¿Cómo hacer que los organismos virtuales aprendan usando redes neuronales? [cerrado]
Estoy haciendo una simulación de aprendizaje simple, donde hay múltiples organismos en la pantalla. Se supone que deben aprender a comer, usando sus simples redes neuronales. Tienen 4 neuronas, y cada neurona activa el movimiento en una dirección (es un plano 2D visto desde la perspectiva del pájaro, por lo que solo hay cuatro direcciones, por lo tanto, se requieren cuatro salidas). Su única entrada son "cuatro ojos". Solo un ojo puede estar activo en el momento, y básicamente sirve como un puntero al objeto más cercano (ya sea un bloque de alimentos verdes u otro organismo).
Por lo tanto, la red se puede imaginar así:
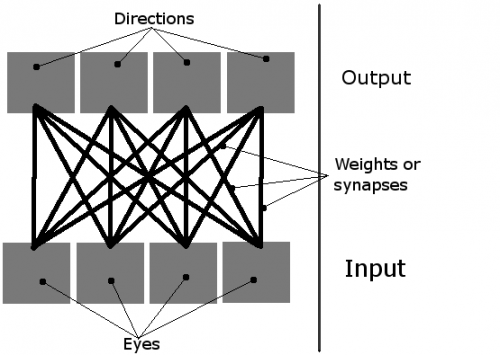
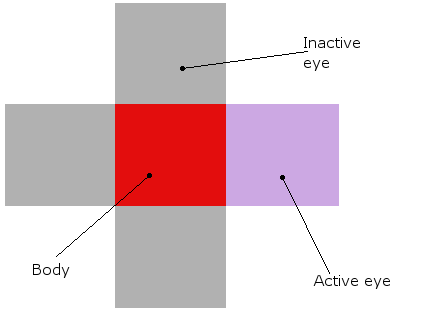
Y un organismo se ve así (tanto en teoría como en la simulación real, donde realmente son bloques rojos con sus ojos alrededor de ellos):
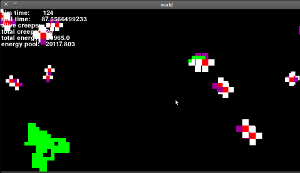
Y así es como todo se ve (esta es una versión antigua, donde los ojos todavía no funcionaban, pero es similar):
Ahora que he descrito mi idea general, permítanme llegar al corazón de la problema...
Inicialización| Primero, creo algunos organismos y comida. Luego, todos los 16 pesos en sus redes neuronales se establecen en valores aleatorios, como este: peso = aleatorio.random () * umbral * 2. Umbral es un valor global que describe la cantidad de entrada que cada neurona necesita para activarse ("disparar"). Por lo general se establece en 1.
Aprendizaje| De forma predeterminada, los pesos en las redes neuronales se reducen un 1% en cada paso. Pero, si algún organismo consigue realmente comer algo, se refuerza la conexión entre la última entrada activa y la salida.
Pero, hay un gran problema. Creo que este no es un buen enfoque, porque en realidad no aprenden nada! Solo aquellos que tenían sus pesos iniciales establecidos aleatoriamente para ser beneficiosos tendrán la oportunidad de comer algo, ¡y entonces solo ellos tendrán sus pesos fortalecidos! ¿Qué hay de aquellos que tenían sus conexiones mal establecidas? Ellos sólo morir, no aprender.
¿Cómo puedo evitar esto? La única solución que viene a la mente es aumentar/disminuir aleatoriamente los pesos, para que eventualmente, alguien obtenga la configuración correcta y coma algo por casualidad. Pero creo que esta solución es muy cruda y fea. ¿Tienes alguna idea?
EDITAR: Gracias por sus respuestas! Cada uno de ellos fue muy útil, algunos eran simplemente más relevantes. He decidido utilizar el siguiente enfoque:
- Establecer todo los pesos a números aleatorios.
- Disminuya los pesos con el tiempo.
- A veces aumenta o disminuye aleatoriamente un peso. Cuanto más exitosa sea la unidad, menos pesos se cambiarán. NUEVO
- Cuando un organismo come algo, aumente el peso entre la entrada correspondiente y la salida.
6 answers
Esto es similar a los problemas al tratar de encontrar un mínimo global, donde es fácil quedarse atascado en un mínimo local. Considera tratar de encontrar el mínimo global para el siguiente perfil: colocas la bola en diferentes lugares y la sigues a medida que rueda cuesta abajo hasta el mínimo, pero dependiendo de dónde la coloques, puedes quedarte atascado en un chapuzón local.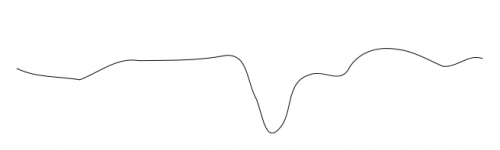
Es decir, en situaciones complicadas, no siempre se puede llegar a la mejor solución desde todos los puntos de partida utilizando pequeñas optimización de incrementos. Las soluciones generales para esto son fluctuar los parámetros (es decir, pesos, en este caso) más vigorosamente (y generalmente reducir el tamaño de las fluctuaciones a medida que avanza la simulación like como en el recocido simulado), o simplemente darse cuenta de que un montón de los puntos de partida no van a ir a ningún lugar interesante.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-01-25 18:00:48
Como mencionó Mika Fischer, esto suena similar a los problemas de la vida artificial, por lo que esa es una vía que podría mirar.
También suena un poco como si estuvieras tratando de reinventar El Aprendizaje por refuerzo. Yo recomendaría leer a través de Aprendizaje por refuerzo: Una Introducción , que está disponible gratuitamente en forma HTML en ese sitio web, o se puede comprar en formato de árbol muerto. Código de ejemplo y soluciones también se proporcionan en esa página.
Uso de redes neuronales (y otros aproximadores de función) y técnicas de planificación se discute más adelante en el libro, así que no se desanime si el material inicial parece demasiado básico o no aplicable a su problema.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-01-25 17:44:19
¿Cómo quieres que aprenda? No te gusta el hecho de que los organismos sembrados al azar mueran o prosperen, pero la única vez que proporcionas retroalimentación a tu organismo es si obtienen comida al azar.
Vamos a modelar esto como caliente y frío. Actualmente, todo se alimenta "frío" excepto cuando el organismo está justo encima de los alimentos. Así que la única oportunidad de aprender es correr accidentalmente sobre la comida. Puede apretar este bucle para proporcionar una retroalimentación más continua si lo desea. Comentario caliente si hay movimiento hacia la comida, frío si se aleja.
Ahora, la desventaja de esto es que no hay entrada para nada más. Sólo tienes una técnica de aprendizaje de buscador de alimentos. Si quieres que tus organismos encuentren un equilibrio entre el hambre y otra cosa (por ejemplo, evitar el hacinamiento, aparearse, etc.), es probable que todo el mecanismo necesite ser repensado.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-01-25 18:03:26
Hay varios algoritmos que se pueden utilizar para optimizar los pesos en una red neuronal, el más común de los cuales es el algoritmo de backpropogation .
Al leer tu pregunta deduzco que estás tratando de construir bots de redes neuronales que busquen comida. La forma de lograr esto con backpropogation sería tener un período de aprendizaje inicial, donde los pesos se establecen inicialmente al azar (como lo está haciendo) y se refinan gradualmente utilizando la backpropogation algoritmo hasta que alcancen un nivel de rendimiento con el que estés satisfecho. En ese punto, puede evitar que aprendan y permitirles divertirse libremente en Flatland.
Sin embargo, creo que puede haber algunos problemas con el diseño de su red. En primer lugar, si solo hay 1 ojo activo en cualquier momento, tendría más sentido tener solo un nodo de entrada y realizar un seguimiento de la orientación de alguna otra manera (si lo entiendo correctamente). Simplemente, si solo hay un ojo activo y cuatro acciones posibles (adelante, atrás, izquierda, derecha) entonces las entradas de los ojos inactivos (presumiblemente cero) no tendrían ninguna relación con la decisión de salida, de hecho sospecho que los pesos para cada entrada a todas las salidas convergerían, esencialmente duplicando la misma función. Además, aumenta innecesariamente la complejidad de la red y aumenta el tiempo de aprendizaje. En segundo lugar, no se necesitan tantas neuronas de salida para representar todas las acciones posibles. Como se ha descrito allí, su salida sería {1,0,0,0} = derecha, {0,1,0,0} = izquierda y así sucesivamente. Dependiendo del tipo de neurona modelada, esto se puede hacer con 2 o incluso 1 neurona de salida. Si usa una neurona binaria (cada salida es 1 o 0), entonces haga algo como {0,0} = atrás, {1,1} = adelante, {1,0} = izquierda, {0,1} = derecha. Usando una neurona de función sigmoidal (la salida puede ser un número real de 0..1), puedes hacer {0} = atrás, {0.33} = izquierda, {0.66} = derecha, {1} = adelante.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-01-25 18:13:16
Puedo ver un montón de problemas potenciales.
En primer lugar, no tengo claro el algoritmo que actualiza tus pesos. Me gusta la disminución del 1% como concepto looks parece que estás tratando de descartar recuerdos lejanos, lo cual es bueno en principio but pero el resto probablemente no es suficiente. Es necesario mirar algunos de los algoritmos de actualización estándar como backpropagation, pero eso es solo un comienzo, porque....
...Solo estás dando crédito a tu red para la última etapa de comer la comida. No parece que haya ningún mecanismo directo para acercar gradualmente su red a los alimentos, o a los grupos de alimentos. Incluso tomando la direccionalidad de los ojos en su valor nominal, sus ojos son muy simples, y no hay mucha memoria a largo plazo.
Además, si su diagrama de red es preciso, probablemente no sea suficiente. Realmente desea tener una capa oculta (al menos una) entre los sensores y los actuadores, si utiliza algo relacionado con backpropagation. Hay matemáticas detalladas detrás de esa afirmación, pero se reduce a, "Las capas ocultas permitirán buenas soluciones de más problemas."
Ahora, observe que muchos de mis comentarios están hablando de la arquitectura de la red, pero solo en términos generales sin decir concretamente, "Esto funcionará" o "eso funcionará"."Eso es porque yo tampoco lo sé (aunque creo que la sugerencia de Kwatford de aprendizaje por refuerzo es muy buena.) A veces, puedes evolucione los parámetros de red, así como las instancias de red. Una de estas técnicas es la Neuroevolución de Topologías Crecientes, o"NEAT". Tal vez valga la pena echarle un vistazo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-01-25 19:56:39
Creo que un ejemplo más complejo de lo que estás haciendo es presentado por Polyworld.
También puedes ver la presentación de Google Tech Talks de 2007: http://www.youtube.com/watch?v=_m97_kL4ox0
Sin embargo, la idea fundamental es adoptar un enfoque evolutivo dentro de su sistema: use pequeñas mutaciones aleatorias combinadas con el cruce genético (como la forma principal de diversificación) y seleccione individuos que sean "mejores" adecuados para sobrevivir. ambiente.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-01-25 18:26:36