Cómo seleccionar columnas de dataframe por regex
Tengo un dataframe en python pandas. La estructura del dataframe es la siguiente:
a b c d1 d2 d3
10 14 12 44 45 78
Me gustaría seleccionar las columnas que comienzan con d. ¿Hay una forma sencilla de lograr esto en python?
5 answers
Puede utilizar DataFrame.filter de esta manera:
import pandas as pd
df = pd.DataFrame(np.array([[2,4,4],[4,3,3],[5,9,1]]),columns=['d','t','didi'])
>>
d t didi
0 2 4 4
1 4 3 3
2 5 9 1
df.filter(regex=("d.*"))
>>
d didi
0 2 4
1 4 3
2 5 1
La idea es seleccionar columnas por regex
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-06-12 17:04:16
Use select:
import pandas as pd
df = pd.DataFrame([[10, 14, 12, 44, 45, 78]], columns=['a', 'b', 'c', 'd1', 'd2', 'd3'])
df.select(lambda col: col.startswith('d'), axis=1)
Resultado:
d1 d2 d3
0 44 45 78
Esta es una buena solución si no te sientes cómodo con las expresiones regulares.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-06-12 17:20:29
Puede usar una comprensión de lista para iterar sobre todos los nombres de columna en su DataFrame df y luego solo seleccionar aquellos que comienzan con 'd'.
df = pd.DataFrame({'a': {0: 10}, 'b': {0: 14}, 'c': {0: 12},
'd1': {0: 44}, 'd2': {0: 45}, 'd3': {0: 78}})
Use la comprensión de lista para iterar sobre las columnas en el dataframe y devolver sus nombres (c a continuación se muestra una variable local que representa el nombre de la columna).
>>> [c for c in df]
['a', 'b', 'c', 'd1', 'd2', 'd3']
Entonces solo seleccione aquellos que comienzan con 'd'.
>>> [c for c in df if c[0] == 'd'] # As an alternative to c[0], use c.startswith(...)
['d1', 'd2', 'd3']
Finalmente, pase esta lista de columnas a la DataFrame.
df[[c for c in df if c.startswith('d')]]
>>> df
d1 d2 d3
0 44 45 78
===========================================================================
TIMINGS (agregado en febrero de 2018 por los comentarios de devinbost que afirman que este método es lento...)
Primero, vamos a crear un dataframe con 30k columnas:
n = 10000
cols = ['{0}_{1}'.format(letters, number)
for number in range(n) for letters in ('d', 't', 'didi')]
df = pd.DataFrame(np.random.randn(3, n * 3), columns=cols)
>>> df.shape
(3, 30000)
>>> %timeit df[[c for c in df if c[0] == 'd']] # Simple list comprehension.
# 10 loops, best of 3: 16.4 ms per loop
>>> %timeit df[[c for c in df if c.startswith('d')]] # More 'pythonic'?
# 10 loops, best of 3: 29.2 ms per loop
>>> %timeit df.select(lambda col: col.startswith('d'), axis=1) # Solution of gbrener.
# 10 loops, best of 3: 21.4 ms per loop
>>> %timeit df.filter(regex=("d.*")) # Accepted solution.
# 10 loops, best of 3: 40 ms per loop
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-02-09 02:44:49
Especialmente en un conjunto de datos más grande, un enfoque vectorizado es en realidad MUCHO MÁS RÁPIDO ( por más de dos órdenes de magnitud) y es mucho más legible. Estoy proporcionando una captura de pantalla como prueba. (Nota: Excepto por las últimas líneas que escribí en la parte inferior para aclarar mi punto con un enfoque vectorizado , el otro código se derivó de la respuesta de @Alexander.)
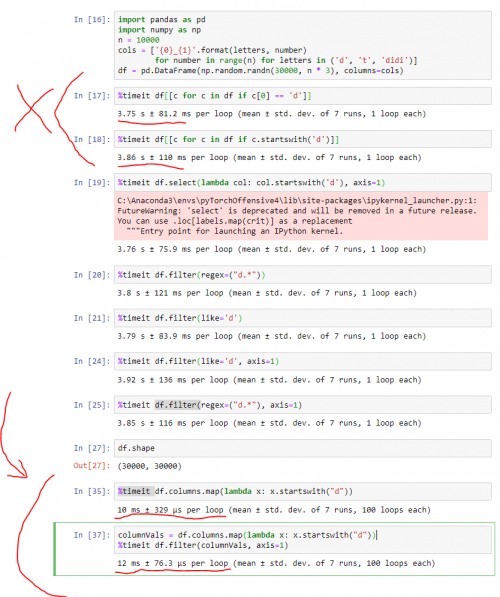
Aquí está ese código para referencia:
import pandas as pd
import numpy as np
n = 10000
cols = ['{0}_{1}'.format(letters, number)
for number in range(n) for letters in ('d', 't', 'didi')]
df = pd.DataFrame(np.random.randn(30000, n * 3), columns=cols)
%timeit df[[c for c in df if c[0] == 'd']]
%timeit df[[c for c in df if c.startswith('d')]]
%timeit df.select(lambda col: col.startswith('d'), axis=1)
%timeit df.filter(regex=("d.*"))
%timeit df.filter(like='d')
%timeit df.filter(like='d', axis=1)
%timeit df.filter(regex=("d.*"), axis=1)
%timeit df.columns.map(lambda x: x.startswith("d"))
columnVals = df.columns.map(lambda x: x.startswith("d"))
%timeit df.filter(columnVals, axis=1)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-09-03 21:01:39
También puedes usar
df.filter(regex='^d')
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-02-02 07:04:07