Entendiendo " aleatoriedad"
No puedo entender esto, ¿que es más aleatorio?
rand()
O
rand() * rand()
Me parece un verdadero desafío para la mente, ¿podría ayudarme?
EDITAR:
Intuitivamente sé que la respuesta matemática será que son igualmente aleatorios, pero no puedo evitar pensar que si "ejecutas el algoritmo de números aleatorios" dos veces cuando multiplicas los dos juntos crearás algo más aleatorio que solo hacerlo una vez.
28 answers
Solo una aclaración
Aunque las respuestas anteriores son correctas cada vez que intenta detectar la aleatoriedad de una variable pseudo-aleatoria o su multiplicación, debe tener en cuenta que mientras Random() generalmente se distribuye uniformemente, Random() * Random() no lo es.
Ejemplo
Esta es una muestra de distribución aleatoria uniforme simulada a través de una variable pseudo-aleatoria:
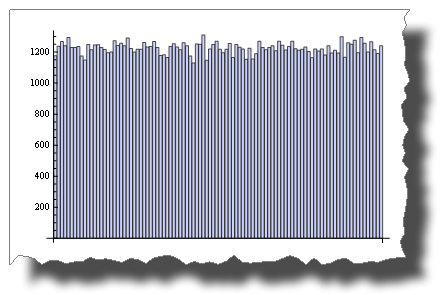
BarChart[BinCounts[RandomReal[{0, 1}, 50000], 0.01]]
Mientras que esta es la distribución se obtiene después de multiplicar dos variables aleatorias:
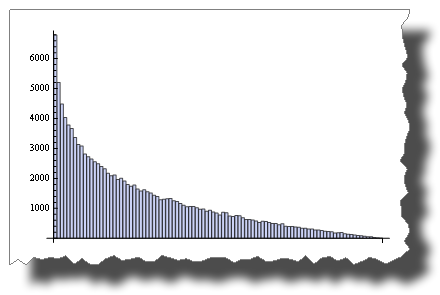
BarChart[BinCounts[Table[RandomReal[{0, 1}, 50000] *
RandomReal[{0, 1}, 50000], {50000}], 0.01]]
Por lo tanto, ambos son "aleatorios", pero su distribución es muy diferente.
Otro ejemplo
Mientras que 2 * Random () se distribuye uniformemente:
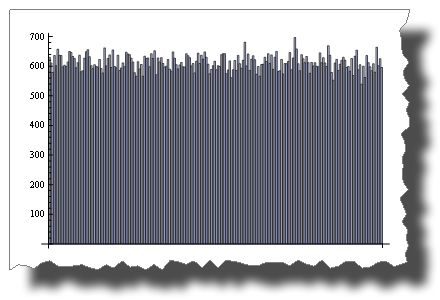
BarChart[BinCounts[2 * RandomReal[{0, 1}, 50000], 0.01]]
Random() + Random() no lo es!
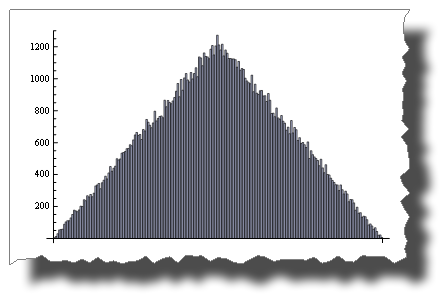
BarChart[BinCounts[Table[RandomReal[{0, 1}, 50000] +
RandomReal[{0, 1}, 50000], {50000}], 0.01]]
El Teorema del Límite Central
El Teorema del Límite Central establece que la suma de Random () tiende a un distribución normal a medida que aumentan los términos.
Con solo cuatro términos obtienes:
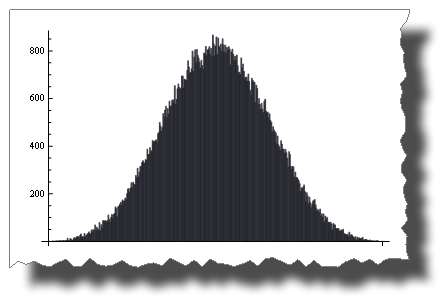
BarChart[BinCounts[Table[RandomReal[{0, 1}, 50000] + RandomReal[{0, 1}, 50000] +
Table[RandomReal[{0, 1}, 50000] + RandomReal[{0, 1}, 50000],
{50000}],
0.01]]
Y aquí se puede ver el camino de una distribución uniforme a una distribución normal sumando 1, 2, 4, 6, 10 y 20 variables aleatorias distribuidas uniformemente:
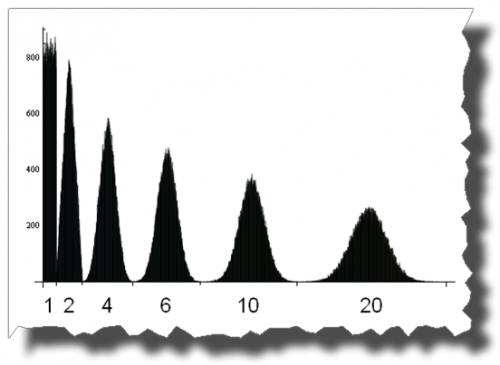
Editar
Algunos créditos
Gracias a Thomas Ahle por señalar en los comentarios que las distribuciones de probabilidad mostradas en las dos últimas imágenes se conocen como distribución de Irwin-Hall
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-05-23 12:10:01
Supongo que ambos métodos son tan aleatorios aunque mi gutfeel diría que rand() * rand() es menos aleatorio porque sembraría más ceros. Tan pronto como un rand() es 0, el total se convierte en 0
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-05-14 19:27:13
Tampoco es 'más aleatorio'.
rand() genera un conjunto predecible de números basado en una semilla psuedo-aleatoria (generalmente basada en el tiempo actual, que siempre está cambiando). Multiplicar dos números consecutivos en la secuencia genera una secuencia de números diferente, pero igualmente predecible.
Abordando si esto reducirá las colisiones, la respuesta es no. En realidad aumentará las colisiones debido al efecto de multiplicar dos números donde 0 < n < 1. El resultado será un fracción más pequeña, causando un sesgo en el resultado hacia el extremo inferior del espectro.
Algunas explicaciones más. En lo siguiente, 'impredecible' y 'aleatorio' se refieren a la capacidad de alguien para adivinar cuál será el siguiente número basado en números anteriores, es decir. un oráculo.
Dada la semilla x que genera la siguiente lista de valores:
0.3, 0.6, 0.2, 0.4, 0.8, 0.1, 0.7, 0.3, ...
rand() generará la lista anterior, y rand() * rand() generará:
0.18, 0.08, 0.08, 0.21, ...
Ambos métodos siempre producirán lo mismo lista de números para la misma semilla, y por lo tanto son igualmente predecibles por un oráculo. Pero si nos fijamos en los resultados para multiplicar las dos llamadas, verás que todos están bajo 0.3 a pesar de una distribución decente en la secuencia original. Los números están sesgados debido al efecto de multiplicar dos fracciones. El número resultante siempre es menor, por lo tanto, es mucho más probable que sea una colisión a pesar de ser igual de impredecible.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-03-19 22:30:20
Simplificación excesiva para ilustrar un punto.
Asuma que su función aleatoria solo produce 0 o 1.
random() es uno de (0,1) pero random()*random() es uno de (0,0,0,1)
Se puede ver claramente que las posibilidades de obtener un 0 en el segundo caso no son de ninguna manera iguales a las de obtener un 1.
Cuando publiqué por primera vez esta respuesta, quería que fuera lo más breve posible para que una persona que la lea comprenda de un vistazo la diferencia entre random() y random()*random(), pero no puedo evitar responder a la pregunta ad litteram original:
¿Qué es más aleatorio?
Siendo que random(), random()*random(), random()+random(), (random()+1)/2 o cualquier otra combinación que no conduce a un resultado fijo tienen la misma fuente de entropía (o el mismo estado inicial en el caso de los generadores pseudoaleatorios), la respuesta sería que son igualmente aleatorios (La diferencia está en su distribución). Un ejemplo perfecto que puede mirar es el juego de dados. El número que obtienes sería random(1,6)+random(1,6) y todos sabemos que obtener 7 tiene la mayor probabilidad, pero eso no significa que el resultado de tirar dos dados sea más o menos aleatorio que el resultado de tirar uno.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-01-19 08:44:41
Aquí hay una respuesta simple. Considera el Monopolio. Lanzas dos dados de seis lados (o 2d6 para aquellos de ustedes que prefieren la notación de juego) y toman su suma. El resultado más común es 7 porque hay 6 maneras posibles de tirar un 7 (1,6 2,5 3,4 4,3 5,2 y 6,1). Mientras que un 2 solo se puede rodar en 1,1. Es fácil ver que rodar 2d6 es diferente de rodar 1d12, incluso si el rango es el mismo (ignorando que puede obtener un 1 en un 1d12, el punto sigue siendo el mismo). Multiplicando sus resultados en lugar de agregarlos, los sesgará de manera similar, con la mayoría de sus resultados en el medio del rango. Si está tratando de reducir los valores atípicos, este es un buen método, pero no ayudará a hacer una distribución uniforme.
(Y curiosamente también aumentará los rollos bajos. Suponiendo que su aleatoriedad comienza en 0, verá un pico en 0 porque convertirá lo que el otro rollo es en un 0. Considere dos números aleatorios entre 0 y 1 (inclusive) y multiplicando. Si cualquiera de los resultados es un 0, todo se convierte en un 0 sin importar el otro resultado. La única manera de obtener un 1 es que ambos rollos sean un 1. En la práctica, esto probablemente no importaría, pero lo convierte en un gráfico extraño.)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-10-19 10:05:05
El obligatorio xkcd...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-02-08 14:07:57
Podría ayudar pensar en esto en números más discretos. Considere si desea generar números aleatorios entre 1 y 36, para que decida que la forma más fácil es lanzar dos dados justos de 6 lados. Usted consigue esto:
1 2 3 4 5 6
-----------------------------
1| 1 2 3 4 5 6
2| 2 4 6 8 10 12
3| 3 6 9 12 15 18
4| 4 8 12 16 20 24
5| 5 10 15 20 25 30
6| 6 12 18 24 30 36
Así que tenemos 36 números, pero no todos están representados equitativamente, y algunos no ocurren en absoluto. Los números cerca de la diagonal central (esquina inferior izquierda a esquina superior derecha) se producirán con la frecuencia más alta.
Los mismos principios que describen la desleal la distribución entre dados se aplica igualmente a los números de coma flotante entre 0.0 y 1.0.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-10-18 20:25:07
Algunas cosas sobre la "aleatoriedad" son contra-intuitivas.
Asumiendo la distribución plana de rand(), lo siguiente le dará distribuciones no planas:
- sesgo alto:
sqrt(rand(range^2)) - sesgo máximo en el medio:
(rand(range) + rand(range))/2 - bajo: sesgo:
range - sqrt(rand(range^2))
Hay muchas otras formas de crear curvas de sesgo específicas. Hice una prueba rápida de rand() * rand() y te da una distribución muy no lineal.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-10-18 04:03:57
"aleatorio" vs. "más aleatorio" es un poco como preguntar qué Cero es más cero.
En este caso, rand es un PRNG, por lo que no es totalmente aleatorio. (de hecho, bastante predecible si se conoce la semilla). Multiplicarlo por otro valor no lo hace más o menos aleatorio.
Un verdadero RNG de tipo criptográfico en realidad será aleatorio. Y ejecutar valores a través de cualquier tipo de función no puede agregar más entropía a ella, y muy probablemente puede eliminar la entropía, por lo que no es más aleatorio.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-10-18 15:52:28
La mayoría de las implementaciones de rand() tienen algún periodo. Es decir, después de un número enorme de llamadas, la secuencia se repite. La secuencia de salidas de rand() * rand() se repite en la mitad del tiempo, por lo que es "menos aleatoria" en ese sentido.
Además, sin una construcción cuidadosa, realizar aritmética en valores aleatorios tiende a causar menos aleatoriedad. Un cartel arriba citado "rand() + rand() + rand() ..."(k veces, digamos) que de hecho tenderá a k veces el valor medio del rango de valores rand() devuelve. (Es un caminar al azar con pasos simétricos sobre esa media.)
Asume para concreción que tu función rand() devuelve un número real aleatorio uniformemente distribuido en el rango [0,1). (Sí, este ejemplo permite una precisión infinita. Esto no cambiará el resultado.) No elegiste un lenguaje en particular y diferentes lenguajes pueden hacer cosas diferentes, pero el siguiente análisis se mantiene con modificaciones para cualquier implementación no perversa de rand (). El producto rand() * rand() también está en la gama [0,1) pero ya no se distribuye uniformemente. De hecho, el producto es probable que esté en el intervalo [0,1/4) como en el intervalo [1/4,1). Más multiplicación sesgará el resultado aún más hacia cero. Esto hace que el resultado sea más predecible. A grandes rasgos, más predecible = = menos aleatorio.
Casi cualquier secuencia de operaciones en la entrada uniformemente aleatoria será no uniformemente aleatoria, lo que conduce a una mayor previsibilidad. Con cuidado, uno puede superar esta propiedad, pero entonces sería han sido más fáciles de generar un número aleatorio uniformemente distribuido en el rango que realmente quería en lugar de perder el tiempo con la aritmética.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-11-16 07:10:21
El concepto que buscas es "entropía", el "grado" de desorden de una cuerda de bits. La idea es más fácil de entender en términos del concepto de "máxima entropía".
Una definición aproximada de una cadena de bits con entropía máxima es que no se puede expresar exactamente en términos de una cadena de bits más corta (es decir. usando algún algoritmo para expanda la cadena más pequeña de nuevo a la cadena original).
La relevancia de la entropía máxima para la aleatoriedad se deriva del hecho que si elige un número "al azar", es casi seguro que elegirá un número cuya cadena de bits está cerca de tener la máxima entropía, es decir, no se puede comprimir. Esta es nuestra mejor comprensión de lo que caracteriza a un número "aleatorio".
Por lo tanto, si desea hacer un número aleatorio de dos muestras aleatorias que es "dos veces" como al azar, concatenar las cadenas de dos bits juntos. Prácticamente, solo rellenar las muestras en las mitades alta y baja de doble longitud palabra.
En una nota más práctica, si te encuentras cargado con un rand () de mierda, puede a veces ayuda a xor un par de muestras juntas - - - aunque, si es realmente roto incluso ese procedimiento no ayudará.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-10-18 19:15:32
La respuesta aceptada es bastante encantadora, pero hay otra manera de responder a tu pregunta. La respuesta de PachydermPuncher ya toma este enfoque alternativo, y solo voy a expandirlo un poco.
La forma más fácil de pensar sobre la teoría de la información es en términos de la unidad más pequeña de información, un solo bit.
En la biblioteca estándar de C, rand() devuelve un entero en el rango 0 a RAND_MAX, un límite que puede definirse de manera diferente dependiendo de la plataforma. Supongamos que RAND_MAX se define como 2^n - 1 donde n es un entero (este es el caso en la implementación de Microsoft, donde n es 15). Entonces diríamos que una buena implementación devolvería n bits de información.
Imagine que rand() construye números aleatorios volteando una moneda para encontrar el valor de un bit, y luego repitiendo hasta que tenga un lote de 15 bits. Entonces los bits son independientes (el valor de cualquier bit no influye en la probabilidad de otros bits en el mismo lote tienen un cierto valor). Por lo tanto, cada bit considerado de forma independiente es como un número aleatorio entre 0 y 1 inclusive, y está "distribuido uniformemente" en ese rango (lo más probable es que sea 0 como 1).
La independencia de los bits asegura que los números representados por lotes de bits también se distribuirán uniformemente sobre su rango. Esto es intuitivamente obvio: si hay 15 bits, el rango permitido es cero a 2^15 - 1 = 32767. Cada número en ese rango es único patrón de bits, tales como:
010110101110010
Y si los bits son independientes, entonces no es más probable que ocurra ningún patrón que cualquier otro patrón. Así que todos los números posibles en el rango son igualmente probables. Y así lo contrario es cierto: si rand() produce enteros distribuidos uniformemente, entonces esos números están hechos de bits independientes.
Así que piense en rand() como una línea de producción para hacer bits, que simplemente pasa a servirlos en lotes de tamaño arbitrario. Si no te gusta el tamaño, romper el lotes en bits individuales, y luego volver a juntarlos en las cantidades que desee (aunque si necesita un rango particular que no sea una potencia de 2, necesita reducir sus números, y por mucho la forma más fácil de hacerlo es convertir a punto flotante).
Volviendo a su sugerencia original, supongamos que desea pasar de lotes de 15 a lotes de 30, pida rand() el primer número, cambie de bit por 15 lugares, luego agregue otro rand() a él. Esa es una manera de combinar dos llamadas a rand() sin alterar una distribución par. Funciona simplemente porque no hay superposición entre las ubicaciones donde se colocan los bits de información.
Esto es muy diferente a "estirar" el rango de rand() multiplicando por una constante. Por ejemplo, si quisieras duplicar el rango de rand() podrías multiplicarlo por dos, pero ahora solo obtendrías números pares, ¡y nunca números impares! Eso no es exactamente una distribución suave y podría ser un problema serio dependiendo de la aplicación, por ejemplo, un juego de ruleta que supuestamente permite apuestas pares / impares. (Al pensar en términos de bits, evitaría ese error intuitivamente, porque se daría cuenta de que multiplicar por dos es lo mismo que mover los bits a la izquierda (mayor importancia) por un lugar y llenar el espacio con cero. Así que obviamente la cantidad de información es la misma - simplemente se movió un poco.)
Tales huecos en rangos numéricos no pueden ser discutidos en aplicaciones de números de coma flotante, porque los rangos de coma flotante inherentemente tienen huecos en ellos que simplemente no se pueden representar en absoluto: un infinito número de números reales que faltan existen en el hueco entre cada dos números de coma flotante representables! Así que tenemos que aprender a vivir con huecos de todos modos.
Como otros han advertido, la intuición es riesgosa en esta área, especialmente porque los matemáticos no pueden resistir el atractivo de los números reales, que son cosas horriblemente confusas llenas de infinidades retorcidas y aparentes paradójico.
Pero al menos si lo piensas en términos de bits, tu intuición podría llevarte un poco más lejos. Los bits son muy fáciles-incluso las computadoras pueden entenderlos.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-05-23 12:02:18
Como otros han dicho, la respuesta corta fácil es: No, no es más aleatoria, pero sí cambia la distribución.
Supongamos que estabas jugando un juego de dados. Tienes unos dados completamente justos y aleatorios. ¿Los dados serían "más aleatorios" si antes de cada dado, primero pones dos dados en un tazón, lo sacudes, eliges uno de los dados al azar y luego lo tiras? Claramente no haría ninguna diferencia. Si ambos dados dan números aleatorios, entonces elige al azar uno de los dos dados no habrá diferencia. De cualquier manera obtendrá un número aleatorio entre 1 y 6 con distribución uniforme sobre un número suficiente de rollos.
Supongo que en la vida real tal procedimiento podría ser útil si sospecha que los dados podrían NO ser justos. Si, por ejemplo, los dados están ligeramente desequilibrados por lo que uno tiende a dar 1 más a menudo que 1/6 del tiempo, y otro tiende a dar 6 inusualmente a menudo, entonces elegir al azar entre los dos tendería a oscurecer el sesgo. (Aunque en este caso, 1 y 6 todavía surgirían más de 2, 3, 4 y 5. Bueno, supongo que dependiendo de la naturaleza del desequilibrio.)
Hay muchas definiciones de aleatoriedad. Una definición de una serie aleatoria es que es una serie de números producidos por un proceso aleatorio. Por esta definición, si tiro un dado justo 5 veces y obtener los números 2, 4, 3, 2, 5, es una serie aleatoria. Si luego ruedo esa misma feria morir 5 veces más y obtener 1, 1, 1, 1, 1, entonces eso es también una serie aleatoria.
Varios carteles han señalado que las funciones aleatorias en una computadora no son realmente aleatorias sino más bien pseudo-aleatorias, y que si conoces el algoritmo y la semilla son completamente predecibles. Esto es cierto, pero la mayoría de las veces completamente irrelevante. Si me barajar un mazo de cartas y luego voltea uno a la vez, esto debería ser una serie aleatoria. Si alguien echa un vistazo a las cartas, el resultado será completamente predecible, pero para la mayoría de las definiciones de aleatoriedad esto no lo hará menos aleatorio. Si el serie pasa pruebas estadísticas de aleatoriedad, el hecho de que me asomó a las tarjetas no va a cambiar ese hecho. En la práctica, si estamos apostando grandes sumas de dinero en su capacidad para adivinar la siguiente tarjeta, entonces el hecho de que se asomó a las tarjetas es muy relevante. Si estamos utilizando la serie para simular las selecciones de menú de los visitantes de nuestro sitio web con el fin de probar el rendimiento del sistema, entonces el hecho de que se asomó no hará ninguna diferencia en absoluto. (Siempre y cuando no modifique el programa para aprovechar este conocimiento.)
EDITAR
No creo que pudiera convertir mi respuesta al problema de Monty Hall en un comentario, así que actualizaré mi respuesta.
Para aquellos que no leyeron Belisarius link, la esencia de esto es: A un concursante de un concurso se le da una opción de 3 puertas. Detrás de uno hay un premio valioso, detrás de los otros algo sin valor. Escoge la puerta # 1. Antes de revelar si es un ganador o un perdedor, el anfitrión abre la puerta #3 para revelar que es un perdedor. Luego le da al concursante la oportunidad de cambiar a la puerta #2. ¿Debería el concursante hacer esto o no?
La respuesta, que ofende la intuición de muchas personas, es que debe cambiar. La probabilidad de que su elección original fue el ganador es 1/3, que la otra puerta es el ganador es 2/3. Mi intuición inicial, junto con la de muchas otras personas, es que no habría ganancia en el cambio, que las probabilidades se han cambiado a 50:50.
Después de todo, supongamos que alguien encendió el televisor justo después de que el anfitrión abriera la puerta perdedora. Esa persona vería dos puertas cerradas restantes. Asumiendo que conoce la naturaleza del juego, diría que hay una probabilidad de 1/2 de que cada puerta oculte el premio. ¿Cómo pueden las probabilidades para el espectador ser 1/2 : 1/2 mientras que las probabilidades para el concursante son 1/3: 2/3 ?
Realmente tuve que pensar en esto para darle forma a mi intuición. Para tener una mano en él, entender que cuando hablamos de probabilidades en un problema como este, media, la probabilidad que se asigna dada la información disponible. Para un miembro de la tripulación que puso el premio detrás, digamos, de la puerta #1, la probabilidad de que el premio esté detrás de la puerta #1 es del 100% y la probabilidad de que esté detrás de cualquiera de las otras dos puertas es cero.
Las probabilidades del miembro de la tripulación son diferentes a las probabilidades del concursante porque sabe algo que el concursante no sabe, a saber, qué puerta puso el premio detrás. Del mismo modo, las probabilidades del concursante son diferentes a las del espectador probabilidades porque sabe algo que el espectador no sabe, es decir, qué puerta eligió inicialmente. Esto no es irrelevante, porque la elección del anfitrión de qué puerta abrir no es aleatoria. No abrirá la puerta que el concursante escogió, y no abrirá la puerta que esconde el premio. Si estas son la misma puerta, eso le deja dos opciones. Si son puertas diferentes, eso deja solo una.
Entonces, ¿cómo se nos ocurre 1/3 y 2/3 ? Cuando el concursante originalmente eligió una puerta, tenía un 1/3 de probabilidad de elegir al ganador. Creo que eso es obvio. Eso significa que había una probabilidad de 2/3 de que una de las otras puertas sea la ganadora. Si el juego anfitrión le la oportunidad de cambiar sin dar ninguna información adicional, no habría ninguna ganancia. Una vez más, esto debería ser obvio. Pero una forma de verlo es decir que hay una probabilidad de 2/3 de que ganaría cambiando. Pero tiene 2 alternativas. Así que cada uno tiene solo 2/3 dividido por 2 = 1/3 probabilidad de ser el ganador, que no es mejor que su elección original. Por supuesto, ya sabíamos el resultado final, esto solo lo calcula de una manera diferente.
Pero ahora el anfitrión revela que una de esas dos opciones no es la ganadora. Así que de la probabilidad de 2/3 de que una puerta que no eligió sea la ganadora, ahora sabe que 1 de las 2 alternativas no lo es. El otro podría o no serlo. Así que ya no tiene 2/3 dividido por 2. Tiene cero para la puerta abierta y 2/3 para la puerta cerrada.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-10-19 20:39:05
Considere que tiene un problema simple de lanzamiento de moneda donde par se considera cara y impar se considera colas. La implementación lógica es:
rand() mod 2
Sobre una distribución lo suficientemente grande, el número de números pares debe ser igual al número de números impares.
Ahora considere un ligero ajuste:
rand() * rand() mod 2
Si uno de los resultados es par, entonces todo el resultado debe ser par. Considere el 4 resultados posibles (incluso * a =, incluso * impar = par, impar * par = par, impar * impar = extraño). Ahora, en una distribución lo suficientemente grande, la respuesta debería ser incluso el 75% del tiempo.
Apostaría cara si fuera tú.
Este comentario es realmente más una explicación de por qué no debe implementar una función aleatoria personalizada basada en su método que una discusión sobre las propiedades matemáticas de la aleatoriedad.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-10-18 23:28:44
Cuando tenga dudas sobre lo que sucederá con las combinaciones de sus números aleatorios, puede usar las lecciones que aprendió en teoría estadística.
En la situación de OP quiere saber cuál es el resultado de X*X = X^2 donde X es una variable aleatoria distribuida a lo largo de Uniforme[0,1]. Usaremos la técnica CDF ya que es solo un mapeo uno a uno.
Desde X ~ Uniforme [0,1] es cdf: f X (x) = 1 Queremos la transformación Y
La distribución de Y está dada como: fY(y) = fX(x(y)) |dx/dy| = 1/(2 sqrt(y))
No hemos terminado todavía, tenemos que obtener el dominio de Y. desde 0 Integrar 1/(2 sqrt(y)) de 0 a 1 y de hecho, aparece como 1. También, observe que la forma de dicha función se parece a lo belisario publicado.
Como para cosas como X1 + X2 + ... + X n, (donde X i ~ Uniforme[0,1]) solo podemos apelar al Teorema del Límite Central que funciona para cualquier distribución cuyos momentos existen. Esta es la razón por la que la prueba Z existe en realidad.
Otras técnicas para determinar el pdf resultante incluyen la transformación jacobiana (que es la versión generalizada de la técnica CDF) y MGF técnica.
EDITAR: Como aclaración, tenga en cuenta que estoy hablando de la distribución de la transformación resultante y no de su aleatoriedad . Eso es en realidad para una discusión separada. También lo que realmente derivé fue para (rand ())^2. Para rand () * rand () es mucho más complicado, lo que, en cualquier caso, no resultará en una distribución uniforme de ningún tipo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-10-18 15:26:26
No es exactamente obvio, pero rand() es típicamente más aleatorio que rand()*rand(). Lo importante es que esto no es realmente muy importante para la mayoría de los usos.
Pero en primer lugar, producen diferentes distribuciones. Esto no es un problema si eso es lo que quieres, pero sí importa. Si necesita una distribución en particular, ignore toda la pregunta "que es más aleatoria". Entonces, ¿por qué rand() es más aleatorio?
El núcleo de por qué rand() es más aleatorio (bajo la suposición de que es producir números aleatorios de coma flotante con el rango [0..1], que es muy común) es que cuando multiplicas dos números FP junto con mucha información en la mantisa, obtienes alguna pérdida de información del final; simplemente no hay suficiente bit en un flotador de doble precisión IEEE para contener toda la información que estaba en dos flotadores de doble precisión IEEE seleccionados uniformemente al azar de [0..1], y esos bits adicionales de información se pierden. Por supuesto, no importa tanto ya que (probablemente) no vamos a usar esa información, pero la pérdida es real. Tampoco importa realmente qué distribución produzcas (es decir, qué operación utilices para hacer la combinación). Cada uno de esos números aleatorios tiene (en el mejor de los casos) 52 bits de información aleatoria – eso es lo mucho que puede contener un doble IEEE – y si combina dos o más en uno, todavía está limitado a tener como máximo 52 bits de información aleatoria.
La mayoría de los usos de números aleatorios no utilizan ni siquiera cerca de tanta aleatoriedad como está realmente disponible en la fuente aleatoria. Consigue un buen PRNG y no te preocupes demasiado por ello. (El nivel de "bondad" depende de lo que estés haciendo con él; tienes que tener cuidado al hacer simulación de Monte Carlo o criptografía, pero de lo contrario probablemente puedas usar el PRNG estándar ya que suele ser mucho más rápido.)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-10-19 10:51:18
Las variables aleatorias flotantes se basan, en general, en un algoritmo que produce un entero entre cero y un cierto rango. Como tal, al usar rand()*rand(), esencialmente estás diciendo int_rand()*int_rand()/rand_max^2 - lo que significa que estás excluyendo cualquier número primo / rand_max^2.
Que cambia significativamente la distribución aleatoria.
Rand() se distribuye uniformemente en la mayoría de los sistemas, y es difícil de predecir si se siembra correctamente. Úselo a menos que tenga una razón particular para hacerlo matemáticas en él(es decir, dar forma a la distribución a una curva necesaria).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-10-18 05:38:42
Multiplicar números terminaría en un rango de solución más pequeño dependiendo de la arquitectura de su computadora.
Si la pantalla de su computadora muestra 16 dígitos rand() sería decir 0.1234567890123
multiplicado por un segundo rand(), 0.1234567890123, daría 0.0152415 algo
definitivamente encontrarías menos soluciones si repitieras el experimento 10^14 veces.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-05-22 00:12:45
La mayoría de estas distribuciones ocurren porque tienes que limitar o normalizar el número aleatorio.
Lo normalizamos para que sea todo positivo, quepa dentro de un rango, e incluso para que quepa dentro de las restricciones del tamaño de memoria para el tipo de variable asignado.
En otras palabras, debido a que tenemos que limitar la llamada aleatoria entre 0 y X (X es el límite de tamaño de nuestra variable) tendremos un grupo de números "aleatorios" entre 0 y X.
Ahora cuando se agrega el número aleatorio a otro número aleatorio la suma estará en algún lugar entre 0 y 2X...esto sesga los valores lejos de los puntos de borde (la probabilidad de sumar dos números pequeños juntos y dos números grandes juntos es muy pequeña cuando tienes dos números aleatorios en un rango grande).
Piense en el caso en el que tuvo un número que está cerca de cero y lo agrega con otro número aleatorio que sin duda será más grande y lejos de 0 (esto será cierto de los números grandes, así como es poco probable que tenga dos números grandes (números cercanos a X) devueltos por la función aleatoria dos veces.
Ahora bien, si tuviera que configurar el método aleatorio con números negativos y números positivos (que abarcan igualmente a través del eje cero) este ya no sería el caso.
Digamos por ejemplo RandomReal({-x, x}, 50000, .01) entonces obtendrías una distribución par de números en el lado negativo a positivo y si sumaras los números aleatorios juntos mantendrían su "aleatoriedad".
Ahora no estoy seguro de lo que pasaría con el Random() * Random() con el span negativo a positivo...sería un gráfico interesante de ver...pero tengo que volver a escribir código ahora. :- P
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-10-28 08:15:58
No Hay tal cosa como más azar. Es aleatorio o no. Aleatorio significa "difícil de predecir". No significa no determinista. Tanto random () como random () * random() son igualmente aleatorios si random () es aleatorio. La distribución es irrelevante en lo que respecta a la aleatoriedad. Si se produce una distribución no uniforme, solo significa que algunos valores son más probables que otros; todavía son impredecibles.
Dado que la pseudo-aleatoriedad está involucrada, los números son muy determinista. Sin embargo, la pseudo-aleatoriedad es a menudo suficiente en modelos de probabilidad y simulaciones. Es bastante conocido que hacer un generador de números pseudo-aleatorios complicado solo hace que sea difícil de analizar. Es poco probable que mejore la aleatoriedad; a menudo hace que falle en las pruebas estadísticas.
Las propiedades deseadas de los números aleatorios son importantes: repetibilidad y reproducibilidad, aleatoriedad estadística, (generalmente) uniformemente distribuida, y una gran punto son unos pocos.
Con respecto a las transformaciones en números aleatorios: Como alguien dijo, la suma de dos o más resultados uniformemente distribuidos en una distribución normal. Este es el teorema del límite central aditivo. Se aplica independientemente de la distribución de origen, siempre y cuando todas las distribuciones sean independientes e idénticas. El teorema del límite central multiplicativo dice que el producto de dos o más variables aleatorias independientes e indénticamente distribuidas es lognormal. El gráfico creado por otra persona parece exponencial, pero es realmente lognormal. Así que random () * random () está distribuido lognormalmente (aunque puede no ser independiente ya que los números se extraen de la misma corriente). Esto puede ser deseable en algunas aplicaciones. Sin embargo, generalmente es mejor generar un número aleatorio y transformarlo en un número distribuido lognormalmente. Random() * random() puede ser difícil de analizar.
Para más información, consulte mi libro en www.performorama.org. El libro está en construcción, pero el material relevante está ahí. Tenga en cuenta que los números de capítulo y sección pueden cambiar con el tiempo. Capítulo 8 (teoría de la probabilidad) - secciones 8.3.1 y 8.3.3, capítulo 10 (números aleatorios).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-01-11 06:23:21
Podemos comparar dos matrices de números con respecto a la aleatoriedad utilizando Kolmogorov complejidad Si la secuencia de números no se puede comprimir, entonces es la más aleatoria que podemos alcanzar en esta longitud... Sé que este tipo de medición es más una opción teórica...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-05-25 09:57:14
En realidad, cuando lo piensas rand() * rand() es menos aleatorio que rand(). He aquí por qué.
Esencialmente, hay el mismo número de números impares que los números pares. Y diciendo que 0.04325 es impar, y como 0.388 es aún, y el 0,4 incluso, y 0,15 es impar,
Eso significa que rand()tiene una igual probabilidad de ser un decimal par o impar.
Por otro lado, rand() * rand() tiene sus probabilidades apiladas un poco diferente.
Digamos:
double a = rand();
double b = rand();
double c = a * b;
a y b ambos tienen un 50% de probabilidad previa de ser pares o impares. Sabiendo que
- par * par = par
- par * impar = par
- impar * impar = impar
- impar * par = par
Significa que hay un 75% de probabilidad que ces par, mientras que solo un 25% de probabilidad es impar, haciendo que el valor de rand() * rand() sea más predecible que rand(), por lo tanto menos aleatorio.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-01-16 13:02:22
Utilice un registro de desplazamiento de retroalimentación lineal (LFSR) que implemente un polinomio primitivo.
El resultado será una secuencia de 2^n números pseudo-aleatorios, es decir, ninguno que se repita en la secuencia donde n es el número de bits en el LFSR .... resultando en una distribución uniforme.
Http://en.wikipedia.org/wiki/Linear_feedback_shift_register http://www.xilinx.com/support/documentation/application_notes/xapp052.pdf
Utilice una semilla "aleatoria" basada en microsecs de su reloj de la computadora o tal vez un subconjunto del resultado md5 en algunos datos que cambian continuamente en su sistema de archivos.
Por ejemplo, un LFSR de 32 bits generará 2^32 números únicos en secuencia (no 2 iguales) comenzando con una semilla dada. La secuencia siempre estará en el mismo orden, pero el punto de partida será diferente (obviamente) para una semilla diferente. Por lo tanto, si una posible repetición de secuencia entre sesiones no es un problema, esta podría ser una buena opción.
He usado LFSR de 128 bits para genere pruebas aleatorias en simuladores de hardware utilizando una semilla que es los resultados md5 en datos del sistema que cambian continuamente.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-06-02 15:37:26
Suponiendo que rand() devuelve un número entre [0, 1) es obvio que rand() * rand() estará sesgado hacia 0. Esto se debe a que multiplicar x por un número entre [0, 1) resultará en un número menor que x. Aquí está la distribución de 10000 más números aleatorios:
google.charts.load("current", { packages: ["corechart"] });
google.charts.setOnLoadCallback(drawChart);
function drawChart() {
var i;
var randomNumbers = [];
for (i = 0; i < 10000; i++) {
randomNumbers.push(Math.random() * Math.random());
}
var chart = new google.visualization.Histogram(document.getElementById("chart-1"));
var data = new google.visualization.DataTable();
data.addColumn("number", "Value");
randomNumbers.forEach(function(randomNumber) {
data.addRow([randomNumber]);
});
chart.draw(data, {
title: randomNumbers.length + " rand() * rand() values between [0, 1)",
legend: { position: "none" }
});
}<script src="https://www.gstatic.com/charts/loader.js"></script>
<div id="chart-1" style="height: 500px">Generating chart...</div>Si rand() devuelve un entero entre [x, y] entonces tiene la siguiente distribución. Observe el número de impar vs par valores:
google.charts.load("current", { packages: ["corechart"] });
google.charts.setOnLoadCallback(drawChart);
document.querySelector("#draw-chart").addEventListener("click", drawChart);
function randomInt(min, max) {
return Math.floor(Math.random() * (max - min + 1)) + min;
}
function drawChart() {
var min = Number(document.querySelector("#rand-min").value);
var max = Number(document.querySelector("#rand-max").value);
if (min >= max) {
return;
}
var i;
var randomNumbers = [];
for (i = 0; i < 10000; i++) {
randomNumbers.push(randomInt(min, max) * randomInt(min, max));
}
var chart = new google.visualization.Histogram(document.getElementById("chart-1"));
var data = new google.visualization.DataTable();
data.addColumn("number", "Value");
randomNumbers.forEach(function(randomNumber) {
data.addRow([randomNumber]);
});
chart.draw(data, {
title: randomNumbers.length + " rand() * rand() values between [" + min + ", " + max + "]",
legend: { position: "none" },
histogram: { bucketSize: 1 }
});
}<script src="https://www.gstatic.com/charts/loader.js"></script>
<input type="number" id="rand-min" value="0" min="0" max="10">
<input type="number" id="rand-max" value="9" min="0" max="10">
<input type="button" id="draw-chart" value="Apply">
<div id="chart-1" style="height: 500px">Generating chart...</div>Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-05-14 22:32:16
OK, así que intentaré agregar algún valor para complementar otras respuestas diciendo que estás creando y utilizando un generador de números aleatorios.
Los generadores de números aleatorios son dispositivos (en un sentido muy general) que tienen múltiples características que se pueden modificar para adaptarse a un propósito. Algunos de ellos (de mí) son:
- Entropía: como en la Entropía de Shannon
- Distribución: distribución estadística (poisson, normal, etc.)
- Tipo: cuál es la fuente de los números (algoritmo, evento natural, combinación de, etc.) y algoritmo aplicado.
- Eficiencia: rapidez o complejidad de ejecución.
- Patrones: periodicidad, secuencias, corridas, etc.
- y probablemente más...
En la mayoría de las respuestas aquí, la distribución es el principal punto de interés, pero al mezclar y emparejar funciones y parámetros, se crean nuevas formas de generar números aleatorios que tendrán diferentes características para algunas de las cuales la evaluación puede no ser obvia en a primera vista.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-06-02 13:51:08
Es fácil demostrar que la suma de los dos números aleatorios no es necesariamente aleatoria. Imagine que tiene un dado de 6 lados y rollo. Cada número tiene una probabilidad de 1/6 de aparecer. Ahora diga que tenía 2 dados y sumó el resultado. La distribución de esas sumas no es 1/12. ¿Por qué? Porque ciertos números aparecen más que otros. Hay múltiples particiones de ellas. Por ejemplo el número 2 es la suma de 1+1 solamente pero 7 puede ser formado por 3 + 4 o 4 + 3 o 5+2 etc... así que tiene una mayor probabilidad de enseguida.
Por lo tanto, la aplicación de una transformada, en este caso la adición en una función aleatoria no la hace más aleatoria, o necesariamente preserva la aleatoriedad. En el caso de los dados anteriores, la distribución es sesgada a 7 y por lo tanto menos aleatoria.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-09-26 04:20:35
Como otros ya señalaron, esta pregunta es difícil de responder ya que cada uno de nosotros tiene su propia imagen de aleatoriedad en su cabeza.
Por eso, le recomiendo que se tome un tiempo y lea este sitio para tener una mejor idea de la aleatoriedad:
Para volver a la pregunta real. No hay más o menos aleatorio en este término:
Ambos sólo aparecen random!
En ambos casos-solo rand() o rand () * rand () - la situación es la misma: Después de unos pocos miles de millones de números la secuencia se repetirá(!). It aparece aleatorio para el observador, porque no conoce toda la secuencia, pero la computadora no tiene ninguna fuente aleatoria verdadera, por lo que tampoco puede producir aleatoriedad.
Por ejemplo: ¿El clima es aleatorio? No tenemos suficientes sensores o conocimientos para determinar si el clima es aleatorio o ni.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-05-17 20:26:35
La respuesta sería que depende, esperemos que el rand () * rand() sería más aleatorio que rand (), pero como:
- ambas respuestas dependen del tamaño de bits de su valor
- que en la mayoría de los casos se genera dependiendo de un algoritmo pseudo-aleatorio (que es en su mayoría un generador de números que depende del reloj de su computadora, y no tanto aleatorio).
- haga su código más legible (y no invoque a algún dios vudú aleatorio del azar con este tipo de mantras).
Bueno, si revisas cualquiera de estos anteriores te sugiero que vayas por el simple "rand()". Porque tu código sería más legible (no te preguntarías por qué escribiste esto, para ...bien... más de 2 segundos), fácil de mantener (si desea reemplazar su función rand con un super_rand).
Si desea un mejor azar, le recomendaría que lo transmita desde cualquier fuente que proporcione suficiente ruido (radio static ), y luego un simple rand() debería ser suficientemente.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-05-22 00:06:50