Cómo optimizar shuffle spill en la aplicación Apache Spark
Estoy ejecutando una aplicación de transmisión de Spark con 2 trabajadores. La solicitud tiene una afiliación y un sindicato de operaciones.
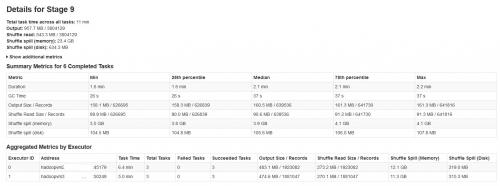
Todos los lotes se están completando con éxito, pero notó que las métricas de derrame aleatorio no son consistentes con el tamaño de los datos de entrada o el tamaño de los datos de salida (la memoria de derrame es más de 20 veces).
Por favor, encuentre los detalles de la etapa spark en la siguiente imagen:
Después de investigar sobre esto, encontró que
Shuffle derrame ocurre cuando no hay suficiente memoria para barajar datos.
Shuffle spill (memory) - tamaño de la forma deserializada de los datos en memoria en el momento del derrame
shuffle spill (disk) - tamaño de la forma serializada de los datos en el disco después de derramar
Dado que los datos deserializados ocupan más espacio que los datos serializados. Por lo tanto, Shuffle derrame (memoria) es más.
Notó que este tamaño de memoria de derrame es increíblemente grande con grandes datos de entrada.
Mis consultas son:
¿Este derrame afecta a la rendimiento considerablemente?
¿Cómo optimizar este derrame tanto de memoria como de disco?
¿Hay propiedades de chispa que puedan reducir/ controlar este enorme derrame?
1 answers
Aprender a ajustar el rendimiento de Spark requiere un poco de investigación y aprendizaje. Hay algunos buenos recursos incluyendo este video. Spark 1.4 tiene algunos mejores diagnósticos y visualización en la interfaz que puede ayudarlo.
En resumen, se derrama cuando el tamaño de las particiones RDD al final de la etapa excede la cantidad de memoria disponible para el búfer aleatorio.
Puedes:
- Manualmente
repartition()su etapa anterior para que tenga particiones más pequeñas de la entrada. - Aumente el búfer aleatorio aumentando la memoria en sus procesos ejecutores(
spark.executor.memory) - Aumente el búfer aleatorio aumentando la fracción de memoria del ejecutor asignada a él (
spark.shuffle.memoryFraction) desde el valor predeterminado de 0.2. Necesitas devolverspark.storage.memoryFraction. - Aumentar el búfer de mezcla por hilo reduciendo la relación de hilos de trabajo (
SPARK_WORKER_CORES) a la memoria del ejecutor
Si hay un experto escuchando, me encantaría saber más sobre cómo interactúan los ajustes de memoryFraction y su rango razonable.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-06-12 11:30:11