Distancia de Levenshtein: ¿cómo manejar mejor las palabras intercambiando posiciones?
He tenido cierto éxito comparando cadenas usando la función PHP levenshtein.
Sin embargo, para dos cadenas que contienen subcadenas que han intercambiado posiciones, el algoritmo las cuenta como subcadenas completamente nuevas.
Por ejemplo:
levenshtein("The quick brown fox", "brown quick The fox"); // 10 differences
Se tratan como teniendo menos en común que:
levenshtein("The quick brown fox", "The quiet swine flu"); // 9 differences
Preferiría un algoritmo que viera que los primeros dos eran más similares.
¿Cómo podría llegar a una comparación función que puede identificar subcadenas que han cambiado de posición como distintas a las ediciones?
Un posible enfoque que he pensado es poner todas las palabras en la cadena en orden alfabético, antes de la comparación. Eso elimina completamente el orden original de las palabras de la comparación. Una desventaja de esto, sin embargo, es que cambiar solo la primera letra de una palabra puede crear una interrupción mucho más grande que un cambio de una sola letra debería causar.
Lo que estoy tratando de achieve es comparar dos hechos sobre personas que son cadenas de texto libres, y decidir qué tan probable es que estos hechos indiquen el mismo hecho. Los hechos pueden ser la escuela a la que asistió alguien, el nombre de su empleador o editor, por ejemplo. Dos registros pueden tener la misma escuela escrita de manera diferente, palabras en un orden diferente, palabras adicionales, etc., por lo que la coincidencia tiene que ser algo borrosa si queremos hacer una buena suposición de que se refieren a la misma escuela. Hasta ahora está funcionando muy bien para errores de ortografía (estoy usando un algoritmo phenetic similar a metaphone en la parte superior de todo esto) pero muy mal si se cambia el orden de las palabras alrededor de las cuales parecen comunes en una escuela: "xxx college" vs "college of xxx".
9 answers
N-gramos
Use N-grams, que soportan transposiciones de caracteres múltiples en todo el texto.
La idea general es dividir las dos cadenas en cuestión en todas las subcadenas de 2-3 caracteres posibles (n-gramos) y tratar el número de n-gramos compartidos entre las dos cadenas como su métrica de similitud. Esto se puede normalizar dividiendo el número compartido por el número total de n gramos en la cadena más larga. Esto es trivial de calcular, pero bastante poderoso.
Para las oraciones de ejemplo:
A. The quick brown fox
B. brown quick The fox
C. The quiet swine flu
A y B compartir 18 2-gramos
A y C comparten solamente 8 2-gramos
Fuera de 20 total posible.
Esto ha sido discutido con más detalle en el Gravano et al. paper .
Tf-idf y similitud del coseno
Una alternativa no tan trivial, pero basada en la teoría de la información sería usar el término término frecuencia–documento inverso frecuencia (tf-idf) para pesar los tokens, construir vectores de oración y luego utilizar coseno similitud como la métrica de similitud.
El algoritmo es:
- Calcule las frecuencias token de 2 caracteres (tf) por frase.
- Calcule las frecuencias inversas de oración (idf), que es un logaritmo de un cociente del número de todas las oraciones en el corpus (en este caso 3) dividido por el número de veces que aparece un token en particular a través de todas las oraciones. En este caso th está en todas las oraciones por lo que tiene cero contenido de información (log(3/3)=0).
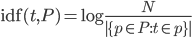
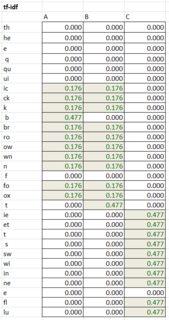
- Producir la matriz tf-idf multiplicando las celdas correspondientes en las tablas tf e idf.
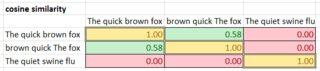
- Finalmente, calcule la matriz de similitud de coseno para todos los pares de oraciones, donde A y B son pesos de la tabla tf-idf para los tokens correspondientes. El rango es de 0 (no similar) a 1 (igual).
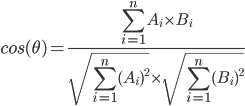
Modificaciones de Levenshtein y Metaphone
Con respecto a otras respuestas. Damerau–Levenshtein la modificación solo admite la transposición de dos caracteres adyacentes. Metaphone fue diseñado para coincidir con palabras que suenan igual y no por coincidencia de similitud.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-04-04 20:49:41
Es fácil. Simplemente use la distancia Damerau-Levenshtein en las palabras en lugar de las letras.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2009-05-06 05:39:59
Explotar en espacios, ordenar la matriz, implosionar, luego hacer el Levenshtein.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2009-05-06 17:06:14
También puedes probar esto. (solo una sugerencia adicional)
$one = metaphone("The quick brown fox"); // 0KKBRNFKS
$two = metaphone("brown quick The fox"); // BRNKK0FKS
$three = metaphone("The quiet swine flu"); // 0KTSWNFL
similar_text($one, $two, $percent1); // 66.666666666667
similar_text($one, $three, $percent2); // 47.058823529412
similar_text($two, $three, $percent3); // 23.529411764706
Esto mostrará que el 1er y 2do son más similares que uno y tres y dos y tres.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2009-05-06 09:34:45
He estado implementando levenshtein en un corrector ortográfico.
Lo que estás pidiendo es contar las transposiciones como 1 edición.
Esto es fácil si solo desea contar las transposiciones de una palabra de distancia. Sin embargo, para la transposición de palabras 2 o más lejos, la adición al algoritmo es el peor de los casos !(max(wordorder1.length(), wordorder2.length())). Agregar un subalgoritmo no lineal a un algoritmo ya cuadrático no es una buena idea.
Así es como funcionaría.
if (wordorder1[n] == wordorder2[n-1])
{
min(workarray[x-1, y] + 1, workarray[x, y-1] + 1, workarray[x-2, y-2]);
}
else
{
min(workarray[x-1, y] + 1, workarray[x, y-1] + 1);
}
SOLO para tocar transposición. Si desea todas las transposiciones, tendría que trabajar para cada posición hacia atrás desde ese punto comparando
1[n] == 2[n-2].... 1[n] == 2[0]....
Así que ves por qué no incluyen esto en el método estándar.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2009-12-25 09:58:41
Toma esta respuesta y haz el siguiente cambio:
void match(trie t, char* w, string s, int budget){
if (budget < 0) return;
if (*w=='\0') print s;
foreach (char c, subtrie t1 in t){
/* try matching or replacing c */
match(t1, w+1, s+c, (*w==c ? budget : budget-1));
/* try deleting c */
match(t1, w, s, budget-1);
}
/* try inserting *w */
match(t, w+1, s + *w, budget-1);
/* TRY SWAPPING FIRST TWO CHARACTERS */
if (w[1]){
swap(w[0], w[1]);
match(t, w, s, budget-1);
swap(w[0], w[1]);
}
}
Esto es para la búsqueda del diccionario en un trie, pero para hacer coincidir una sola palabra, es la misma idea. Estás haciendo rama y encuadernación, y en cualquier momento, puedes hacer cualquier cambio que quieras, siempre y cuando le des un costo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-05-23 11:55:13
Elimine las palabras duplicadas entre las dos cadenas y luego use Levenshtein.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2009-05-06 17:41:49
Creo que este es un excelente ejemplo para usar un motor de búsqueda de espacio vectorial .
En esta técnica, cada documento se convierte esencialmente en un vector con tantas dimensiones como hay palabras diferentes en todo el corpus; documentos similares ocupan áreas vecinas en ese espacio vectorial. una buena propiedad de este modelo es que las consultas también son solo documentos: para responder a una consulta, simplemente calcula su posición en el espacio vectorial, y sus resultados son los documentos más cercanos puedes encontrar. estoy seguro de que hay soluciones get-and-go para PHP por ahí.
Para difuminar los resultados del espacio vectorial, podría considerar hacer una técnica de procesamiento de lenguaje natural similar / stemming, y usar levenshtein para construir consultas secundarias para palabras similares que ocurren en su vocabulario general.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-08-07 20:57:56
Si la primera cadena es A y la segunda es B:
- Dividir A y B en palabras
- Para cada palabra en A, encuentre la palabra que mejor coincida en B (usando levenshtein)
- Elimine esa palabra de B y póngala en B* en el mismo índice que la palabra coincidente en A.
- Ahora compare A y B *
Ejemplo:
A: The quick brown fox
B: Quick blue fox the
B*: the Quick blue fox
Podría mejorar el paso 2 haciéndolo en múltiples pasadas, encontrando solo coincidencias exactas al principio, luego encontrando coincidencias cercanas para palabras en un que no tienes un compañero en B* todavía, luego menos partidos cercanos, etc.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-01-29 23:48:41