¿La forma más rápida y flexible de trazar más de 2 millones de filas de datos de archivos planos?
Estoy recopilando algunos datos del sistema en un archivo plano, que tiene este formato:
YYYY-MM-DD-HH24:MI:SS DD1 DD2 DD3 DD4
Donde DD1-DD4 son cuatro elementos de datos. Un ejemplo del archivo es este:
2011-02-01-13:29:53 16 8 7 68
2011-02-01-13:29:58 13 8 6 110
2011-02-01-13:30:03 26 25 1 109
2011-02-01-13:30:08 13 12 1 31
2011-02-01-13:30:14 192 170 22 34
2011-02-01-13:30:19 16 16 0 10
2011-02-01-13:30:24 137 61 76 9
2011-02-01-13:30:29 452 167 286 42
2011-02-01-13:30:34 471 177 295 11
2011-02-01-13:30:39 502 192 309 10
El archivo tiene más de 2 millones de filas, con puntos de datos cada cinco segundos.
Necesito trazar estos datos para poder derivar significado de ellos.
Lo que he intentado
Por el momento he probado gnuplot y rrdtool con una variedad de herramientas unix (awk, sed, etc). Ambos funcionan, pero parece requerir una gran cantidad de cortar y volver a cortar los datos cada vez que quiero verlo de una manera diferente. Mi intuición es que rrdtool es el camino correcto, pero en este momento estoy luchando para obtener los datos lo suficientemente rápido, en parte porque tengo que convertir mi marca de tiempo en Unix epoch. Mi entendimiento es también que si decido que quiero una nueva granularidad de agregación tengo que reconstruir el rrd (lo cual tiene sentido para la colección en tiempo real, pero no para cargas retrospectivas como esta). Estas cosas me hace pensar que tal vez estoy usando la herramienta equivocada.
La recopilación de los datos en el archivo plano es fija - por ejemplo, no puedo canalizar la colección directamente a rrdtool.
Mi Pregunta
Me gustaría conocer las opiniones de la gente sobre la mejor manera de hacer gráficos. Tengo estos requisitos:
- Debería ser lo más rápido posible crear un gráfico (no solo renderizar, sino también configurarlo para renderizar)
- Debería ser lo más flexible posible-necesito revolcarme con los gráficos para trabajar la mejor granularidad para los datos (5 segundos es probablemente demasiado granular)
- Debe ser capaz de agregar (MAX/AVG/etc) cuando sea necesario
- Debe ser repetible y nuevos archivos de datos como vienen en
- Idealmente quiero poder superponer DD1 vs DD2, o DD1 la semana pasada con DD1 esta semana
- Unix o Windows, no les importa. Prefiera * nix aunque: -)
Alguna sugerencia?
3 answers
Esta es una muy buena pregunta. Me alegro de ver a algunos R gente pesando en. Yo también creo que R es la herramienta adecuada para el trabajo, aunque es mi martillo principal por lo que todo se parece un poco a un clavo para mí.
Hay un puñado de conceptos R necesarios para hacer frente a este desafío. Como yo lo veo, usted necesita lo siguiente (referencias en los párrafos):
- Importar datos a R. (R Import Export Guide)
- Obtener los Datos en una estructura de serie de tiempo apropiada. (XTS Viñeta PDF)
- Un poco de trazado. (Quick-R intro to graphics )
Aquí está el código de ejemplo usando puntos de 2mm. Si te das cuenta, no ilustro el trazado de todos los puntos de 2 mm. Es lento y no informativo. Pero esto debería darte algunas ideas para empezar. ¡Siéntase libre de volver con preguntas más específicas si decide saltar por la madriguera del conejo R!
require( xts )
require( lubridate )
## set up some example data
dataLength <- 2e6
startTime <- ymd_hms("2011-02-01-13-29-53")
fistFullOfSeconds <- 1:dataLength
date <- startTime + fistFullOfSeconds
DD1 <- rnorm( dataLength )
DD2 <- DD1 + rnorm(dataLength, 0, .1 )
DD3 <- rnorm( dataLength, 10, 2)
DD4 <- rnorm( dataLength )
myXts <- xts(matrix( c( DD1, DD2, DD3, DD4 ), ncol=4 ), date)
## now all the data are in the myXts object so let's do some
## summarizing and visualization
## grabbing just a single day from the data
## converted to data.frame to illustrate default data frame plotting
oneDay <- data.frame( myXts["2011-02-02"] )
plot( oneDay )
La relación entre DD1 y DD2 salta un poco fuera
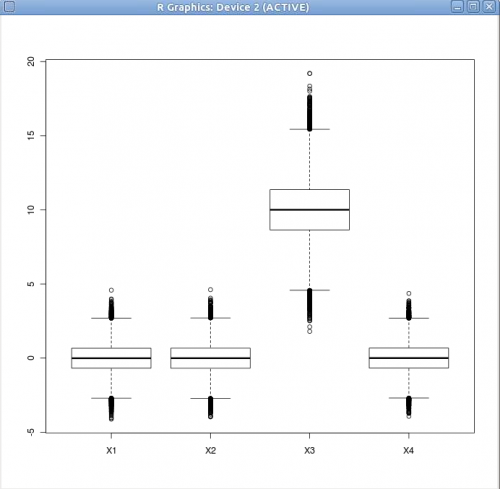
boxplot( oneDay )
Boxplot es el piechart de gráficos estadísticos. La trama que amas odiar. Bien podría enlazar a esto mientras estamos aquí.
{kind=link}
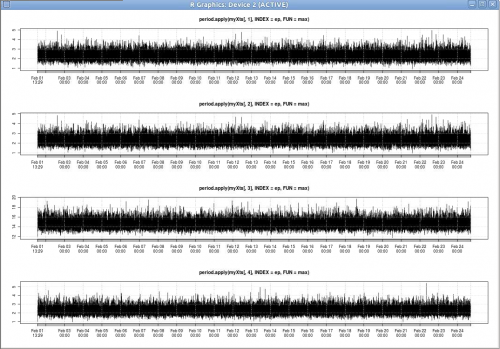
## look at the max value of each variable every minute
par(mfrow=c(4,1)) ## partitions the graph window
ep <- endpoints(myXts,'minutes')
plot(period.apply(myXts[,1],INDEX=ep,FUN=max))
plot(period.apply(myXts[,2],INDEX=ep,FUN=max))
plot(period.apply(myXts[,3],INDEX=ep,FUN=max))
plot(period.apply(myXts[,4],INDEX=ep,FUN=max))
Incluso con una resolución de un minuto no estoy seguro de que esto sea informativo. Probablemente debería subconjunto.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-02-25 19:42:57
Aquí hay un código R para jugar con 8000000 números en 4 columnas de 2000000 filas:
> d=matrix(runif(8000000),ncol=4)
> dim(d)
[1] 2000000 4
> plot(d[1:1000,1])
> plot(d[1:1000,1],type='l')
> plot(d[1:10000,1],type='l')
Ahora empieza a ser un poco lento:
> plot(d[1:100000,1],type='l')
¿Qué pasa con la correlación de dos columnas:
> cor(d[,1],d[,2])
[1] 0.001708502
Instant instantáneo. ¿Transformada de Fourier?
> f=fft(d[,1])
También instantáneo. Sin embargo, no intentes tramarlo.
Vamos a trazar una versión reducida de una de las columnas:
> plot(d[seq(1,2000000,len=1000),1],type='l')
Instant instantáneo.
Lo que realmente falta es una trama interactiva donde se puede hacer zoom y pan alrededor de todo el conjunto de datos.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-02-25 19:18:17
Aquí hay un ejemplo a lo largo de las líneas de los datos que tiene, como cargados en R, agregados, etc...
Primero, algunos datos ficticios para escribir en un archivo:
stime <- as.POSIXct("2011-01-01-00:00:00", format = "%Y-%d-%m-%H:%M:%S")
## dummy data
dat <- data.frame(Timestamp = seq(from = stime, by = 5, length = 2000000),
DD1 = sample(1:1000, replace = TRUE),
DD2 = sample(1:1000, replace = TRUE),
DD3 = sample(1:1000, replace = TRUE),
DD4 = sample(1:1000, replace = TRUE))
## write it out
write.csv(dat, file = "timestamp_data.txt", row.names = FALSE)
Entonces podemos cronometrar la lectura en los 2 millones de filas. Para acelerar esto, le decimos a R las clases de las columnas en el archivo: "POSIXct" es una forma en R de almacenar el tipo de marcas de tiempo que tiene.
## read it in:
system.time({
tsdat <- read.csv("timestamp_data.txt", header = TRUE,
colClasses = c("POSIXct",rep("integer", 4)))
})
Que, toma alrededor de 13 segundos para leer y formatear en tiempos internos de unix en mi modesta laptop.
user system elapsed
13.698 5.827 19.643
La agregación se puede hacer de muchas maneras, una es usar aggregate(). Decir agregado a la hora media/media:
## Generate some indexes that we'll use the aggregate over
tsdat <- transform(tsdat,
hours = factor(strftime(tsdat$Timestamp, format = "%H")),
jday = factor(strftime(tsdat$Timestamp, format = "%j")))
## compute the mean of the 4 variables for each minute
out <- aggregate(cbind(Timestamp, DD1, DD2, DD3, DD4) ~ hours + jday,
data = tsdat, FUN = mean)
## convert average Timestamp to a POSIX time
out <- transform(out,
Timestamp = as.POSIXct(Timestamp,
origin = ISOdatetime(1970,1,1,0,0,0)))
Que (la línea que crea out) toma ~16 segundos en mi computadora portátil, y da la siguiente salida:
> head(out)
hours jday Timestamp DD1 DD2 DD3 DD4
1 00 001 2010-12-31 23:29:57 500.2125 491.4333 510.7181 500.4833
2 01 001 2011-01-01 00:29:57 516.0472 506.1264 519.0931 494.2847
3 02 001 2011-01-01 01:29:57 507.5653 499.4972 498.9653 509.1389
4 03 001 2011-01-01 02:29:57 520.4111 500.8708 514.1514 491.0236
5 04 001 2011-01-01 03:29:57 498.3222 500.9139 513.3194 502.6514
6 05 001 2011-01-01 04:29:57 515.5792 497.1194 510.2431 496.8056
El trazado simple se puede lograr usando la función plot():
plot(DD1 ~ Timestamp, data = out, type = "l")
Podemos superponer más variables a través de, por ejemplo:
ylim <- with(out, range(DD1, DD2))
plot(DD1 ~ Timestamp, data = out, type = "l", ylim = ylim)
lines(DD2 ~ Timestamp, data = out, type = "l", col = "red")
O a través de múltiples paneles:
layout(1:2)
plot(DD1 ~ Timestamp, data = out, type = "l", col = "blue")
plot(DD2 ~ Timestamp, data = out, type = "l", col = "red")
layout(1)
Todo esto se ha hecho con la funcionalidad base R. Otros han mostrado cómo los paquetes de complementos pueden hacer que trabajar con fechas sea más fácil.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-02-25 20:54:11