¿hay una ventaja para varchar (500) sobre varchar(8000)?
He leído sobre esto en los foros de MSDN y aquí y todavía no estoy claro. Creo que esto es correcto: Varchar (max) se almacenará como un tipo de datos de texto, por lo que tiene inconvenientes. Así que digamos que su campo será fiable bajo 8000 caracteres. Como un campo BusinessName en mi tabla de base de datos. En realidad, un nombre comercial probablemente siempre estará bajo (sacando un número de mi sombrero) 500 caracteres. Parece que un montón de campos de varchar con los que me encuentro caen muy por debajo del conteo de personajes de 8k.
Entonces, ¿debo hacer que ese campo sea un varchar(500) en lugar de varchar(8000)? Por lo que entiendo de SQL no hay diferencia entre esos dos. Por lo tanto, para hacer la vida más fácil, me gustaría definir todos mis campos varchar como varchar(8000). ¿Tiene algún inconveniente?
Relacionado: Tamaño de las columnas varchar (No sentí que esta respondiera a mi pregunta).
5 answers
Desde el punto de vista del procesamiento, no hará ninguna diferencia usar varchar(8000) vs varchar(500). Es más de una "buena práctica" tipo de cosa para definir una longitud máxima que un campo debe contener y hacer que su varchar esa longitud. Es algo que se puede utilizar para ayudar con la validación de datos. Por ejemplo, hacer que una abreviatura estatal sea de 2 caracteres o un código postal como 5 o 9 caracteres. Esta solía ser una distinción más importante para cuando sus datos interactuaban con otros sistemas o interfaces de usuario donde la longitud del campo era crítica (por ejemplo, un conjunto de datos de archivo plano de mainframe), pero hoy en día creo que es más habitual que cualquier otra cosa.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-01-05 22:53:41
Un ejemplo en el que esto puede marcar la diferencia es que puede evitar una optimización del rendimiento que evite agregar información de versionado de filas a tablas con disparadores after.
Esto está cubierto por SQL Kiwi aquí
El tamaño real de los datos almacenados es inmaterial-es el potencial el tamaño que importa.
Del mismo modo, si se utilizan tablas optimizadas para memoria desde 2016, ha sido posible usar columnas LOB o combinaciones de columnas anchos que potencialmente podrían exceder el límite de inrow pero con una penalización.
(Max) las columnas siempre se almacenan fuera de la fila. Para otras columnas, si el tamaño de la fila de datos en la definición de la tabla puede superar los 8.060 bytes, SQL Server envía las columnas de longitud variable más grandes fuera de la fila. Una vez más, no depende de la cantidad de datos que almacena allí.
Esto puede tener un gran efecto negativo en el consumo de memoria y el rendimiento
Otro caso donde más declarar anchos de columna puede hacer una gran diferencia es si la tabla alguna vez será procesada usando SSIS. La memoria asignada para columnas de longitud variable (no BLOB) se fija para cada fila en un árbol de ejecución y es por la longitud máxima declarada de las columnas, lo que puede conducir al uso ineficiente de búferes de memoria (ejemplo). Si bien el desarrollador de paquetes SSIS puede declarar un tamaño de columna más pequeño que el de la fuente, este análisis se hace mejor por adelantado y se aplica allí.
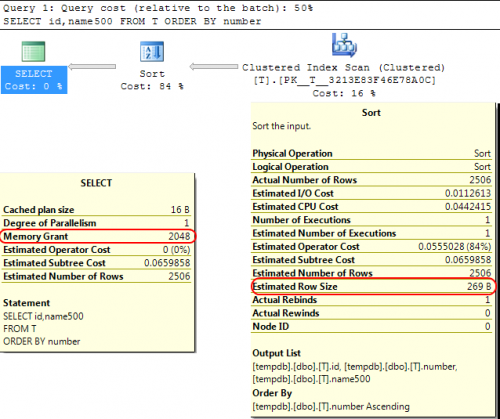
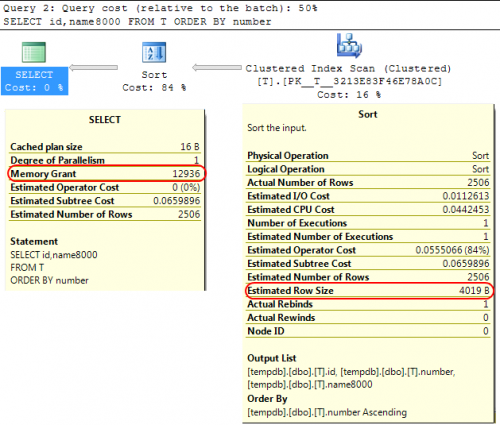
De vuelta en SQL Un caso similar es que al calcular la concesión de memoria a asignar para las operaciones SORT SQL Server asume que las columnas varchar(x) consumirán en promedio x/2 bytes.
Si la mayoría de sus columnas varchar están más llenas que eso, esto puede llevar a que las operaciones sort se extiendan a tempdb.
En su caso, si sus columnas varchar se declaran como 8000 bytes, pero en realidad tienen un contenido mucho menor que el que su consulta se asignará memoria que no requiere que es obviamente ineficiente y puede dar lugar a esperas por concesiones de memoria.
Esto se cubre en la Parte 2 de SQL Workshops Webcast 1 descargable desde aquí o ver a continuación.
use tempdb;
CREATE TABLE T(
id INT IDENTITY(1,1) PRIMARY KEY,
number int,
name8000 VARCHAR(8000),
name500 VARCHAR(500))
INSERT INTO T
(number,name8000,name500)
SELECT number, name, name /*<--Same contents in both cols*/
FROM master..spt_values
SELECT id,name500
FROM T
ORDER BY number
SELECT id,name8000
FROM T
ORDER BY number
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-01-29 21:15:31
Aparte de las mejores prácticas (respuesta de BBlake)
- Recibe advertencias sobre el tamaño máximo de fila (8060) bytes y el ancho del índice (900 bytes) con DDL
- DML morirá si excede estos límites
- El RELLENO ANSI activado es el predeterminado, por lo que podría terminar almacenando una carga completa de espacios en blanco
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-01-05 22:58:10
Hay algunas desventajas para las columnas grandes que son un poco menos obvias y podrían atraparte un poco más tarde:
- Todas las columnas que utilice en un INDEX - no deben exceder los 900 bytes
- Todas las columnas en un ORDEN POR la cláusula no pueden exceder 8060 bytes. Esto es un poco difícil de entender ya que esto solo se aplica a algunas columnas. Ver Límite de tamaño de fila de SQL 2008 R2 superado para más detalles)
- Si el tamaño total de la fila supera los 8060 bytes, se obtiene un "page spill " para esa fila. Esto podría afectar el rendimiento (Una página es una unidad de asignación en SQLServer y se fija en 8000 bytes+algo de sobrecarga. Exceder esto no será severo, pero es notorio y debe tratar de evitarlo si puede fácilmente)
- Muchas otras estructuras de datos internas, búferes y, por último, no menos importante, sus propias variables y variables de tabla necesitan reflejar estos tamaños. Con tamaños excesivos, la asignación de memoria excesiva puede afectar rendimiento
Como regla general, trate de ser conservador con el ancho de la columna. Si se convierte en un problema, puede expandirlo fácilmente para satisfacer las necesidades. Si nota problemas de memoria más tarde, reducir una columna ancha más tarde puede ser imposible sin perder datos y no sabrá por dónde comenzar.
En su ejemplo de los nombres comerciales, piense en dónde puede mostrarlos. Hay realmente espacio para 500 caracteres?? Si no, no tiene mucho sentido almacenarlos como tales. http://en.wikipedia.org/wiki/List_of_companies_of_the_United_States enumera algunos nombres de empresas y el máximo es de aproximadamente 50 caracteres. Así que usaría 100 para la columna max. Tal vez más como 80.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-05-23 11:54:56
Lo ideal sería ir más pequeño que eso, hasta una longitud de tamaño razonable (500 no es de tamaño razonable) y asegurarse de que la validación del cliente detecta cuando los datos van a ser demasiado grandes y enviar un error útil.
Mientras que el varchar en realidad no va a reservar espacio en la base de datos para el espacio no utilizado, recuerdo versiones de SQL Server que tienen un snit sobre filas de base de datos que son más anchas que un cierto número de bytes (no recuerdo el recuento exacto) y en realidad tirar lo que los datos no encajaban. Un cierto número de esos bytes estaban reservados para cosas internas de SQL Server.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-01-05 22:53:01