsTotal + wordbest
Next word1
valueWords = wordsTotal
End Function
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
' SplitMultiDelims
' This function splits Text into an array of substrings, each substring
' delimited by any character in DelimChars. Only a single character
' may be a delimiter between two substrings, but DelimChars may
' contain any number of delimiter characters. It returns a single element
' array containing all of text if DelimChars is empty, or a 1 or greater
' element array if the Text is successfully split into substrings.
' If IgnoreConsecutiveDelimiters is true, empty array elements will not occur.
' If Limit greater than 0, the function will only split Text into 'Limit'
' array elements or less. The last element will contain the rest of Text.
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
Function SplitMultiDelims(ByRef Text As String, ByRef DelimChars As String, _
Optional ByVal IgnoreConsecutiveDelimiters As Boolean = False, _
Optional ByVal Limit As Long = -1) As String()
Dim ElemStart As Long, N As Long, M As Long, Elements As Long
Dim lDelims As Long, lText As Long
Dim Arr() As String
lText = Len(Text)
lDelims = Len(DelimChars)
If lDelims = 0 Or lText = 0 Or Limit = 1 Then
ReDim Arr(0 To 0)
Arr(0) = Text
SplitMultiDelims = Arr
Exit Function
End If
ReDim Arr(0 To IIf(Limit = -1, lText - 1, Limit))
Elements = 0: ElemStart = 1
For N = 1 To lText
If InStr(DelimChars, Mid(Text, N, 1)) Then
Arr(Elements) = Mid(Text, ElemStart, N - ElemStart)
If IgnoreConsecutiveDelimiters Then
If Len(Arr(Elements)) > 0 Then Elements = Elements + 1
Else
Elements = Elements + 1
End If
ElemStart = N + 1
If Elements + 1 = Limit Then Exit For
End If
Next N
'Get the last token terminated by the end of the string into the array
If ElemStart <= lText Then Arr(Elements) = Mid(Text, ElemStart)
'Since the end of string counts as the terminating delimiter, if the last character
'was also a delimiter, we treat the two as consecutive, and so ignore the last elemnent
If IgnoreConsecutiveDelimiters Then If Len(Arr(Elements)) = 0 Then Elements = Elements - 1
ReDim Preserve Arr(0 To Elements) 'Chop off unused array elements
SplitMultiDelims = Arr
End Function
Medidas de Similitud
Usando estas dos métricas, y una tercera que simplemente calcula la distancia entre dos cadenas, tengo una serie de variables que puedo ejecutar un algoritmo de optimización para lograr el mayor número de coincidencias. La coincidencia de cadenas difusas es, en sí misma, una ciencia difusa, y por lo tanto mediante la creación de métricas linealmente independientes para medir cadenas similitud, y teniendo un conjunto conocido de cadenas que deseamos que coincidan entre sí, podemos encontrar los parámetros que, para nuestros estilos específicos de cadenas, dan los mejores resultados de coincidencia difusa.
Inicialmente, el objetivo de la métrica era tener un valor de búsqueda bajo para una coincidencia exacta, y aumentar los valores de búsqueda para medidas cada vez más permutadas. En un caso poco práctico, esto era bastante fácil de definir utilizando un conjunto de permutaciones bien definidas, y la ingeniería de la fórmula final de tal manera que tenían aumentar los resultados de los valores de búsqueda según se desee.
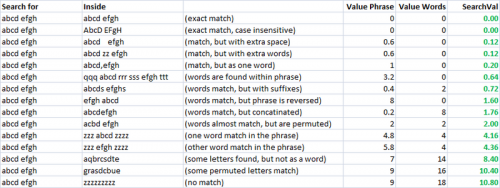
En la captura de pantalla anterior, ajusté mi heurística para llegar a algo que sentí que se ajustaba muy bien a mi diferencia percibida entre el término de búsqueda y el resultado. La heurística que utilicé para Value Phrase en la hoja de cálculo anterior fue =valuePhrase(A2,B2)-0.8*ABS(LEN(B2)-LEN(A2)). Estaba reduciendo efectivamente la penalización de la distancia de Levenstein en un 80% de la diferencia en la longitud de las dos "frases". De esta manera, las" frases " que tienen la misma longitud sufren el pleno pena, pero las "frases" que contienen "información adicional" (más larga) pero aparte de eso todavía comparten en su mayoría los mismos caracteres sufren una pena reducida. Usé la función Value Words tal como está, y luego mi heurística final SearchVal se definió como =MIN(D2,E2)*0.8+MAX(D2,E2)*0.2 - un promedio ponderado. Cualquiera de las dos puntuaciones fue menor obtuvo ponderación 80%, y 20% de la puntuación más alta. Esto era solo una heurística que se adaptaba a mi caso de uso para obtener una buena tasa de coincidencia. Estos pesos son algo que uno podría ajustar para obtener el mejor tasa de coincidencia con sus datos de prueba.
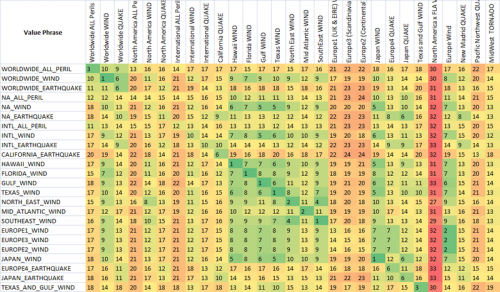
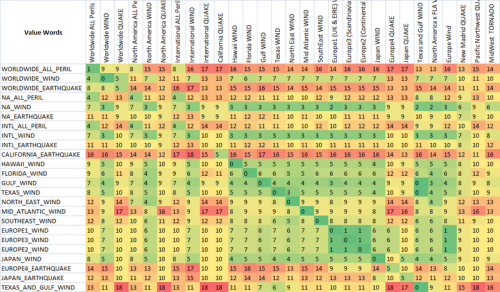
Como puede ver, las dos últimas métricas, que son métricas de coincidencia de cadenas difusas, ya tienen una tendencia natural a dar puntuaciones bajas a las cadenas que están destinadas a coincidir (en la diagonal). Esto es muy bueno.
Solicitud Para permitir la optimización de la coincidencia difusa, peso cada métrica. Como tal, cada aplicación de fuzzy string match puede ponderar los parámetros de manera diferente. La fórmula que define la puntuación final es una simple combinación de las métricas y sus pesos:
value = Min(phraseWeight*phraseValue, wordsWeight*wordsValue)*minWeight
+ Max(phraseWeight*phraseValue, wordsWeight*wordsValue)*maxWeight
+ lengthWeight*lengthValue
Usando un algoritmo de optimización (la red neuronal es mejor aquí porque es un problema discreto y multidimensional), el objetivo es ahora maximizar el número de coincidencias. He creado una función que detecta el número de coincidencias correctas de cada conjunto entre sí, como se puede ver en esta captura de pantalla final. Una columna o fila obtiene un punto si se asigna la puntuación más baja a la cadena que estaba destinada a ser emparejado, y los puntos parciales se dan si hay un empate para la puntuación más baja, y el partido correcto está entre las cadenas emparejadas empatadas. Luego lo optimicé. Puede ver que una celda verde es la columna que mejor coincide con la fila actual, y un cuadrado azul alrededor de la celda es la fila que mejor coincide con la columna actual. La puntuación en la esquina inferior es aproximadamente el número de coincidencias exitosas y esto es lo que le decimos a nuestro problema de optimización para maximizar.
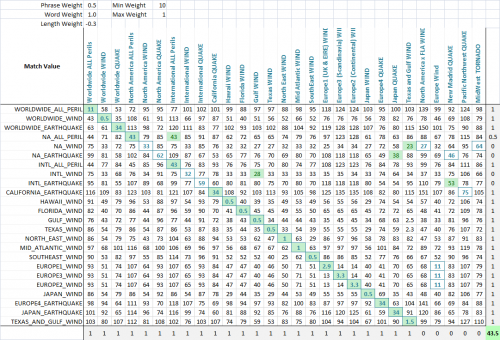
El el algoritmo fue un éxito maravilloso, y los parámetros de la solución dicen mucho sobre este tipo de problema. Notarás que la puntuación optimizada fue de 44, y la mejor puntuación posible es de 48. Las 5 columnas al final son señuelos, y no tienen ninguna coincidencia con los valores de la fila. Cuantos más señuelos haya, más difícil será encontrar la mejor pareja.
En este caso particular de coincidencia, la longitud de las cadenas es irrelevante, porque esperamos abreviaturas que representen más tiempo palabras, por lo que el peso óptimo para la longitud es -0.3, lo que significa que no penalizamos las cuerdas que varían en longitud. Reducimos la puntuación en previsión de estas abreviaturas, dando más espacio para que las coincidencias parciales de palabras sustituyan a las coincidencias que no son de palabras que simplemente requieren menos sustituciones porque la cadena es más corta.
El peso de la palabra es 1.0 mientras que el peso de la frase es solo 0.5, lo que significa que penalizamos las palabras enteras que faltan en una cadena y valoramos más la frase entera intacta. Esto es útil porque muchas de estas cadenas tienen una palabra en común (el peligro) donde lo que realmente importa es si la combinación (región y peligro) se mantienen o no.
Finalmente, el peso mínimo se optimiza a 10 y el peso máximo a 1. Lo que esto significa es que si el mejor de los dos resultados (frase de valor y palabras de valor) no es muy bueno, el partido se penaliza en gran medida, pero no penalizamos en gran medida el peor de los dos resultados. Esencialmente, esto pone énfasis en requerir ya sea la valueWord o Valuefrase para tener una buena puntuación, pero no ambas. Una especie de mentalidad de "tomar lo que podemos conseguir".
Es realmente fascinante lo que el valor optimizado de estos 5 pesos dicen sobre el tipo de coincidencia de cadena difusa que tiene lugar. Para casos prácticos completamente diferentes de coincidencia de cadenas difusas, estos parámetros son muy diferentes. Lo he usado para 3 aplicaciones separadas hasta ahora.
Mientras que no se utilizó en la optimización final, una hoja de referencia fue establecido que coincide con las columnas a sí mismos para todos los resultados perfectos en la diagonal, y permite al usuario cambiar los parámetros para controlar la velocidad a la que las puntuaciones divergen de 0, y nota similitudes innatas entre las frases de búsqueda (que en teoría podría ser utilizado para compensar los falsos positivos en los resultados)

Otras solicitudes
Esta solución tiene potencial para ser utilizada en cualquier lugar donde el usuario desee que un sistema informático identifique una cadena conjunto de cuerdas donde no hay coincidencia perfecta. (Como un vlookup de coincidencia aproximada para cadenas).
Entonces, lo que debes tomar de esto, es que probablemente quieras usar una combinación de heurística de alto nivel (encontrar palabras de una frase en la otra frase, longitud de ambas frases, etc.) junto con la implementación del algoritmo de distancia de Levenshtein. Porque decidir cuál es el "mejor" partido es una determinación heurística (difusa) - usted tendrá que llegar a un conjunto de pesos para cualquier métrica que se le ocurra para determinar la similitud.
Con el conjunto apropiado de heurísticas y pesos, tendrá su programa de comparación tomando rápidamente las decisiones que habría tomado.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-04-12 13:38:20
Este problema aparece todo el tiempo en bioinformática. La respuesta aceptada arriba (que fue genial por cierto) es conocida en bioinformática como los algoritmos Needleman-Wunsch (comparar dos cadenas) y Smith-Waterman (encontrar una subcadena aproximada en una cadena más larga). Funcionan muy bien y han sido caballos de batalla durante décadas.
¿Pero qué pasa si tienes un millón de cadenas para comparar? Eso es un trillón de comparaciones en pares, cada una de las cuales es O(n*m)! Secuenciadores de ADN modernos fácilmente generar un mil millones secuencias cortas de ADN, cada una de aproximadamente 200 "letras" de ADN de largo. Por lo general, queremos encontrar, para cada cadena de este tipo, la mejor coincidencia con el genoma humano (3 mil millones de letras). Claramente, el algoritmo Needleman-Wunsch y sus parientes no servirán.
Este llamado "problema de alineación" es un campo de investigación activa. Los algoritmos más populares son actualmente capaces de encontrar coincidencias inexactas entre 1 mil millones de cadenas cortas y el genoma humano en cuestión de horas hardware razonable (por ejemplo, ocho núcleos y 32 GB de RAM).
La mayoría de estos algoritmos funcionan encontrando rápidamente coincidencias exactas cortas (semillas) y luego extendiéndolas a la cadena completa usando un algoritmo más lento (por ejemplo, el Smith-Waterman). La razón por la que esto funciona es que realmente solo estamos interesados en unos pocos partidos cerrados, por lo que vale la pena deshacerse de la 99.9...% de pares que no tienen nada en común.
¿Cómo ayuda encontrar coincidencias exactas a encontrar coincidencias inexactas? Bien, digamos que permitimos una sola diferencia entre la consulta y el destino. Es fácil ver que esta diferencia debe ocurrir en la mitad derecha o izquierda de la consulta, por lo que la otra mitad debe coincidir exactamente. Esta idea se puede extender a múltiples desajustes y es la base para el algoritmo ELAND comúnmente utilizado con secuenciadores de ADN Illumina.
Hay muchos algoritmos muy buenos para hacer coincidencias exactas de cadenas. Dado una cadena de consulta de longitud 200, y una cadena de destino de longitud 3 mil millones (el genoma humano), queremos encontrar cualquier lugar en el objetivo donde hay una subcadena de longitud k que coincide con una subcadena de la consulta exactamente. Un enfoque simple es comenzar indexando el objetivo: tomar todas las subcadenas k-long, ponerlas en una matriz y ordenarlas. Luego tome cada subcadena k-long de la consulta y busque el índice ordenado. Ordenar y buscar se puede hacer en O(log n) tiempo.
Pero el almacenamiento puede ser un problema. Un índice del objetivo de 3 mil millones de letras tendría que contener 3 mil millones de punteros y 3 mil millones de palabras k-long. Parecería difícil encajar esto en menos de varias decenas de gigabytes de RAM. Pero sorprendentemente podemos comprimir enormemente el índice, usando la transformada de Burrows-Wheeler , y todavía será consultable de manera eficiente. Un índice del genoma humano puede caber en menos de 4 GB de RAM. Esta idea es la base de alineadores de secuencia populares como Bowtie y BWA.
Alternativamente, podemos usar un sufijo array, que almacena solo los punteros, sin embargo, representa un índice simultáneo de todos los sufijos en la cadena de destino (esencialmente, un índice simultáneo para todos los valores posibles de k; lo mismo es cierto para la transformación de Burrows-Wheeler). Un índice de matriz de sufijos del genoma humano tomará 12 GB de RAM si usamos punteros de 32 bits.
Los enlaces anteriores contienen una gran cantidad de información y enlaces a artículos de investigación primarios. El enlace de ELAND va a un PDF con figuras útiles que ilustran los conceptos involucrado, y muestra cómo lidiar con inserciones y eliminaciones.
Finalmente, mientras que estos algoritmos básicamente han resuelto el problema de (re)secuenciar genomas humanos individuales (mil millones de cadenas cortas), la tecnología de secuenciación de ADN mejora incluso más rápido que la ley de Moore, y nos estamos acercando rápidamente a conjuntos de datos de billones de letras. Por ejemplo, actualmente hay proyectos en curso para secuenciar los genomas de 10,000 especies de vertebrados, cada uno de un billón de letras de largo aproximadamente. Naturalmente, lo haremos desea hacer emparejamiento de cadena inexacta en los datos...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-05-04 09:20:44
Contesto que la opción B está más cerca de la cadena de prueba, ya que solo tiene 4 caracteres(y 2 elimina) de ser la cadena original. Mientras que usted ve C como más cerca porque incluye tanto marrón como rojo. Sin embargo, tendría una mayor distancia de edición.
Existe un algoritmo llamado Levenshtein Distance que mide la distancia de edición entre dos entradas.
Aquí es una herramienta para ese algoritmo.
- Califica la opción A como una distancia de 15.
- Califica la opción B como una distancia de 6.
- Califica la opción C como una distancia de 9.
EDITAR: Lo siento, sigo mezclando cadenas en la herramienta levenshtein. Actualizado a las respuestas correctas.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-05-02 16:46:40
Implementación de Lua, para la posteridad:
function levenshtein_distance(str1, str2)
local len1, len2 = #str1, #str2
local char1, char2, distance = {}, {}, {}
str1:gsub('.', function (c) table.insert(char1, c) end)
str2:gsub('.', function (c) table.insert(char2, c) end)
for i = 0, len1 do distance[i] = {} end
for i = 0, len1 do distance[i][0] = i end
for i = 0, len2 do distance[0][i] = i end
for i = 1, len1 do
for j = 1, len2 do
distance[i][j] = math.min(
distance[i-1][j ] + 1,
distance[i ][j-1] + 1,
distance[i-1][j-1] + (char1[i] == char2[j] and 0 or 1)
)
end
end
return distance[len1][len2]
end
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-04-27 19:32:03
Puede que te interese esta entrada de blog.
Http://seatgeek.com/blog/dev/fuzzywuzzy-fuzzy-string-matching-in-python
Fuzzywuzzy es una biblioteca de Python que proporciona medidas de distancia fáciles como la distancia de Levenshtein para la coincidencia de cadenas. Está construido sobre difflib en la biblioteca estándar y hará uso de la implementación de C Python-levenshtein si está disponible.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-05-04 03:32:50
¡Esta biblioteca te puede resultar útil! http://code.google.com/p/google-diff-match-patch /
Actualmente está disponible en Java, JavaScript, Dart, C++, C#, Objective C, Lua y Python
También funciona bastante bien. Lo uso en un par de mis proyectos de Lua.
Y no creo que sea demasiado difícil portarlo a otros idiomas!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-05-21 13:21:23
Si está haciendo esto en el contexto de un motor de búsqueda o frontend contra una base de datos, podría considerar usar una herramienta como Apache Solr, con el complemento ComplexPhraseQueryParser. Esta combinación le permite buscar contra un índice de cadenas con los resultados ordenados por relevancia, según lo determinado por la distancia de Levenshtein.
Lo hemos estado usando contra una gran colección de artistas y títulos de canciones cuando la consulta entrante puede tener uno o más errores tipográficos, y es funcionó bastante bien (y notablemente rápido teniendo en cuenta que las colecciones están en los millones de cuerdas).
Además, con Solr, puede buscar en el índice bajo demanda a través de JSON, por lo que no tendrá que reinventar la solución entre los diferentes idiomas que está mirando.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-05-04 18:21:03
Un recurso muy, muy bueno para este tipo de algoritmos es Simmetrics: http://sourceforge.net/projects/simmetrics /
Desafortunadamente el sitio web impresionante que contiene una gran cantidad de la documentación se ha ido :( En caso de que vuelva de nuevo, su dirección anterior era esta: http://www.dcs.shef.ac.uk / ~sam/simmetrics.html
Voila (cortesía de " Wayback Machine."): http://web.archive.org/web/20081230184321/http://www.dcs.shef.ac.uk/~sam/simmetrics.html
Puede estudiar el código fuente, hay docenas de algoritmos para este tipo de comparaciones, cada uno con un trade-off diferente. Las implementaciones están en Java.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-05-04 14:48:59
Para consultar un conjunto grande de texto de manera eficiente, puede usar el concepto de Editar Distancia/ Prefijo Editar Distancia.
Edit Distance ED (x, y): número mínimo de transfroms para pasar del término x al término y
Pero calcular ED entre cada término y el texto de la consulta es intensivo en recursos y tiempo. Por lo tanto, en lugar de calcular ED para cada término primero podemos extraer posibles términos coincidentes utilizando una técnica llamada Índice Qgram. y luego aplicar el cálculo ED en los términos seleccionados.
Una ventaja de la técnica de índice Qgram es que soporta la Búsqueda Difusa.
Un posible enfoque para adaptar el índice QGram es construir un Índice Invertido usando Qgrams. Allí almacenamos todas las palabras que consisten en Qgram particular, bajo ese Qgram.(En lugar de almacenar una cadena completa, puede usar un ID único para cada cadena). Puede usar la estructura de datos de mapa de árbol en Java para esto. A continuación se muestra un pequeño ejemplo sobre el almacenamiento de términos
Col : colmbia, colombo, gancola, tacolama
Luego, al realizar la consulta, calculamos el número de Qgrams comunes entre el texto de la consulta y los términos disponibles.
Example: x = HILLARY, y = HILARI(query term)
Qgrams
$$HILLARY$$ -> $$H, $HI, HIL, ILL, LLA, LAR, ARY, RY$, Y$$
$$HILARI$$ -> $$H, $HI, HIL, ILA, LAR, ARI, RI$, I$$
number of q-grams in common = 4
Número de q-gramos en común = 4.
Para los términos con un alto número de Qgrams comunes, calculamos el ED/PED contra el término de consulta y luego sugerimos el término al usuario final.
Puede encontrar una implementación de esta teoría en el siguiente proyecto (Ver "QGramIndex.Java"). Siéntase libre de hacer cualquier pregunta. https://github.com/Bhashitha-Gamage/City_Search
Para estudiar más sobre Editar Distancia, Prefijo Editar Distancia índice Qgram por favor vea el siguiente video de la Prof. Dra. Hannah Bast https://www.youtube.com/embed/6pUg2wmGJRo (La lección comienza a partir de 20: 06)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-04-03 06:30:02
El problema es difícil de implementar si los datos de entrada son demasiado grandes (digamos millones de cadenas). Usé elastic search para resolver esto. Simplemente inserte todos los datos de entrada en la base de datos y puede buscar cualquier cadena basada en cualquier distancia de edición rápidamente. Aquí hay un fragmento de C# que le dará una lista de resultados ordenados por distancia de edición (menor a mayor)
var res = client.Search<ClassName>(s => s
.Query(q => q
.Match(m => m
.Field(f => f.VariableName)
.Query("SAMPLE QUERY")
.Fuzziness(Fuzziness.EditDistance(5))
)
));
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-05-12 14:13:13