Compartir datos entre bases de datos SQL
Estoy tratando de resolver un problema, que por una vez, no creé.
Trabajo en un entorno con muchas aplicaciones web respaldadas por diferentes bases de datos en diferentes servidores.
Cada base de datos es bastante única en su diseño y aplicación, pero todavía hay datos comunes en cada uno que me gustaría abstraer. Cada base de datos, por ejemplo, tiene una tabla de proveedores, una tabla de usuarios, etc...
Me gustaría abstraer estos datos comunes a una sola base de datos, pero aún así dejar que el otras bases de datos se unen a estas tablas, incluso tienen claves para imponer restricciones, etc... Estoy en un entorno MsSql.
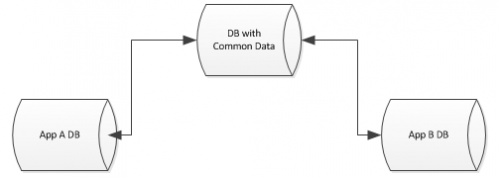
¿cuáles son las opciones disponibles? Como yo lo veo, tengo las siguientes opciones:
- Servidores vinculados
- Inicios de sesión de solo lectura para dar acceso a las vistas
¿Hay algo más que considerar?
5 answers
Hay muchas maneras de abordar este problema. Recomiendo encarecidamente cualquiera de las soluciones 1, 2 o 3 dependiendo de las necesidades de su negocio:
-
Replicación transaccional: Si la base de datos común es el registro de la cuenta y desea proporcionar versiones de solo lectura de los datos para aplicaciones separadas, entonces puede replicar las tablas principales, posiblemente incluso solo las columnas principales de tablas, a cada servidor separado. Una ventaja de este enfoque es que puede replicar a tantas bases de datos de suscriptores como desee. Esto también significa que puede personalizar qué tablas y campos están disponibles para los suscriptores en función de sus necesidades. Por lo tanto, si una aplicación necesita tablas de usuario y no tablas de proveedor, solo se suscribe a las tablas de usuario. Si otro solo necesita tablas de proveedor y no tablas de usuario, solo puede suscribirse a las tablas de proveedor. Otra ventaja es que la replicación se mantiene sincronizada y siempre puede reiniciar una suscripción si surge un problema.
He utilizado la replicación transaccional para enviar más de 100 tablas desde un almacén de datos para separar las aplicaciones posteriores que necesitaban acceso a datos agregados de varios sistemas. Dado que nuestro almacén de datos se actualizó en un horario programado desde fuentes de datos de envío mirror y log, las aplicaciones de producción tenían datos de numerosos sistemas dentro de una ventana deslizante de 20 a 80 minutos cada hora.
Replicación transaccional Peer-to-Peer como un el tipo de publicación puede ser más adecuado para el caso de uso que proporcionó. Esto puede ser muy útil si desea implementar cambios de esquema o replicación nodo por nodo. La replicación transaccional estándar tiene algunas limitaciones en esta área.
Los tipos de publicación de replicación de instantáneas tienen más latencia que las publicaciones transaccionales, pero es posible que desee considerarlo si un grado de latencia es aceptable.
Aunque mencionó que es una tienda de Microsoft SQL Server, tenga en cuenta otros RDBM tienen tecnologías similares. Dado que está hablando de MS SQL Server específicamente, tenga en cuenta que la replicación transaccional también le permite replicarse en bases de datos Oracle. Por lo tanto, si tiene algunos de estos en su organización, esta solución aún puede funcionar.
Un inconveniente del uso de la replicación transaccional es que si el servidor central se cae, puede comenzar a experimentar latencia con los datos en las copias posteriores de los objetos replicados. Si los objetos replicados (artículos) son realmente grandes y necesita reiniciar una mesa, entonces eso puede tomar mucho tiempo para hacerlo, también.
Mirrors: Si desea que la base de datos sea accesible casi en tiempo real en servidores descendentes, puede configurar hasta dos mirrors asychronous. He integrado los datos con una aplicación CRM de esta manera. Todas las lecturas vinieron de joins to the mirror. Todas las escrituras fueron empujadas a una cola de mensajes que luego aplicó los cambios al servidor central de producción. El la desventaja de este enfoque es que no puede crear más de 2 espejos asíncronos. No desea utilizar espejos síncronos para este propósito a menos que esté planeando utilizar los espejos para la recuperación ante desastres, también.
Sistemas de mensajería: Si espera tener numerosas aplicaciones separadas que necesitan datos de una sola base de datos central, entonces es posible que desee considerar los sistemas de mensajería empresarial como IBM Web Sphere, Microsoft BizTalk, Vitria, TIBCO, etc. Estos las aplicaciones se construyen específicamente para abordar este problema. Tienden a ser costosos y engorrosos de implementar y mantener, pero pueden ampliarse si tiene sistemas distribuidos globalmente o docenas de aplicaciones separadas que necesitan compartir datos hasta cierto punto.
-
Servidores vinculados : Suena como si ya hubieras pensado en este. Podría exponer los datos a través de servidores vinculados. No creo que esta sea una buena solución. Si realmente quieres ir por esta ruta, a continuación, considere la posibilidad de configurar un mirror asíncrono desde la base de datos central a otro servidor y, a continuación, configure las conexiones de servidor vinculadas al mirror. Esto al menos mitigará el riesgo de que una consulta de las aplicaciones web cause problemas de bloqueo o rendimiento con su base de datos de producción central.
IMO, los servidores vinculados tienden a ser un método peligroso para compartir datos para aplicaciones. Este enfoque todavía trata los datos como un ciudadano de segunda clase en su base de datos. Lleva a algunos hábitos de codificación bastante malos, particularmente porque sus desarrolladores pueden estar trabajando en diferentes servidores en diferentes idiomas con diferentes métodos de conexión. No sabes si alguien va a escribir una consulta verdaderamente henious contra tus datos principales. Si establece un estándar que requiere enviar una copia completa de los datos compartidos al servidor no principal, entonces no tiene que preocuparse de si un desarrollador escribe código incorrecto o no. Al menos desde la perspectiva de que su pobre código no jeapordize el rendimiento de otros sistemas bien escritos.
Hay muchos, muchos recursos por ahí que explican por qué el uso de servidores vinculados puede ser malo en este contexto. Una lista no exhaustiva de razones incluye: (a) la cuenta utilizada para el servidor vinculado debe tener permisos DBCC SHOW STATISTICS o las consultas no podrán hacer uso de las estadísticas existentes, (b) las sugerencias de consulta no pueden ser uesd a menos que se envíen como OPENQUERY, (c) los parámetros no se pueden pasar OPENQUERY, (d) el servidor no tiene suficientes estadísticas sobre el servidor vinculado, en consecuencia, crea planes de consulta bastante terribles, (e) los problemas de conectividad de red pueden causar fallas, (f) cualquiera de estos cinco problemas de rendimiento, y (g) el temido error de contexto SSPI al intentar autenticar las credenciales de windows active directory en un escenario de doble salto. Los servidores vinculados pueden ser útiles para algunos escenarios específicos, pero creando acceso a una base de datos central alrededor esta característica, aunque técnicamente posible, no se recomienda.
-
Proceso ETL masivo: Si un alto grado de latencia es aceptable para las aplicaciones web, entonces podría escribir procesos ETL masivos con SSIS (muchos enlaces buenos en esta pregunta de StackOverflow) que son ejecutados por trabajos de agente de SQL Server para mover datos entre servidores. También hay otras herramientas ETL alternativas como Informatica, Pentaho, etc., así que usa lo que funciona mejor para ti.
Esto no es un buena solución si necesita un bajo grado de latencia. He utilizado esta solución al sincronizar con una solución de CRM alojada de terceros para campos que podrían tolerar una alta latencia. Para los campos que no podían tolerar una alta latencia (datos básicos de creación de cuentas), nos basamos en la creación de registros duplicados en el CRM a través de llamadas de servicio web en el punto de generación de la cuenta.
Copias de seguridad y restauraciones nocturnas: Si sus datos pueden tolerar altos grados de latencia (hasta un día) y períodos de falta de disponibilidad, entonces usted podría copia de seguridad y restaurar la base de datos a través de entornos. Esta no es una buena solución para aplicaciones web que necesitan un tiempo de actividad del 100%. La idea es tomar una copia de seguridad de línea base, restaurarla a un nombre de restauración separado, luego cambiar el nombre de la base de datos original y la nueva tan pronto como la nueva esté lista para su uso. He visto esto hecho para algunas aplicaciones web internas, pero generalmente no recomiendo este enfoque. Eso es más adecuado para un desarrollo más bajo ambiente, no un ambiente de producción.
Log Shipping Secondaries: Puede configurar el registro de envío entre la primaria y cualquier número de secundarias. Esto es similar al proceso de copia de seguridad y restauración nocturna, excepto que puede actualizar la base de datos con más frecuencia. En un caso, esta solución se utilizó para exponer datos de uno de nuestros principales sistemas centrales para usuarios intermedios al cambiar entre dos destinatarios de envío de registros. Había otro servidor que apuntaba a las dos bases de datos y cambió entre ellas cada vez que la nueva estaba disponible. Realmente odio esta solución, pero la única vez que vi esta implementación satisfizo las necesidades del negocio.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-05-23 11:52:59
También podría considerar el uso de la replicación SQL Server integrada entre common data store y app DBs. Desde mi experiencia es muy adecuado para la transferencia de datos de dos vías, y hay una instancia de las tablas en cada base de datos que permite el uso de claves foráneas (no creo que los FKs sean posibles a través del servidor vinculado).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-05-04 06:09:02
Puede haber otras opciones, pero piensa que eres el camino correcto para la mejor opción con una combinación de servidores y vistas vinculados. Esto podría ser tan simple como crear una nueva base de datos, agregar dos servidores vinculados, configurar sus permisos y luego crear la vista necesaria.
Si sus objetivos son abstract out this common data to a single database but still let the other databases join on these tables, even have keys to enforce constraints entonces esta solución debería funcionar bien.
En el lado negativo, puede encontrarse con problemas de rendimiento con los servidores vinculados, por lo que si prevé que la base de datos obtenga una gran cantidad de tráfico entonces usted puede ser que desee mirar realmente moviendo los datos usando los métodos que Doug o mwebber sugirieron.
Si va a la ruta del servidor vinculado, le recomendaría leer en OPENQUERY. Hay un buen artículo sobre OPENQUERY vs 4 identificadores de parte aquí.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-05-06 19:17:04
Echa un vistazo a Microsoft Sync Framework. Tendrás que escribir una aplicación de sincronización, pero podría darte la flexibilidad que necesitas.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-05-04 07:35:30
Creo que debería echar un buen vistazo a la replicación, como muchas respuestas han indicado, especialmente en un entorno de alto TPS o desea esto en muchas tablas. Sin embargo, ofreceré algún código sobre cómo logro sus objetivos declarados en algunos de mis sistemas utilizando servidores vinculados, sinónimos y restricciones de verificación.
Me gustaría abstraer estos datos comunes en una sola base de datos, pero aún así permitir que las otras bases de datos se unan a estas tablas, incluso tener claves para hacer cumplir las restricciones, etc
Puede configurar una vista o sinónimo en sus bases de datos a una tabla común en un servidor vinculado (u otra base de datos local). Prefiero sinónimos si la vista hubiera sido select * from table de todos modos.
Un sinónimo de tabla le permitirá ejecutar DML en el elemento remoto si tiene permisos.
En este punto, sin embargo, no puede tener una clave foránea para su vista o sinónimo, pero podemos lograr algo similar con una restricción check.
Veamos algunos código:
create synonym MyCentralTable for MyLinkedServer.MyCentralDB.dbo.MyCentralTable
go
create function dbo.MyLocalTableFkConstraint (
@PK int
)
returns bit
as begin
declare @retVal bit
select @retVal = case when exists (
select null from MyCentralTable where PK = @PK
) then 1 else 0 end
return @retVal
end
go
create table MyLocalTable (
FK int check (dbo.MyLocalTableFKConstraint(FK) = 1)
)
go
-- Will fail: -1 not in MyLinkedServer.MyRemoteDatabase.dbo.MyCentralTable
insert into MyLocalTable select -1
-- Will succeed: RI on a remote table w/o triggers
insert into MyLocalTable select FK from MyCentralTable
Por supuesto, es importante tener en cuenta que no obtendrá un error si elimina un registro referenciado en su tabla central.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-05-06 20:17:23