¿Cómo hacer vlookup y rellenar (como en Excel) en R?
Tengo un conjunto de datos sobre 105000 filas y 30 columnas. Tengo una variable categórica que me gustaría asignarla a un número. En Excel, probablemente haría algo con VLOOKUP y fill.
¿Cómo haría yo lo mismo en R?
Esencialmente, lo que tengo es una variable HouseType, y necesito calcular la HouseTypeNo. Aquí hay algunos datos de muestra:
HouseType HouseTypeNo
Semi 1
Single 2
Row 3
Single 2
Apartment 4
Apartment 4
Row 3
8 answers
Si entiendo su pregunta correctamente, aquí hay cuatro métodos para hacer el equivalente de Excel VLOOKUP y rellenar usando R:
# load sample data from Q
hous <- read.table(header = TRUE,
stringsAsFactors = FALSE,
text="HouseType HouseTypeNo
Semi 1
Single 2
Row 3
Single 2
Apartment 4
Apartment 4
Row 3")
# create a toy large table with a 'HouseType' column
# but no 'HouseTypeNo' column (yet)
largetable <- data.frame(HouseType = as.character(sample(unique(hous$HouseType), 1000, replace = TRUE)), stringsAsFactors = FALSE)
# create a lookup table to get the numbers to fill
# the large table
lookup <- unique(hous)
HouseType HouseTypeNo
1 Semi 1
2 Single 2
3 Row 3
5 Apartment 4
Aquí hay cuatro métodos para llenar el HouseTypeNo en el largetable usando los valores en la tabla lookup:
Primero con merge en base:
# 1. using base
base1 <- (merge(lookup, largetable, by = 'HouseType'))
Un segundo método con vectores nombrados en base:
# 2. using base and a named vector
housenames <- as.numeric(1:length(unique(hous$HouseType)))
names(housenames) <- unique(hous$HouseType)
base2 <- data.frame(HouseType = largetable$HouseType,
HouseTypeNo = (housenames[largetable$HouseType]))
Tercero, usando el paquete plyr:
# 3. using the plyr package
library(plyr)
plyr1 <- join(largetable, lookup, by = "HouseType")
Cuarto, usando el paquete sqldf
# 4. using the sqldf package
library(sqldf)
sqldf1 <- sqldf("SELECT largetable.HouseType, lookup.HouseTypeNo
FROM largetable
INNER JOIN lookup
ON largetable.HouseType = lookup.HouseType")
Si es posible que algunos tipos de casa en largetable no existen en lookup entonces se usaría una combinación izquierda:
sqldf("select * from largetable left join lookup using (HouseType)")
Los cambios correspondientes a las otras soluciones también serían necesarios.
¿Es eso lo que querías hacer? Déjame saber qué método te gusta y voy a añadir comentarios.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-06-11 04:47:42
Creo que también puedes usar match():
largetable$HouseTypeNo <- with(lookup,
HouseTypeNo[match(largetable$HouseType,
HouseType)])
Esto todavía funciona si revuelvo el orden de lookup.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-10-20 20:34:29
También me gusta usar qdapTools::lookup u operador binario abreviado %l%. Funciona de manera idéntica a un vlookup de Excel, pero acepta argumentos de nombre opuestos a los números de columna
## Replicate Ben's data:
hous <- structure(list(HouseType = c("Semi", "Single", "Row", "Single",
"Apartment", "Apartment", "Row"), HouseTypeNo = c(1L, 2L, 3L,
2L, 4L, 4L, 3L)), .Names = c("HouseType", "HouseTypeNo"),
class = "data.frame", row.names = c(NA, -7L))
largetable <- data.frame(HouseType = as.character(sample(unique(hous$HouseType),
1000, replace = TRUE)), stringsAsFactors = FALSE)
## It's this simple:
library(qdapTools)
largetable[, 1] %l% hous
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-11-03 20:51:29
La solución # 2 de la respuesta de @Ben no es reproducible en otros ejemplos más genéricos. Sucede que da la búsqueda correcta en el ejemplo porque el único HouseType en houses aparece en orden creciente. Prueba esto:
hous <- read.table(header = TRUE, stringsAsFactors = FALSE, text="HouseType HouseTypeNo
Semi 1
ECIIsHome 17
Single 2
Row 3
Single 2
Apartment 4
Apartment 4
Row 3")
largetable <- data.frame(HouseType = as.character(sample(unique(hous$HouseType), 1000, replace = TRUE)), stringsAsFactors = FALSE)
lookup <- unique(hous)
Bens solución#2 da
housenames <- as.numeric(1:length(unique(hous$HouseType)))
names(housenames) <- unique(hous$HouseType)
base2 <- data.frame(HouseType = largetable$HouseType,
HouseTypeNo = (housenames[largetable$HouseType]))
Que {cuando[10]}
unique(base2$HouseTypeNo[ base2$HouseType=="ECIIsHome" ])
[1] 2
Cuando la respuesta correcta es 17 de la tabla de búsqueda
La forma correcta de hacerlo es
hous <- read.table(header = TRUE, stringsAsFactors = FALSE, text="HouseType HouseTypeNo
Semi 1
ECIIsHome 17
Single 2
Row 3
Single 2
Apartment 4
Apartment 4
Row 3")
largetable <- data.frame(HouseType = as.character(sample(unique(hous$HouseType), 1000, replace = TRUE)), stringsAsFactors = FALSE)
housenames <- tapply(hous$HouseTypeNo, hous$HouseType, unique)
base2 <- data.frame(HouseType = largetable$HouseType,
HouseTypeNo = (housenames[largetable$HouseType]))
Ahora las búsquedas se realizan correctamente
unique(base2$HouseTypeNo[ base2$HouseType=="ECIIsHome" ])
ECIIsHome
17
Traté de editar Bens responde pero es rechazada por razones que no puedo entender.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-12-09 19:08:47
Empezando por:
houses <- read.table(text="Semi 1
Single 2
Row 3
Single 2
Apartment 4
Apartment 4
Row 3",col.names=c("HouseType","HouseTypeNo"))
... puede usar
as.numeric(factor(houses$HouseType))
... para dar un número único para cada tipo de casa. Puedes ver el resultado aquí:
> houses2 <- data.frame(houses,as.numeric(factor(houses$HouseType)))
> houses2
HouseType HouseTypeNo as.numeric.factor.houses.HouseType..
1 Semi 1 3
2 Single 2 4
3 Row 3 2
4 Single 2 4
5 Apartment 4 1
6 Apartment 4 1
7 Row 3 2
... así que terminas con diferentes números en las filas (porque los factores están ordenados alfabéticamente) pero el mismo patrón.
(EDITAR: el texto restante en esta respuesta es en realidad redundante. Se me ocurrió comprobar y resultó que read.table() ya había hecho las casas de$HouseType en un factor cuando se leyó en el dataframe en primer lugar).
Sin embargo, puede ser mejor convertir HouseType a un factor, lo que le daría los mismos beneficios que HouseTypeNo, pero sería más fácil de interpretar porque los tipos de casa son nombrados en lugar de numerados, por ejemplo:
> houses3 <- houses
> houses3$HouseType <- factor(houses3$HouseType)
> houses3
HouseType HouseTypeNo
1 Semi 1
2 Single 2
3 Row 3
4 Single 2
5 Apartment 4
6 Apartment 4
7 Row 3
> levels(houses3$HouseType)
[1] "Apartment" "Row" "Semi" "Single"
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-03-08 21:38:17
El poster no preguntó acerca de buscar valores si exact=FALSE, pero estoy agregando esto como una respuesta para mi propia referencia y posiblemente otros.
Si estás buscando valores categóricos, usa las otras respuestas.
El vlookup de Excel también le permite hacer coincidir aproximadamente los valores numéricos con el 4to argumento(1) match=TRUE. Pienso en match=TRUE como buscar valores en un termómetro. El valor predeterminado es FALSE, que es perfecto para valores categóricos.
Si quieres coincidir aproximadamente (realizar una búsqueda), R tiene una función llamada findInterval, que (como su nombre lo indica) encontrará el intervalo / bin que contiene su valor numérico continuo.
Sin embargo, digamos que desea findInterval para varios valores. Puedes escribir un bucle o usar una función apply. Sin embargo, he encontrado que es más eficiente tomar un enfoque vectorizado DIY.
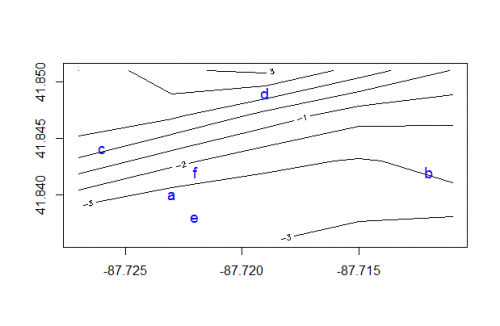
Digamos que tienes una cuadrícula de valores indexados por x e y:
grid <- list(x = c(-87.727, -87.723, -87.719, -87.715, -87.711),
y = c(41.836, 41.839, 41.843, 41.847, 41.851),
z = (matrix(data = c(-3.428, -3.722, -3.061, -2.554, -2.362,
-3.034, -3.925, -3.639, -3.357, -3.283,
-0.152, -1.688, -2.765, -3.084, -2.742,
1.973, 1.193, -0.354, -1.682, -1.803,
0.998, 2.863, 3.224, 1.541, -0.044),
nrow = 5, ncol = 5)))
Y tienes algunos valores que quiere buscar por x e y:
df <- data.frame(x = c(-87.723, -87.712, -87.726, -87.719, -87.722, -87.722),
y = c(41.84, 41.842, 41.844, 41.849, 41.838, 41.842),
id = c("a", "b", "c", "d", "e", "f")
Aquí está el ejemplo visualizado:
contour(grid)
points(df$x, df$y, pch=df$id, col="blue", cex=1.2)
Puede encontrar los intervalos x e intervalos y con este tipo de fórmula:
xrng <- range(grid$x)
xbins <- length(grid$x) -1
yrng <- range(grid$y)
ybins <- length(grid$y) -1
df$ix <- trunc( (df$x - min(xrng)) / diff(xrng) * (xbins)) + 1
df$iy <- trunc( (df$y - min(yrng)) / diff(yrng) * (ybins)) + 1
Podría ir un paso más allá y realizar una interpolación (simplista) en los valores z en grid de la siguiente manera:
df$z <- with(df, (grid$z[cbind(ix, iy)] +
grid$z[cbind(ix + 1, iy)] +
grid$z[cbind(ix, iy + 1)] +
grid$z[cbind(ix + 1, iy + 1)]) / 4)
Que le da estos valores:
contour(grid, xlim = range(c(grid$x, df$x)), ylim = range(c(grid$y, df$y)))
points(df$x, df$y, pch=df$id, col="blue", cex=1.2)
text(df$x + .001, df$y, lab=round(df$z, 2), col="blue", cex=1)
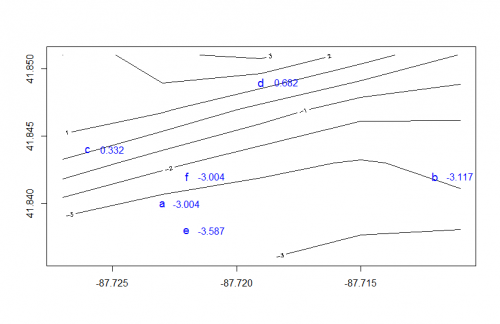
df
# x y id ix iy z
# 1 -87.723 41.840 a 2 2 -3.00425
# 2 -87.712 41.842 b 4 2 -3.11650
# 3 -87.726 41.844 c 1 3 0.33150
# 4 -87.719 41.849 d 3 4 0.68225
# 6 -87.722 41.838 e 2 1 -3.58675
# 7 -87.722 41.842 f 2 2 -3.00425
Tenga en cuenta que ix, y iy también podrían haber sido encontrados con un bucle usando findInterval, por ejemplo, aquí hay un ejemplo para la segunda fila
findInterval(df$x[2], grid$x)
# 4
findInterval(df$y[2], grid$y)
# 2
Que coincide con ix y {[17] {} en[18]}
Nota al pie: (1) El cuarto argumento de vlookup se llamaba anteriormente "match", pero después de que introdujeron la cinta fue renombrado a "[range_lookup]".
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-12-11 18:04:34
Puede usar mapvalues() desde el paquete plyr.
Datos Iniciales:
dat <- data.frame(HouseType = c("Semi", "Single", "Row", "Single", "Apartment", "Apartment", "Row"))
> dat
HouseType
1 Semi
2 Single
3 Row
4 Single
5 Apartment
6 Apartment
7 Row
Tabla de búsqueda / paso de peatones:
lookup <- data.frame(type_text = c("Semi", "Single", "Row", "Apartment"), type_num = c(1, 2, 3, 4))
> lookup
type_text type_num
1 Semi 1
2 Single 2
3 Row 3
4 Apartment 4
Crea la nueva variable:
dat$house_type_num <- plyr::mapvalues(dat$HouseType, from = lookup$type_text, to = lookup$type_num)
O para reemplazos simples, puede omitir la creación de una tabla de búsqueda larga y hacer esto directamente en un solo paso:
dat$house_type_num <- plyr::mapvalues(dat$HouseType,
from = c("Semi", "Single", "Row", "Apartment"),
to = c(1, 2, 3, 4))
Resultado:
> dat
HouseType house_type_num
1 Semi 1
2 Single 2
3 Row 3
4 Single 2
5 Apartment 4
6 Apartment 4
7 Row 3
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-10-20 20:37:18
Usar merge es diferente de buscar en Excel, ya que tiene potencial para duplicar (multiplicar) sus datos si la restricción de clave primaria no se aplica en la tabla de búsqueda o reducir el número de registros si no está utilizando all.x = T.
Para asegurarse de que no se meta en problemas con eso y busque con seguridad, sugiero dos estrategias.
El primero es hacer una verificación en un número de filas duplicadas en la clave de búsqueda:
safeLookup <- function(data, lookup, by, select = setdiff(colnames(lookup), by)) {
# Merges data to lookup making sure that the number of rows does not change.
stopifnot(sum(duplicated(lookup[, by])) == 0)
res <- merge(data, lookup[, c(by, select)], by = by, all.x = T)
return (res)
}
Esto le obligará a des-copiar el conjunto de datos de búsqueda antes de usar it:
baseSafe <- safeLookup(largetable, house.ids, by = "HouseType")
# Error: sum(duplicated(lookup[, by])) == 0 is not TRUE
baseSafe<- safeLookup(largetable, unique(house.ids), by = "HouseType")
head(baseSafe)
# HouseType HouseTypeNo
# 1 Apartment 4
# 2 Apartment 4
# ...
La segunda opción es reproducir el comportamiento de Excel tomando el primer valor coincidente del conjunto de datos de búsqueda:
firstLookup <- function(data, lookup, by, select = setdiff(colnames(lookup), by)) {
# Merges data to lookup using first row per unique combination in by.
unique.lookup <- lookup[!duplicated(lookup[, by]), ]
res <- merge(data, unique.lookup[, c(by, select)], by = by, all.x = T)
return (res)
}
baseFirst <- firstLookup(largetable, house.ids, by = "HouseType")
Estas funciones son ligeramente diferentes de lookup ya que agregan múltiples columnas.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-05-21 23:03:54