En CUDA, ¿qué es la unión de la memoria y cómo se logra?
¿Qué es "coalesced" en CUDA global memory transaction? No podía entender incluso después de pasar por mi guía CUDA. Cómo hacerlo? En ejemplo de matriz de guía de programación CUDA, acceder a la matriz fila por fila se llama "coalesced" o col.. por col.. ¿se llama coalesced? ¿Qué es correcto y por qué?
4 answers
Es probable que esta información se aplique solo para calcular la capabalidad 1.x, o cuda 2.0. Las arquitecturas más recientes y cuda 3.0 tienen un acceso a memoria global más sofisticado y, de hecho, las "cargas globales fusionadas" ni siquiera se perfilan para estos chips.
Además, esta lógica se puede aplicar a la memoria compartida para evitar conflictos bancarios.
Una transacción de memoria fusionada es aquella en la que todos los hilos de una media urdimbre acceden a la memoria global al mismo tiempo. Esto es demasiado simple, pero la forma correcta de hacerlo es simplemente tener hilos consecutivos acceder a direcciones de memoria consecutivas.
Entonces, si los hilos 0, 1, 2 y 3 leen la memoria global 0x0, 0x4, 0x8 y 0xc, debería ser una lectura fusionada.
En un ejemplo de matriz, tenga en cuenta que desea que su matriz resida linealmente en la memoria. Puede hacer esto como quiera, y su acceso a la memoria debe reflejar cómo se presenta su matriz. Por lo tanto, la matriz 3x4 a continuación
0 1 2 3
4 5 6 7
8 9 a b
Podría hacerse fila después de la fila, así, de modo que (r,c) se asigna a la memoria (r*4 + c)
0 1 2 3 4 5 6 7 8 9 a b
Supongamos que necesita acceder a element una vez, y digamos que tiene cuatro subprocesos. ¿Qué hilos se utilizarán para qué elemento? Probablemente ya sea
thread 0: 0, 1, 2
thread 1: 3, 4, 5
thread 2: 6, 7, 8
thread 3: 9, a, b
O
thread 0: 0, 4, 8
thread 1: 1, 5, 9
thread 2: 2, 6, a
thread 3: 3, 7, b
¿cuál es mejor? ¿Cuál resultará en lecturas fusionadas, y cuál no?
De cualquier manera, cada hilo hace tres accesos. Veamos el primer acceso y veamos si los hilos acceden a la memoria consecutivamente. En la primera opción, la primera el acceso es 0, 3, 6, 9. No consecutivas, no unidas. La segunda opción, es 0, 1, 2, 3. ¡Consecutiva! Se unieron! Yay!
La mejor manera es probablemente escribir su núcleo y luego perfilarlo para ver si tiene cargas y almacenes globales no fusionados.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-02-18 17:28:02
La coalescencia de memoria es una técnica que permite un uso óptimo del ancho de banda de memoria global. Es decir, cuando subprocesos paralelos que ejecutan el mismo acceso de instrucción a ubicaciones consecutivas en la memoria global, se logra el patrón de acceso más favorable.
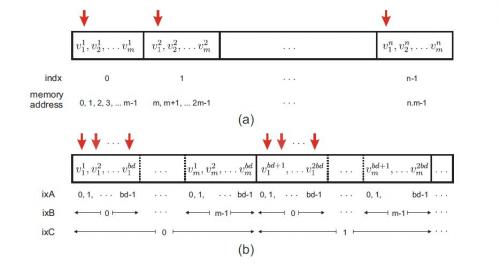
El ejemplo de la figura anterior ayuda a explicar la disposición fusionada:
En la Fig. (a), n los vectores de longitud m se almacenan de manera lineal. Elemento i del vector j se denota por v ji. Cada subproceso en el núcleo de GPU se asigna a un vector m-length. Los subprocesos en CUDA se agrupan en una matriz de bloques y cada subproceso en la GPU tiene un id único que se puede definir como indx=bd*bx+tx, donde bd representa la dimensión del bloque, bx denota el índice del bloque y tx es el índice del subproceso en cada bloque.
Las flechas verticales demuestran el caso de que los hilos paralelos acceden a los primeros componentes de cada uno vector, es decir, direcciones 0, m, 2m ... de la memoria. Como se muestra en la Fig. (a), en este caso el acceso a la memoria no es consecutivo. Al reducir a cero el espacio entre estas direcciones (las flechas rojas se muestran en la figura anterior), el acceso a la memoria se une.
Sin embargo, el problema se vuelve un poco complicado aquí, ya que el tamaño permitido de subprocesos residentes por bloque de GPU está limitado a bd. Por lo tanto, la disposición de datos fusionados se puede hacer almacenando los primeros elementos de la primera bd vectores en orden consecutivo, seguido por los primeros elementos de los vectores segundo bd y así sucesivamente. El resto de los elementos vectores se almacenan de manera similar, como se muestra en la Fig. b). Si n (número de vectores) no es un factor de bd, es necesario rellenar los datos restantes en el último bloque con algún valor trivial, por ejemplo, 0.
En el almacenamiento lineal de datos de la Fig. a), componente i (0 ≤ i m ) del vector indx
(0 ≤ indx n) es dirigido por m × indx +i; el mismo componente en el confederado
patrón de almacenamiento en la Fig. b) se dirige como
(m × bd) ixC + bd × ixB + ixA,
Donde ixC = floor[(m.indx + j )/(m.bd)]= bx, ixB = j y ixA = mod(indx,bd) = tx.
En resumen, en el ejemplo de almacenar un número de vectores con tamaño m , la indexación lineal se asigna a la indexación unificada de acuerdo con:
m.indx +i −→ m.bd.bx +i .bd +tx
Esta reordenación de datos puede conducir a un ancho de banda de memoria significativamente mayor de la memoria global de la GPU.
Fuente: "GPU‐based acceleration of computations in nonlinear finite element deformation analysis."International journal for numerical methods in biomedical engineering (2013).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-11-14 16:32:51
Si los subprocesos en un bloque están accediendo a ubicaciones de memoria globales consecutivas, entonces todos los accesos se combinan en una sola solicitud(o se fusionan) por el hardware. En el ejemplo de matriz, los elementos de matriz en la fila se ordenan linealmente, seguidos por la siguiente fila, y así sucesivamente. Por ejemplo, para una matriz de 2x2 y 2 hilos en un bloque, las ubicaciones de memoria están dispuestas como:
(0,0) (0,1) (1,0) (1,1)
En row access, thread1 accede (0,0) y (1,0) que no se pueden fusionar. Acceso en columna, thread1 accesos (0,0) y (0,1) que se pueden unir porque son adyacentes.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-02-18 18:08:31
Los criterios para la coalescencia están bien documentados en la Guía de Programación CUDA 3.2, Sección G. 3.2. La versión corta es la siguiente: los hilos en el warp deben estar accediendo a la memoria en secuencia, y las palabras a las que se accede deben >=32 bits. Además, la dirección base a la que se accede por warp debe estar alineada con 64, 128 o 256 bytes para accesos de 32, 64 y 128 bits, respectivamente.
El hardware Tesla2 y Fermi hace un buen trabajo al fusionar 8 y 16 bits accesos, pero es mejor evitarlos si desea un ancho de banda máximo.
Tenga en cuenta que a pesar de las mejoras en el hardware Tesla2 y Fermi, la fusión NO es obsoleta. Incluso en hardware de clase Tesla2 o Fermi, no fusionar transacciones de memoria global puede resultar en un éxito de rendimiento 2x. (En hardware de clase Fermi, esto parece ser cierto solo cuando ECC está habilitado. Las transacciones de memoria contiguas pero sin cola reciben aproximadamente un 20% de éxito en Fermi.)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-02-13 02:32:52