Diferencia entre HBase y Hadoop / HDFS
Esta es una pregunta ingenua, pero soy nuevo en el paradigma NoSQL y no sé mucho al respecto. Así que si alguien puede ayudarme a entender claramente la diferencia entre la HBase y Hadoop o si dar algunos consejos que podrían ayudarme a entender la diferencia.
Hasta ahora, he hecho algunas investigaciones y acc. a mi entender, Hadoop proporciona un marco para trabajar con fragmentos de datos sin procesar (archivos) en HDFS y HBase es el motor de base de datos por encima de Hadoop, que básicamente funciona con datos estructurados en lugar de raw fragmento de datos. Hbase proporciona una capa lógica sobre HDFS al igual que SQL. Es correcto?
Pls no dude en corregirme.
Gracias.
5 answers
Hadoop es básicamente 3 cosas, un FS (Hadoop Distributed File System), un marco de computación (MapReduce) y un puente de administración (Otro Negociador de Recursos). HDFS le permite almacenar grandes cantidades de datos de una manera distribuida (proporciona un acceso de lectura/escritura más rápido) y redundante (proporciona una mejor disponibilidad). Y MapReduce le permite procesar estos enormes datos de una manera distribuida y paralela. Pero MapReduce no se limita solo a HDFS. Al ser un FS, HDFS carece de la lectura/escritura aleatoria capacidad. Es bueno para el acceso secuencial de datos. Y aquí es donde HBase entra en escena. Es una base de datos NoSQL que se ejecuta en la parte superior de su clúster de Hadoop y le proporciona acceso aleatorio de lectura / escritura en tiempo real a sus datos.
Puede almacenar datos estructurados y no estructurados en Hadoop y HBase también. Ambos le proporcionan múltiples mecanismos para acceder a los datos, como el shell y otras API. Además, HBase almacena datos como pares clave/valor de forma columnar, mientras que HDFS almacena datos como archivos planos. Algunas de las características más destacadas de ambos sistemas son :
Hadoop
- Optimizado para el acceso de streaming de archivos de gran tamaño.
- Sigue escribir-una vez leído-muchas ideologías.
- No soporta lectura/escritura aleatoria.
HBase
- Almacena pares clave/valor en forma de columnas (las columnas se agrupan como familias de columnas).
- Proporciona acceso de baja latencia a pequeñas cantidades de datos desde dentro de datos grandes establecer.
- Proporciona un modelo de datos flexible.
Hadoop es más adecuado para el procesamiento por lotes fuera de línea, mientras que HBase se utiliza cuando tiene necesidades en tiempo real.
Una comparación análoga sería entre MySQL y Ext4.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-04-19 07:10:13
Apache Hadoop el proyecto incluye cuatro módulos clave
- Hadoop Common: Las utilidades comunes que soportan los otros módulos de Hadoop.
- Hadoop Distributed File System (HDFS™): Un sistema de archivos distribuido que proporciona acceso de alto rendimiento a los datos de la aplicación.
- Hadoop YARN: Un marco para la programación de trabajos y la gestión de recursos de clúster.
- Hadoop MapReduce : Un sistema basado en YARN para paralelo procesamiento de grandes conjuntos de datos.
HBase es una base de datos distribuida y escalable que admite el almacenamiento estructurado de datos para tablas grandes. Al igual que Bigtable aprovecha el almacenamiento de datos distribuido proporcionado por el Sistema de archivos de Google, Apache HBase proporciona capacidades similares a Bigtable además de Hadoop y HDFS.
Cuándo usar HBase:
- Si su aplicación tiene un esquema variable donde cada fila es ligeramente diferente
- Si usted encuentra que sus datos se almacenan en colecciones, todas ellas con el mismo valor
- Si necesita acceso aleatorio de lectura/escritura en tiempo real a su Big Data.
- Si necesita acceso basado en claves a los datos al almacenar o recuperar.
- Si tiene una gran cantidad de datos con el clúster de Hadoop existente
Pero HBase tiene algunas limitaciones
- No se puede usar para aplicaciones transaccionales clásicas ni para análisis relacionales.
- Tampoco es un sustituto completo para HDFS al hacer MapReduce de lotes grandes.
- No habla SQL, tiene un optimizador, admite transacciones de registros cruzados o uniones.
- No se puede usar con patrones de acceso complicados (como uniones)
Resumen:
Considere HBase cuando está cargando datos por clave, buscando datos por clave( o rango), sirviendo datos por clave, consultando datos por clave o cuando almacena datos por fila que no se ajustan bien a una esquema.
Echa un vistazo a Lo que hacer y no hacer de HBase desde el blog de cloudera.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-05-31 20:29:45
Hadoop utiliza el sistema de archivos distribuido, es decir, HDFS para almacenar bigdata.Pero hay ciertas limitaciones de HDFS y para superar estas limitaciones,las bases de datos NoSQL como HBase, Cassandra y Mongodb surgieron.
Hadoop solo puede realizar procesamiento por lotes, y los datos solo se accederán de manera secuencial. Eso significa que uno tiene que buscar todo el conjunto de datos incluso para el más simple de los trabajos.Un conjunto de datos enorme cuando se procesa resulta en otro conjunto de datos enorme, que también debería ser procesado secuencialmente. En este punto, se necesita una nueva solución para acceder a cualquier punto de datos en una sola unidad de tiempo (acceso aleatorio).
Al igual que todos los demás sistemas de archivos, HDFS nos proporciona almacenamiento, pero de una manera tolerante a fallos con alto rendimiento y menor riesgo de pérdida de datos(debido a la replicación).Pero , al ser un Sistema de archivos, HDFS carece de acceso aleatorio de lectura y escritura. Aquí es donde HBase entra en escena. Es una tienda de big data distribuida, escalable, modelada según BigTable de Google. Cassandra es algo similar a la hbase.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-11-23 05:08:27
Tanto HBase como HDFS en una imagen
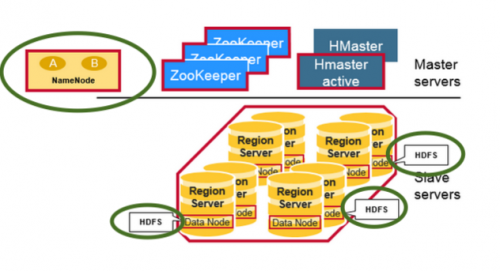
Nota:
Compruebe los demonios HDFS (Resaltados en verde) como DataNode (servidores de región colocados) y NameNode en el clúster con HBase y Hadoop HDFS
HDFS es un sistema de archivos distribuido que es muy adecuado para el almacenamiento de archivos grandes. que no proporciona búsquedas rápidas de registros individuales en archivos.
HBase, en el por otro lado, está construido sobre HDFS y proporciona búsquedas rápidas de registros (y actualizaciones) para tablas grandes. Esto a veces puede ser un punto de confusión conceptual. HBase coloca internamente sus datos en "StoreFiles" indexados que existen en HDFS para búsquedas de alta velocidad.
¿Cómo se ve esto?
Bueno, a nivel de infraestructura, cada máquina de ungüento en el cúmulo tiene demonios siguientes
- Servidor de región-HBase
- Nodo de datos - HDFS
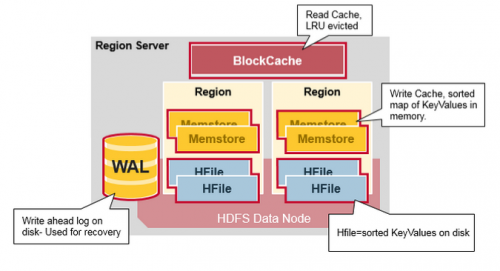
¿Cómo es rápido con las búsquedas?
HBase logra búsquedas rápidas en HDFS(a veces también en otros sistemas de archivos distribuidos) como almacenamiento subyacente, utilizando el siguiente modelo de datos
-
Cuadro
- Una tabla HBase consta de varias filas.
-
Fila
- Una fila en HBase consiste en una clave de fila y una o más columnas con valores asociados a ellas. Las filas están ordenadas alfabéticamente por la clave de fila a medida que se almacenan. Por esta razón, el diseño de la clave de fila es muy importante. El objetivo es almacenar datos de tal manera que las filas relacionadas estén cerca unas de otras. Un patrón de clave de fila común es un dominio de sitio web. Si sus claves de fila son dominios, probablemente debería almacenarlas en reversa (org.apache.www, org.apache.mail, org.apache.jira). De esta manera, todos los dominios de Apache están cerca uno del otro en la tabla, en lugar de estar repartidos en función de la primera letra del subdominio.
-
Columna
- Una columna en HBase consiste en una familia de columnas y un calificador de columna, que están delimitados por un carácter : (dos puntos).
-
Familia de columnas
- Las familias de columnas colocan físicamente un conjunto de columnas y sus valores, a menudo por razones de rendimiento. Cada familia de columnas tiene un conjunto de propiedades de almacenamiento, como si sus valores deben almacenarse en caché en la memoria, cómo se comprimen sus datos o su fila las claves están codificadas, y otros. Cada fila de una tabla tiene las mismas familias de columnas, aunque una fila dada podría no almacenar nada en una familia de columnas dada.
-
Calificador de columna
- Se agrega un calificador de columna a una familia de columnas para proporcionar el índice para un dato dado. Dado el contenido de una familia de columnas, un calificador de columna podría ser content: html, y otro podría ser content: pdf. Aunque las familias de columnas se fijan en la creación de la tabla, los calificadores de columna son mutable y puede diferir mucho entre filas.
-
Celda
- Una celda es una combinación de fila, familia de columnas y calificador de columna, y contiene un valor y una marca de tiempo, que representa la versión del valor.
-
Marca de tiempo
- Se escribe una marca de tiempo junto a cada valor, y es el identificador para una versión dada de un valor. De forma predeterminada, la marca de tiempo representa la hora en el RegionServer cuando se escribieron los datos, pero puede especificar un valor de marca de tiempo diferente cuando coloca datos en la celda.
Flujo de solicitud de lectura del cliente:
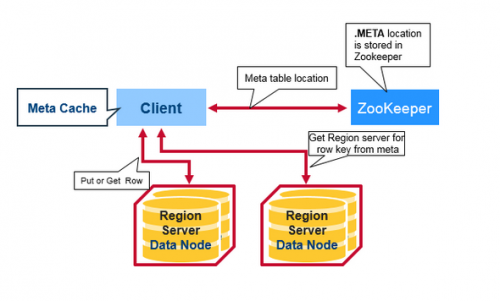
¿Qué es la tabla meta en la imagen de arriba?
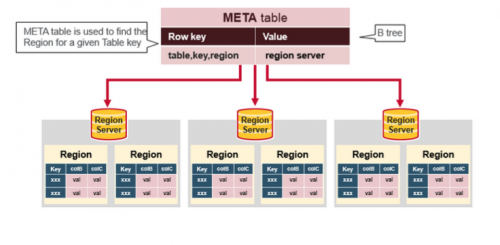
Después de toda la información, HBase read flow es para la búsqueda toca estas entidades
- Primero, el escáner busca las celdas de fila en la caché de bloque - la caché de lectura. Llave Leída Recientemente Los valores se almacenan en caché aquí,y Los Menos Utilizados Recientemente se desalojan cuando se necesita memoria.
- A continuación, el escáner busca en el MemStore, el caché de escritura en memoria que contiene las escrituras más recientes.
- Si el escáner no encuentra todas las celdas de fila en el MemStore y la Caché de bloques, HBase utilizará los índices de Caché de bloques y los filtros de bloom para cargar HFiles en la memoria, que puede contener las celdas de fila de destino.
Fuentes y más información:
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-09-14 07:24:13
Referencia: http://www.quora.com/What-is-the-difference-between-HBASE-and-HDFS-in-Hadoop
Hadoop es un nombre general para varios subsistemas: 1) HDFS. Un sistema de archivos distribuido que distribuye datos a través de un clúster de máquinas que se ocupan de la redundancia, etc 2) Mapa Reducir. Un sistema de gestión de trabajos sobre HDFS-para gestionar trabajos de reducción de mapas (y otros tipos) que procesan los datos almacenados en HDFS.
Básicamente significa que es un sistema sin conexión: almacena datos en HDFS y puede procesarlo ejecutando trabajos.
HBase por otro lado en una base de datos basada en columnas. Utiliza HDFS como almacenamiento, que se encarga de la copia de seguridad\redundancia \ etc, pero es una "tienda en línea", lo que significa que puede consultarlo para row\rows etc específico y obtener un valor inmediato.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-02-01 00:27:22