Estimación del número de neuronas y el número de capas de una red neuronal artificial [cerrado]
Estoy buscando un método para calcular el número de capas y el número de neuronas por capa. Como entrada solo tengo el tamaño del vector de entrada, el tamaño del vector de salida y el tamaño del conjunto trainig.
Por lo general, la mejor red se determina probando diferentes topologías de red y seleccionando la que tenga el menor error. Desafortunadamente no puedo hacer eso.
3 answers
Este es un problema muy difícil.
Cuanta más estructura interna tenga una red, mejor representará las soluciones complejas. Por otro lado, demasiada estructura interna es más lenta, puede causar que el entrenamiento diverja o conduzca a un sobreajuste, lo que evitaría que su red se generalice bien a nuevos datos.
La gente tradicionalmente ha abordado este problema de varias maneras diferentes:
Pruebe diferentes configuraciones, vea qué funciona mejor. Puedes dividir tu conjunto de entrenamiento en dos partes one una para entrenamiento, otra para evaluación and y luego entrenar y evaluar diferentes enfoques. Desafortunadamente, parece que en su caso este enfoque experimental no está disponible.
Usa una regla general. Muchas personas han llegado con un montón de conjeturas en cuanto a lo que funciona mejor. En cuanto al número de neuronas en la capa oculta, la gente ha especulado que (por ejemplo) debería (a) estar entre el tamaño de la capa de entrada y salida, (b) establecido en algo cercano (entradas+salidas) * 2/3, o (c) nunca más grande que el doble del tamaño de la capa de entrada.
El problema con las reglas empíricas es que no siempre tienen en cuenta piezas vitales de información, por ejemplo, cuán "difícil" es el problema, cuál es el tamaño de los conjuntos de entrenamiento y pruebas, etc. En consecuencia, estas reglas se utilizan a menudo como puntos de partida aproximados para el "probemos un montón de cosas y veamos qué funciona mejor".Utilice un algoritmo que ajuste dinámicamente la configuración de red.Algoritmos como Correlación en cascada comienzan con una red mínima, luego agregan nodos ocultos durante el entrenamiento. Esto puede hacer que su configuración experimental sea un poco más simple, y (en teoría) puede resultar en un mejor rendimiento (porque no usará accidentalmente un número inapropiado de nodos ocultos).
Hay un mucha investigación sobre este tema so así que si estás realmente interesado, hay mucho que leer. Echa un vistazo a las citas en este resumen , en particular:
Lawrence, S., Giles, C. L., and Tsoi, A. C. (1996), "¿Qué tamaño de red neuronal da una generalización óptima? Convergence properties of backpropagation " . Informe Técnico UMIACS-TR-96-22 y CS-TR-3617, Institute for Advanced Computer Studies, University of Maryland, College Parque.
Elisseeff, A., y Paugam-Moisy, H. (1997), "Tamaño de las redes multicapa para el aprendizaje exacto: enfoque analítico". Advances in Neural Information Processing Systems 9, Cambridge, MA: The MIT Press, pp.162-168.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-07-27 16:30:25
En la práctica, esto no es difícil (basado en haber codificado y entrenado docenas de MLPs).
En un sentido de libro de texto, obtener la arquitectura "correcta" es difícil i es decir, ajustar su arquitectura de red de tal manera que el rendimiento (resolución) no se puede mejorar mediante una mayor optimización de la arquitectura es difícil, estoy de acuerdo. Pero solo en casos raros se requiere ese grado de optimización.
En la práctica, para cumplir o exceder la precisión de predicción de una red neuronal requerida por su spec, casi nunca necesita pasar mucho tiempo con la arquitectura de red three tres razones por las que esto es cierto:
la mayoría de los parámetros necesarios para especificar la arquitectura de red son fixe d una vez que haya decidido sobre su modelo de datos (número de características en el vector de entrada, si la variable de respuesta deseada es numérico o categórico, y si este último, ¿cuántos clase única etiquetas que has elegido);
-
Los pocos que quedan parámetros de arquitectura que son de hecho sintonizables, están casi siempre (100% de las veces en mi experiencia) muy restringidos por esas arquitecturas fijas parameters the i. e., the values of those parameters are tightly bounded by a max and min value; and
La arquitectura óptima no tiene que ser determinada antes el entrenamiento comienza, de hecho, es muy común que el código de red neuronal incluye un pequeño módulo para ajustar la red mediante programación arquitectura durante entrenamiento (eliminando nodos cuyos valores de peso se están acercando a cero usually generalmente llamado " poda.")
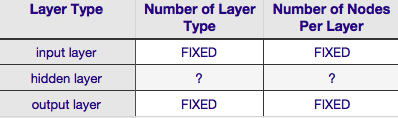
De acuerdo con la Tabla anterior, la arquitectura de una red neuronal está completamente especificada por seis parámetros (las seis celdas en la rejilla interior). Dos de ellos (número de tipo de capa para las capas de entrada y salida) son siempre uno y uno networks las redes neuronales tienen una sola capa de entrada y una sola capa de salida. Su NN debe tener al menos una capa de entrada y una capa de salida no ni más, ni menos. En segundo lugar, el número de nodos que comprenden cada una de esas dos capas es fijo the la capa de entrada, por el tamaño del vector de entrada i es decir, el número de nodos en la capa de entrada es igual a la longitud del vector de entrada (en realidad, casi siempre se agrega una neurona más a la capa de entrada como un nodo de sesgo ).
De manera similar, el tamaño de la capa de salida se fija mediante la variable response (nodo único para respuesta numérica variable, y (suponiendo que se use softmax, si la variable de respuesta es una etiqueta de clase, el número de nodos en la capa de salida simplemente es igual al número de etiquetas de clase únicas).
Eso deja solo dos parámetros para los que hay alguna discreción all el número de capas ocultas y el número de nodos que comprenden cada una de esas capas.
El Número de Capas Ocultas
Si sus datos son linealmente separables (lo que a menudo sabe cuando comience a codificar un NN) entonces no necesita ninguna capa oculta en absoluto. (Si ese es de hecho el caso, no usaría un NN para este problema choose elija un clasificador lineal más simple). La primera de ellas the el número de capas ocultas nearly es casi siempre una. Hay mucho peso empírico detrás de esta presunción in en la práctica muy pocos problemas que no se pueden resolver con una sola capa oculta se vuelven solubles agregando otra capa oculta. Del mismo modo, hay un consenso es la diferencia de rendimiento de adición de capas ocultas adicionales: las situaciones en las que el rendimiento mejora con una segunda (o tercera, etc.) capa oculta son muy pequeños. Una capa oculta es suficiente para la gran mayoría de los problemas.
En su pregunta, mencionó que, por cualquier razón, no puede encontrar la arquitectura de red óptima mediante prueba y error. Otra forma de ajustar su configuración de NN (sin usar prueba y error) es 'pruning'. La esencia de esta técnica es la eliminación de los nodos de la red durante la formación mediante la identificación de los nodos que, si se elimina de la red, no afectaría notablemente el rendimiento de la red (es decir, la resolución de los datos). (Incluso sin usar una técnica formal de poda, puede tener una idea aproximada de qué nodos no son importantes mirando su matriz de peso después del entrenamiento; busque pesos muy cercanos a cero--son los nodos en cada extremo de esos pesos que a menudo se eliminan durante la poda.) Obviamente, si se utiliza un algoritmo de poda durante el entrenamiento luego comienza con una configuración de red que es más probable que tenga nodos de exceso (es decir, 'podables') in en otras palabras, al decidir sobre una arquitectura de red, errar del lado de más neuronas, si agrega un paso de poda.
Dicho de otra manera, al aplicar un algoritmo de poda a su red durante el entrenamiento, puede estar mucho más cerca de una configuración de red optimizada de lo que cualquier teoría a priori es probable que le dé.
El Número de Nodos Que Componen el Oculto Layer
Pero ¿qué pasa con el número de nodos que componen la capa oculta? Concedido este valor es más o menos espontáneas, es decir, puede ser mayor o menor que el tamaño de la capa de entrada. Más allá de eso, como probablemente sabes, hay una montaña de comentarios sobre la cuestión de la configuración de capas ocultas en NNs (ver el famoso NN FAQ para un excelente resumen de ese comentario). Hay muchas reglas empíricas derivadas, pero de éstas, la más comúnmente utilizada es el tamaño de la capa oculta se encuentra entre las capas de entrada y salida. Jeff Heaton, autor de" Introducción a las Redes Neuronales en Java " ofrece algunos más, que se recitan en la página a la que acabo de enlazar. Del mismo modo, un escaneo de la literatura de redes neuronales orientada a aplicaciones, casi con certeza revelará que el tamaño de la capa oculta suele ser entre los tamaños de capa de entrada y salida. Pero entre no significa en el medio; de hecho, es por lo general, es mejor establecer el tamaño de la capa oculta más cerca del tamaño del vector de entrada. La razón es que si la capa oculta es demasiado pequeña, la red podría tener dificultades para convergir. Para la configuración inicial, err en el tamaño más grande a una capa oculta más grande le da a la red más capacidad que le ayuda a converger, en comparación con una capa oculta más pequeña. De hecho, esta justificación se usa a menudo para recomendar un tamaño de capa oculto mayor que (más nodos) la capa de entrada ie es decir, comience con una arquitectura inicial que fomentará la convergencia rápida, después de la cual puede podar los nodos 'excedentes' (identificar los nodos en la capa oculta con valores de peso muy bajos y eliminarlos de su red re-factorizada).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-07-15 13:42:30
He usado un MLP para un software comercial que tiene solo una capa oculta que tiene solo un nodo. Como los nodos de entrada y los nodos de salida son fijos, solo tuve que cambiar el número de capas ocultas y jugar con la generalización lograda. Realmente nunca obtuve una gran diferencia en lo que estaba logrando con solo una capa oculta y un nodo al cambiar el número de capas ocultas. Solo usé una capa oculta con un nodo. Funcionó bastante bien y también redujo los cálculos eran muy tentador en mi premisa de software.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-09-10 14:11:57