Comprender los histogramas de TensorBoard (peso)
Es realmente sencillo ver y entender los valores escalares en TensorBoard. Sin embargo, no está claro cómo entender los gráficos de histograma.
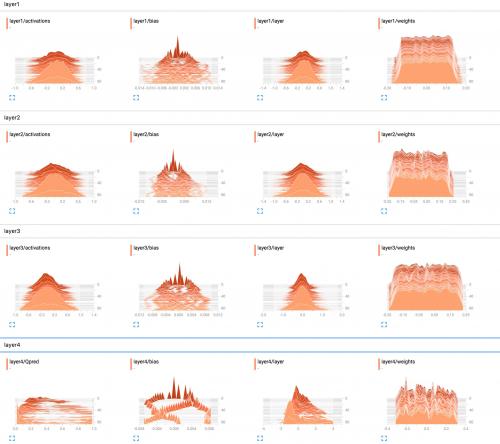
Por ejemplo, son los histogramas de mis pesos de red.
(Después de corregir un error gracias a sunside)
¿Cuál es la mejor manera de interpretarlos? Los pesos de la capa 1 se ven en su mayoría planos, ¿qué significa esto?
He añadido el código de construcción de la red aquí.
X = tf.placeholder(tf.float32, [None, input_size], name="input_x")
x_image = tf.reshape(X, [-1, 6, 10, 1])
tf.summary.image('input', x_image, 4)
# First layer of weights
with tf.name_scope("layer1"):
W1 = tf.get_variable("W1", shape=[input_size, hidden_layer_neurons],
initializer=tf.contrib.layers.xavier_initializer())
layer1 = tf.matmul(X, W1)
layer1_act = tf.nn.tanh(layer1)
tf.summary.histogram("weights", W1)
tf.summary.histogram("layer", layer1)
tf.summary.histogram("activations", layer1_act)
# Second layer of weights
with tf.name_scope("layer2"):
W2 = tf.get_variable("W2", shape=[hidden_layer_neurons, hidden_layer_neurons],
initializer=tf.contrib.layers.xavier_initializer())
layer2 = tf.matmul(layer1_act, W2)
layer2_act = tf.nn.tanh(layer2)
tf.summary.histogram("weights", W2)
tf.summary.histogram("layer", layer2)
tf.summary.histogram("activations", layer2_act)
# Third layer of weights
with tf.name_scope("layer3"):
W3 = tf.get_variable("W3", shape=[hidden_layer_neurons, hidden_layer_neurons],
initializer=tf.contrib.layers.xavier_initializer())
layer3 = tf.matmul(layer2_act, W3)
layer3_act = tf.nn.tanh(layer3)
tf.summary.histogram("weights", W3)
tf.summary.histogram("layer", layer3)
tf.summary.histogram("activations", layer3_act)
# Fourth layer of weights
with tf.name_scope("layer4"):
W4 = tf.get_variable("W4", shape=[hidden_layer_neurons, output_size],
initializer=tf.contrib.layers.xavier_initializer())
Qpred = tf.nn.softmax(tf.matmul(layer3_act, W4)) # Bug fixed: Qpred = tf.nn.softmax(tf.matmul(layer3, W4))
tf.summary.histogram("weights", W4)
tf.summary.histogram("Qpred", Qpred)
# We need to define the parts of the network needed for learning a policy
Y = tf.placeholder(tf.float32, [None, output_size], name="input_y")
advantages = tf.placeholder(tf.float32, name="reward_signal")
# Loss function
# Sum (Ai*logp(yi|xi))
log_lik = -Y * tf.log(Qpred)
loss = tf.reduce_mean(tf.reduce_sum(log_lik * advantages, axis=1))
tf.summary.scalar("Q", tf.reduce_mean(Qpred))
tf.summary.scalar("Y", tf.reduce_mean(Y))
tf.summary.scalar("log_likelihood", tf.reduce_mean(log_lik))
tf.summary.scalar("loss", loss)
# Learning
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
1 answers
Parece que la red no ha aprendido nada en las capas uno a tres. La última capa cambia, lo que significa que puede haber algo mal con los gradientes (si los manipulas manualmente), estás limitando el aprendizaje a la última capa optimizando solo sus pesos o la última capa realmente 'come' todo el error. También podría ser que solo se aprenden sesgos. La red parece aprender algo, sin embargo, pero podría no estar utilizando todo su potencial. Se necesitaría más contexto aquí, pero jugar con el ritmo de aprendizaje (por ejemplo, usar uno más pequeño) podría valer la pena intentarlo.
En general, los histogramas muestran el número de ocurrencias de un valor relativo entre sí. En pocas palabras, si los valores posibles están en un rango de 0..9 y ves un pico de cantidad 10 en el valor 0, esto significa que 10 entradas asumen el valor 0; en contraste, si el histograma muestra una meseta de 1 para todos los valores de 0..9, significa que para 10 entradas, cada valor posible 0..9ocurre exactamente una vez.
También puede usar histogramas para visualizar distribuciones de probabilidad cuando normalice todos los valores de histograma por su suma total; si lo hace, obtendrá intuitivamente la probabilidad con la que aparecerá un cierto valor (en el eje x) (en comparación con otras entradas).
Ahora para layer1/weights, la meseta significa que:
- la mayoría de los pesos están en el rango de -0.15 a 0.15
- es (en su mayoría) es igualmente probable que un peso tenga cualquiera de estos valores, es decir, están (casi) uniformemente distribuidos
Dicho de otra manera, casi el mismo número de pesos tienen los valores -0.15, 0.0, 0.15 y todo en el medio. Hay algunos pesos que tienen valores ligeramente más pequeños o más altos.
En resumen, esto simplemente parece que los pesos se han inicializado utilizando una distribución uniforme con media cero y rango de valores -0.15..0.15... más o menos. Si realmente usas uniforme inicialización, entonces esto es típico cuando la red aún no ha sido entrenada.
En comparación, layer1/activations forma una curva de campana (gaussiana): Los valores se centran alrededor de un valor específico, en este caso 0, pero también pueden ser mayores o menores que eso (igualmente probable, ya que es simétrico). La mayoría de los valores aparecen cerca de la media de 0, pero los valores van desde -0.8 a 0.8.
Asumo que el layer1/activations se toma como la distribución sobre todas las salidas de capa en un lote. Puede ver que los valores cambian con el tiempo.
El histograma de la capa 4 no me dice nada específico. Por la forma, solo muestra que algunos valores de peso alrededor -0.1, 0.05 y 0.25 tienden a ocurrir con una mayor probabilidad; una razón podría ser, que diferentes partes de cada neurona allí en realidad recoger la misma información y son básicamente redundantes. Esto puede significar que en realidad podría utilizar una red más pequeña o que su red tiene la potencial para aprender más características distintivas con el fin de evitar el sobreajuste. Sin embargo, estas son solo suposiciones.
También, como ya se indicó en los comentarios a continuación, agregue unidades de sesgo. Al dejarlos fuera, está forzosamente restringiendo su red a una solución posiblemente inválida.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-02-18 22:28:52