Cómo segmento un documento usando Tesseract y luego emito los cuadros delimitadores y etiquetas resultantes
Estoy intentando que Tesseract genere un archivo con cajas delimitadoras etiquetadas que resultan de la segmentación de páginas (pre OCR). Sé que debe ser capaz de hacer esto 'fuera de la caja' debido a los resultados mostrados en las competiciones ICDAR donde los concursantes tenían que segmentar y varios documentos (documento académico aquí). Aquí hay un ejemplo de ese documento que ilustra lo que quiero crear:

He construido la última versión de tesseract usando brew, brew install tesseract --HEAD, y he sido tratando de editar archivos de configuración ubicados en /usr/local/Cellar/tesseract/HEAD/share/tessdata/configs/ para generar cajas etiquetadas. La salida recibida usando hocr como configuración, es decir,
tesseract infile.tiff outfile_stem -l eng -psm 1 hocr
Da un cuadro delimitador para todo y tiene algún etiquetado en las etiquetas class, por ejemplo,
<p class='ocr_par' dir='ltr' id='par_5_82' title="bbox 2194 4490 3842 4589">
<span class='ocr_line' id='line_5_142' ...
Pero no puedo visualizar esto. ¿Hay una herramienta estándar para visualizar archivos hOCR, o es la facilidad para crear un archivo de salida con cajas delimitadoras integradas en Tesseract?
Los detalles de la versión actual de head:
tesseract 3.04.00
leptonica-1.71
libjpeg 8d : libpng 1.6.16 : libtiff 4.0.3 : zlib 1.2.5
Editar
Estoy realmente buscando lograr esto usando la herramienta de línea de comandos (como en los ejemplos anteriores). @nguyenq me ha señalado la referencia de API , desafortunadamente no tengo experiencia en c++. Si la única solución es usar la API, ¿puede proporcionar un ejemplo rápido de Python?
5 answers
Éxito. Muchas gracias a la gente de Pattern Recognition and Image Analysis Research Lab (PRImA) por producir herramientas para manejar esto. Puedes obtenerlos libremente en su sitio web o github.
A continuación presento la solución completa para un Mac que ejecuta 10.10 y utiliza el gestor de paquetes homebrew. Utilizo wine para ejecutar ejecutables de Windows.
Descripción general
- Herramientas de descarga: Tesseract OCR a la página (TPT) y Visor de páginas (PVT)
- Use el TPT para ejecutar tesseract en su documento y convierta el xml HOCR en un xml DE PÁGINA
- Utilice el PVT para ver la imagen original con la información xml de la PÁGINA superpuesta
Código
brew install wine # takes a little while >10m
brew install gs # only for generating a tif example. Not required, you can use Preview
brew install wget # only for downloading example paper. Not required, you can do so manually!
cd ~/Downloads
wget -O paper.pdf "http://www.prima.cse.salford.ac.uk/www/assets/papers/ICDAR2013_Antonacopoulos_HNLA2013.pdf"
# This command can be ommitted and you can do the conversion to tiff with Preview
gs \
-o paper-%d.tif \
-sDEVICE=tiff24nc \
-r300x300 \
paper.pdf
cd ~/Downloads
# ttptool is the location you downloaded the Tesseract to PAGE tool to
ttptool="/Users/Me/Project/tools/TesseractToPAGE 1.3"
# sudo chmod 777 "$ttptool/bin/PRImA_Tesseract-1-3-78.exe"
touch "$ttptool/log.txt"
wine "$ttptool/bin/PRImA_Tesseract-1-3-78.exe" \
-inp-img "$dl/Downloads/paper-3.tif" \
-out-xml "$dl/Downloads/paper-3-tool.xml" \
-rec-mode layout>>log.txt
# pvtool is the location you downloaded the PAGE Viewer tool to
pvtool="/Users/Me/Project/tools/PAGEViewerMacOS_1.1/JPageViewer 1.1 (Mac OS, 64 bit)"
cd "$pvtool"
dl=~
java -XstartOnFirstThread -jar JPageViewer.jar "$dl/Downloads/paper-3-tool.xml" "$dl/Downloads/paper-3.tif"
Resultados
Documento con superposiciones (rollover para ver texto y tipo)
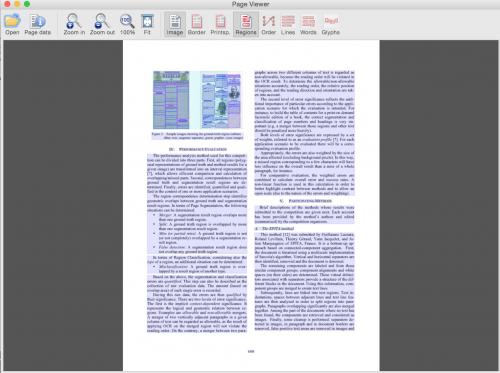 Superposiciones solas (usar botones GUI para alternar)
Superposiciones solas (usar botones GUI para alternar)
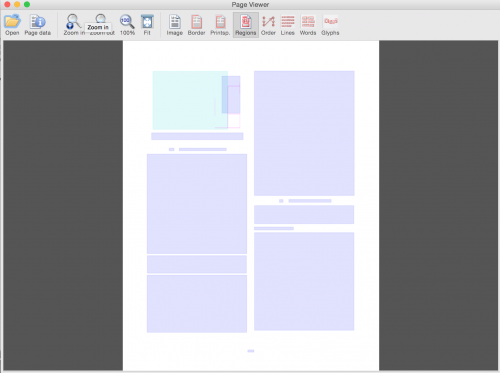
Apéndice
Puede ejecutar tesseract usted mismo y utilizar otra herramienta para convertir su salida a formato de PÁGINA. ¡No pude hacer que esto funcionara, pero estoy seguro de que estarás bien!
# Note that the pvtool does take as input HOCR xml but it ignores the region type
brew install tesseract --devel # installs v 3.03 at time of writing
tesseract ~/Downloads/paper-3.tif ~/Downloads/paper-3 hocr
mv paper-3.hocr paper-3.xml # The page viewer will only open XML files
java -XstartOnFirstThread -jar JPageViewer.jar "$dl/Downloads/paper-3.xml"
En este punto, debe usar la herramienta Java PAGE Converter para convertir el xml HOCR en un XML DE PÁGINA. Debería ir un poco algo como esto:
pctool="/Users/Me/Project/tools/JPageConverter 1.0"
java -jar "$pctool/PageConverter.jar" -source-xml paper-3.xml -target-xml paper-3-hocrconvert.xml -convert-to LATEST
Desafortunadamente, seguí recibiendo punteros nulos.
Could not convert to target XML schema format.
java.lang.NullPointerException
at org.primaresearch.dla.page.converter.PageConverter.run(PageConverter.java:126)
at org.primaresearch.dla.page.converter.PageConverter.main(PageConverter.java:65)
Could not save target PAGE XML file: paper-3-hocrconvert.xml
java.lang.NullPointerException
at org.primaresearch.dla.page.io.xml.XmlInputOutput.writePage(XmlInputOutput.java:144)
at org.primaresearch.dla.page.converter.PageConverter.run(PageConverter.java:135)
at org.primaresearch.dla.page.converter.PageConverter.main(PageConverter.java:65)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-09-20 23:36:54
Puede usar su API para obtener los cuadros delimitadores en varios niveles (carácter/palabra/línea/para) see ver Ejemplo de API. Tienes que dibujar las etiquetas tú mismo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-02-19 02:27:34
Acceso directo
También es posible abrir archivos HOCR directamente con la herramienta PageViewer. La extensión del archivo tiene que ser .xml, sin embargo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-02-23 09:42:00
Con Tesseract 4.0.0, un comando como tesseract source/dir/myimage.tiff target/directory/basefilename hocr creará un archivo basefilename.hocr con cajas delimitadoras a nivel de bloque, párrafo, línea y palabra para el texto OCR'ed. Incluso el comando sin la configuración hocr crea un archivo de texto con nuevas líneas entre el texto a nivel de bloque, pero el formato hocr es más explícito.
Más opciones de configuración aquí: https://github.com/tesseract-ocr/tesseract/tree/master/tessdata/configs
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-12-09 19:35:04
La forma más sencilla de tener un archivo HOCR con el nivel de carácter individual es usar la bifurcación de nickjwhite de Tesseract 3.05: https://github.com/nickjwhite/tesseract/tree/hocrcharboxes
Compile y descargue archivos tessdata siguiendo la wiki de Tesseract. Una vez realizada la comprobación de instalación, utilice:
tesseract {image file} -c tessedit_create_hocr=1 -c hocr_char_boxes=1 {output name}
Y tadam !
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-07-31 10:08:15