Diferencia entre las funciones MPI Allgather y MPI Alltoall?
¿Cuál es la principal diferencia entre las funciones MPI_Allgather y MPI_Alltoall en MPI?
Quiero decir, ¿puede alguien darme ejemplos donde MPI_Allgather será útil y MPI_Alltoall no? y viceversa.
No soy capaz de entender la diferencia principal? Parece que en ambos casos todos los procesos envían elementos send_cnt a todos los demás procesos que participan en el comunicador y los reciben?
Gracias
3 answers
Una imagen dice más de mil palabras, así que aquí hay varias imágenes de arte ASCII:
rank send buf recv buf
---- -------- --------
0 a,b,c MPI_Allgather a,b,c,A,B,C,#,@,%
1 A,B,C ----------------> a,b,c,A,B,C,#,@,%
2 #,@,% a,b,c,A,B,C,#,@,%
Esto es solo el MPI_Gather regular, solo en este caso todos los procesos reciben los trozos de datos, es decir, la operación es sin root.
rank send buf recv buf
---- -------- --------
0 a,b,c MPI_Alltoall a,A,#
1 A,B,C ----------------> b,B,@
2 #,@,% c,C,%
(a more elaborate case with two elements per process)
rank send buf recv buf
---- -------- --------
0 a,b,c,d,e,f MPI_Alltoall a,b,A,B,#,@
1 A,B,C,D,E,F ----------------> c,d,C,D,%,$
2 #,@,%,$,&,* e,f,E,F,&,*
(se ve mejor si cada elemento está coloreado por el rango que lo envía pero...)
MPI_Alltoall funciona como MPI_Scatter y MPI_Gather combinados: el búfer de envío en cada proceso se divide como en MPI_Scatter y luego cada columna de trozos se recopila proceso respectivo, cuyo rango coincide con el número de la columna chunk. MPI_Alltoall también puede verse como una operación de transposición global, que actúa sobre trozos de datos.
¿Hay un caso en el que las dos operaciones son intercambiables? Para responder correctamente a esta pregunta, uno tiene que analizar simplemente los tamaños de los datos en el búfer de envío y de los datos en el búfer de recepción:
operation send buf size recv buf size
--------- ------------- -------------
MPI_Allgather sendcnt n_procs * sendcnt
MPI_Alltoall n_procs * sendcnt n_procs * sendcnt
El tamaño del búfer de recepción es en realidad n_procs * recvcnt, pero MPI exige que el número de elementos básicos enviados ser igual al número de elementos básicos recibidos, por lo tanto si el mismo tipo de datos MPI se usa tanto en las partes de envío como en las de recepción de MPI_All..., entonces recvcnt debe ser igual a sendcnt.
Es inmediatamente obvio que para el mismo tamaño de los datos recibidos, la cantidad de datos enviados por cada proceso es diferente. Para que las dos operaciones sean iguales, una condición necesaria es que los tamaños de los búferes enviados en ambos casos sean iguales, es decir, n_procs * sendcnt == sendcnt, lo que solo es posible si n_procs == 1, es decir, si solo hay un proceso, o si sendcnt == 0, es decir, no se envía ningún dato. Por lo tanto, no existe un caso prácticamente viable en el que ambas operaciones sean realmente intercambiables. Pero se puede simular MPI_Allgather con MPI_Alltoall repitiendo n_procs veces los mismos datos en el búfer de envío (como ya señaló Tyler Gill). Aquí está la acción de MPI_Allgather con búferes de envío de un elemento:
rank send buf recv buf
---- -------- --------
0 a MPI_Allgather a,A,#
1 A ----------------> a,A,#
2 # a,A,#
Y aquí lo mismo implementado con MPI_Alltoall:
rank send buf recv buf
---- -------- --------
0 a,a,a MPI_Alltoall a,A,#
1 A,A,A ----------------> a,A,#
2 #,#,# a,A,#
Lo contrario no es posible-uno no puede simular la acción de MPI_Alltoall con MPI_Allgather en el caso general.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-02-24 15:40:02
Estas dos capturas de pantalla tienen una explicación rápida:
MPI_Allgatherv
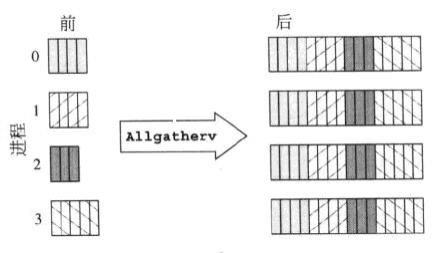
MPI_Alltoallv
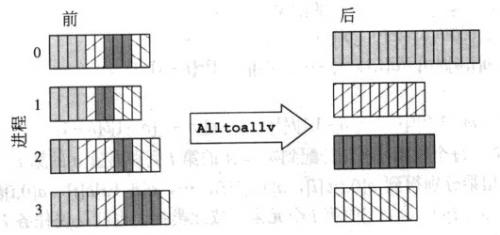
Aunque esto es una comparación entre MPI_Allgatherv y MPI_Alltoallv, también explica cómo MPI_Allgather difiere de MPI_Alltoall.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-12-06 02:49:02
Si bien estos dos métodos son de hecho muy similares, parece haber una diferencia crucial entre los dos.
MPI_Allgather termina con cada proceso teniendo exactamente los mismos datos en su búfer de recepción, y cada proceso contribuye con un solo valor a la matriz general. Por ejemplo, si cada uno de un conjunto de procesos necesitara compartir algún valor único sobre su estado con todos los demás, cada uno proporcionaría su valor único. Estos valores se enviarían a todos, para que todos tendría una copia de la misma estructura.
MPI_Alltoall no envía los mismos valores entre los procesos. En lugar de proporcionar un solo valor que debe compartirse entre los procesos, cada proceso especifica un valor para darse entre sí. En otras palabras, con n procesos, cada uno debe especificar n valores para compartir. Luego, para cada procesador j, su valor k'ésimo será enviado al índice j'ésimo de k del proceso en el buffer de recepción. Esto es útil si cada proceso tiene un único mensaje para el proceso del otro.
Como nota final, los resultados de ejecutar allgather y alltoall serían los mismos en el caso de que cada proceso llenara su buffer de envío con el mismo valor. La única diferencia sería que allgather probablemente sería mucho más eficiente.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-02-24 07:34:47