Cómo ordeno archivos muy grandes
Tengo algunos archivos que deben ordenarse según id al principio de cada línea. Los archivos son de aproximadamente 2-3 gb.
Traté de leer todos los datos en un ArrayList y ordenarlos. Pero la memoria no es suficiente para mantenerlos a todos. No funciona.
Las líneas se parecen a
0052304 0000004000000000000000000000000000000041 John Teddy 0000230022024 0000004000000000000000000000000000000041 George Clan 00013
¿Cómo puedo ordenar los archivos??
8 answers
Eso no es exactamente un problema de Java. Debe buscar un algoritmo eficiente para ordenar los datos que no se leen completamente en la memoria. Algunas adaptaciones a Merge-Sort pueden lograr esto.
Echa un vistazo a esto: http://en.wikipedia.org/wiki/Merge_sort
Y: http://en.wikipedia.org/wiki/External_sorting
Básicamente, la idea aquí es dividir el archivo en trozos más pequeños, ordenarlos (ya sea con merge sort u otro método), y luego usar el Merge from merge-sort para crear el nuevo archivo ordenado.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-10-27 15:15:12
Necesita una ordenación de fusión externa para hacer eso. Aquí es una implementación de Java que ordena archivos muy grandes.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-07-16 05:52:13
Dado que sus registros ya están en formato de texto de archivo plano, puede canalizarlos a UNIX sort(1), por ejemplo sort -n -t' ' -k1,1 < input > output. Automáticamente dividirá los datos y llevará a cabo una ordenación combinada utilizando la memoria disponible y /tmp. Si necesita más espacio del que tiene memoria disponible, agregue -T /tmpdir al comando.
Es bastante gracioso que todo el mundo te esté diciendo que descargues enormes bibliotecas de C # o Java o que implementes merge-sort tú mismo cuando puedes usar una herramienta que está disponible en todas las plataformas y ha existido durante décadas.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-08-17 17:53:44
En lugar de cargar todos los datos en la memoria a la vez, puede leer solo las teclas y un índice de dónde comienza la línea (y posiblemente la longitud también), por ejemplo,
class Line {
int key, length;
long start;
}
Esto usaría alrededor de 40 bytes por línea.
Una vez que haya ordenado esta matriz, puede usar RandomAccessFile para leer las líneas en el orden en que aparecen.
Nota: dado que golpeará aleatoriamente el disco, en lugar de usar memoria, esto podría ser muy lento. Un disco típico tarda 8 ms en acceder aleatoriamente datos y si tienes 10 millones de líneas esto tomará alrededor de un día. (Este es el peor caso absoluto) En la memoria tomaría unos 10 segundos.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2011-10-27 15:31:11
Puede usar SQL Lite file db, cargar los datos en la base de datos y luego dejar que ordene y devuelva los resultados por usted.
Ventajas: No hay necesidad de preocuparse por escribir el mejor algoritmo de ordenación.
Desventaja: Necesitará espacio en disco, procesamiento más lento.
Https://sites.google.com/site/arjunwebworld/Home/programming/sorting-large-data-files
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-02-14 11:00:11
Lo que debe hacer es dividir los archivos a través de una secuencia y procesarlos por separado. Luego puede fusionar los archivos ya que ya se ordenarán, esto es similar a cómo funciona merge sort.
La respuesta de esta pregunta SO será de valor: Stream large files
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-05-23 11:55:07
Los sistemas operativos vienen con una potente utilidad de clasificación de archivos. Una función simple que llame a un script bash debería ayudar.
public static void runScript(final Logger log, final String scriptFile) throws IOException, InterruptedException {
final String command = scriptFile;
if (!new File (command).exists() || !new File(command).canRead() || !new File(command).canExecute()) {
log.log(Level.SEVERE, "Cannot find or read " + command);
log.log(Level.WARNING, "Make sure the file is executable and you have permissions to execute it. Hint: use \"chmod +x filename\" to make it executable");
throw new IOException("Cannot find or read " + command);
}
final int returncode = Runtime.getRuntime().exec(new String[] {"bash", "-c", command}).waitFor();
if (returncode!=0) {
log.log(Level.SEVERE, "The script returned an Error with exit code: " + returncode);
throw new IOException();
}
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-07-19 11:47:45
Necesita realizar una ordenación externa. Es la idea impulsora detrás de Hadoop / MapReduce, solo que no tiene en cuenta el clúster distribuido y funciona en un solo nodo.
Para un mejor rendimiento, debe usar Hadoop/Spark.
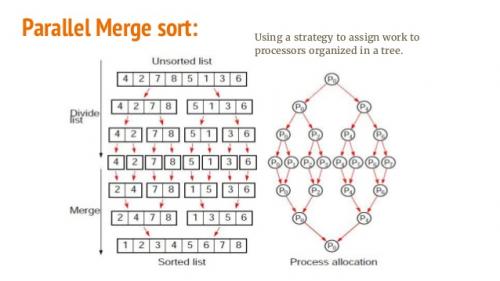 Cambie estas líneas según su sistema .
Cambie estas líneas según su sistema . fpath es su único archivo de entrada grande (probado con 20 GB). shared path es donde se almacena el registro de ejecución. fdir es donde se almacenarán y fusionarán los archivos intermedios. Cambie estas rutas de acuerdo con su máquina.
public static final String fdir = "/tmp/";
public static final String shared = "/exports/home/schatterjee/cs553-pa2a/";
public static final String fPath = "/input/data-20GB.in";
public static final String opLog = shared+"Mysort20GB.log";
Luego ejecute el siguiente programa. Su archivo ordenado final se creará con el nombre op401 en fdir path. la última línea Runtime.getRuntime().exec("valsort " + fdir + "op" + (treeHeight*100)+1 + " > " + opLog); comprueba que la salida está ordenada o no . Elimine esta línea si no tiene valsort instalado o el archivo de entrada no se genera usando gensort (http://www.ordinal.com/gensort.html) .
Tampoco olvides cambiar int totalLines = 200000000; a las líneas totales en tu archivo. y el número de hilos (int threadCount = 16) debe ser siempre en potencia de 2 y lo suficientemente grande como para que (tamaño total * 2 / no de hilo) cantidad de datos puede residir en la memoria. Cambiar el número de subprocesos cambiará el nombre del archivo de salida final. Como para 16, será op401, para 32 será op501, para 8 será op301, etc.
Disfruta.
import java.io.*;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.stream.Stream;
class SplitFile extends Thread {
String fileName;
int startLine, endLine;
SplitFile(String fileName, int startLine, int endLine) {
this.fileName = fileName;
this.startLine = startLine;
this.endLine = endLine;
}
public static void writeToFile(BufferedWriter writer, String line) {
try {
writer.write(line + "\r\n");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public void run() {
try {
BufferedWriter writer = Files.newBufferedWriter(Paths.get(fileName));
int totalLines = endLine + 1 - startLine;
Stream<String> chunks =
Files.lines(Paths.get(Mysort20GB.fPath))
.skip(startLine - 1)
.limit(totalLines)
.sorted(Comparator.naturalOrder());
chunks.forEach(line -> {
writeToFile(writer, line);
});
System.out.println(" Done Writing " + Thread.currentThread().getName());
writer.close();
} catch (Exception e) {
System.out.println(e);
}
}
}
class MergeFiles extends Thread {
String file1, file2, file3;
MergeFiles(String file1, String file2, String file3) {
this.file1 = file1;
this.file2 = file2;
this.file3 = file3;
}
public void run() {
try {
System.out.println(file1 + " Started Merging " + file2 );
FileReader fileReader1 = new FileReader(file1);
FileReader fileReader2 = new FileReader(file2);
FileWriter writer = new FileWriter(file3);
BufferedReader bufferedReader1 = new BufferedReader(fileReader1);
BufferedReader bufferedReader2 = new BufferedReader(fileReader2);
String line1 = bufferedReader1.readLine();
String line2 = bufferedReader2.readLine();
//Merge 2 files based on which string is greater.
while (line1 != null || line2 != null) {
if (line1 == null || (line2 != null && line1.compareTo(line2) > 0)) {
writer.write(line2 + "\r\n");
line2 = bufferedReader2.readLine();
} else {
writer.write(line1 + "\r\n");
line1 = bufferedReader1.readLine();
}
}
System.out.println(file1 + " Done Merging " + file2 );
new File(file1).delete();
new File(file2).delete();
writer.close();
} catch (Exception e) {
System.out.println(e);
}
}
}
public class Mysort20GB {
//public static final String fdir = "/Users/diesel/Desktop/";
public static final String fdir = "/tmp/";
public static final String shared = "/exports/home/schatterjee/cs553-pa2a/";
public static final String fPath = "/input/data-20GB.in";
public static final String opLog = shared+"Mysort20GB.log";
public static void main(String[] args) throws Exception{
long startTime = System.nanoTime();
int threadCount = 16; // Number of threads
int totalLines = 200000000;
int linesPerFile = totalLines / threadCount;
ArrayList<Thread> activeThreads = new ArrayList<Thread>();
for (int i = 1; i <= threadCount; i++) {
int startLine = i == 1 ? i : (i - 1) * linesPerFile + 1;
int endLine = i * linesPerFile;
SplitFile mapThreads = new SplitFile(fdir + "op" + i, startLine, endLine);
activeThreads.add(mapThreads);
mapThreads.start();
}
activeThreads.stream().forEach(t -> {
try {
t.join();
} catch (Exception e) {
}
});
int treeHeight = (int) (Math.log(threadCount) / Math.log(2));
for (int i = 0; i < treeHeight; i++) {
ArrayList<Thread> actvThreads = new ArrayList<Thread>();
for (int j = 1, itr = 1; j <= threadCount / (i + 1); j += 2, itr++) {
int offset = i * 100;
String tempFile1 = fdir + "op" + (j + offset);
String tempFile2 = fdir + "op" + ((j + 1) + offset);
String opFile = fdir + "op" + (itr + ((i + 1) * 100));
MergeFiles reduceThreads =
new MergeFiles(tempFile1,tempFile2,opFile);
actvThreads.add(reduceThreads);
reduceThreads.start();
}
actvThreads.stream().forEach(t -> {
try {
t.join();
} catch (Exception e) {
}
});
}
long endTime = System.nanoTime();
double timeTaken = (endTime - startTime)/1e9;
System.out.println(timeTaken);
BufferedWriter logFile = new BufferedWriter(new FileWriter(opLog, true));
logFile.write("Time Taken in seconds:" + timeTaken);
Runtime.getRuntime().exec("valsort " + fdir + "op" + (treeHeight*100)+1 + " > " + opLog);
logFile.close();
}
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-04-15 21:06:06