¿Cómo funciona HashPartitioner?
He leído sobre la documentación de HashPartitioner. Desafortunadamente, no se explicó mucho, excepto por las llamadas a la API. Estoy bajo el supuesto de que HashPartitioner particiona el conjunto distribuido basado en el hash de las claves. Por ejemplo, si mis datos son como
(1,1), (1,2), (1,3), (2,1), (2,2), (2,3)
Entonces partitioner pondría esto en diferentes particiones con las mismas claves que caen en la misma partición. Sin embargo, no entiendo la importancia del argumento del constructor
new HashPartitoner(numPartitions) //What does numPartitions do?
Para el conjunto de datos anterior cómo ¿diferirían los resultados si lo hiciera
new HashPartitoner(1)
new HashPartitoner(2)
new HashPartitoner(10)
Entonces, ¿cómo funciona HashPartitioner en realidad?
3 answers
Bueno, vamos a hacer su conjunto de datos marginalmente más interesante:
val rdd = sc.parallelize(for {
x <- 1 to 3
y <- 1 to 2
} yield (x, None), 8)
, Tenemos seis elementos:
rdd.count
Long = 6
Sin particionador:
rdd.partitioner
Option[org.apache.spark.Partitioner] = None
Y ocho particiones:
rdd.partitions.length
Int = 8
Ahora vamos a definir pequeño ayudante para contar el número de elementos por partición:
import org.apache.spark.rdd.RDD
def countByPartition(rdd: RDD[(Int, None.type)]) = {
rdd.mapPartitions(iter => Iterator(iter.length))
}
Dado que no tenemos particionador, nuestro conjunto de datos se distribuye uniformemente entre particiones ( Chispa):
countByPartition(rdd).collect()
Array[Int] = Array(0, 1, 1, 1, 0, 1, 1, 1)

Ahora vamos a reparticionar nuestro conjunto de datos:
import org.apache.spark.HashPartitioner
val rddOneP = rdd.partitionBy(new HashPartitioner(1))
Dado que el parámetro pasado a HashPartitioner define el número de particiones, esperamos una partición:
rddOneP.partitions.length
Int = 1
Dado que solo tenemos una partición, contiene todos los elementos:{[46]]}
countByPartition(rddOneP).collect
Array[Int] = Array(6)
Tenga en cuenta que el orden de los valores después de la mezcla no es determinista.
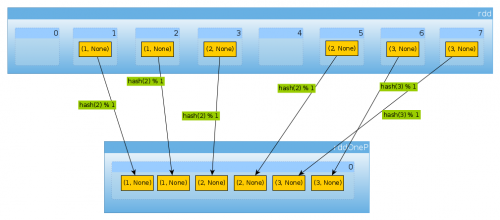
De la misma manera si usamos HashPartitioner(2)
val rddTwoP = rdd.partitionBy(new HashPartitioner(2))
Obtendremos 2 particiones:
rddTwoP.partitions.length
Int = 2
Dado que rdd está particionado por datos clave, ya no se distribuirán de manera uniforme:
countByPartition(rddTwoP).collect()
Array[Int] = Array(2, 4)
Porque con tener tres claves y solo dos valores diferentes de hashCode mod numPartitions no hay nada inesperado aquí:
(1 to 3).map((k: Int) => (k, k.hashCode, k.hashCode % 2))
scala.collection.immutable.IndexedSeq[(Int, Int, Int)] = Vector((1,1,1), (2,2,0), (3,3,1))
Solo para confirmar lo anterior: {[46]]}
rddTwoP.mapPartitions(iter => Iterator(iter.map(_._1).toSet)).collect()
Array[scala.collection.immutable.Set[Int]] = Array(Set(2), Set(1, 3))
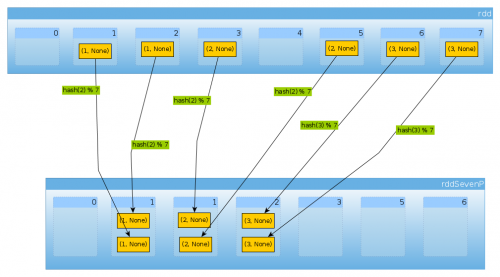
Finalmente con HashPartitioner(7) obtenemos siete particiones, tres no vacías con 2 elementos cada uno:
val rddSevenP = rdd.partitionBy(new HashPartitioner(7))
rddSevenP.partitions.length
Int = 7
countByPartition(rddTenP).collect()
Array[Int] = Array(0, 2, 2, 2, 0, 0, 0)
Resumen y Notas
-
HashPartitionertoma un solo argumento que define el número de particiones -
Los valores se asignan a las particiones usando
hashde claves.hashla función puede diferir dependiendo del lenguaje (Scala RDD puede usarhashCode,DataSetsuse MurmurHash 3, PySpark,portable_hash).En caso simple como este, donde la clave es un entero pequeño, se puede suponer que
hashes una identidad (i = hash(i)).Usos de la API de Scala
nonNegativeModpara determinar la partición basada en el hash calculado, -
Si la distribución de claves no es uniforme, puede terminar en situaciones en las que parte de su clúster esté inactivo
-
Las claves tienen que ser hashables. Puede comprobar mi respuesta para Una lista como clave para la reduceByKey de PySpark para leer sobre problemas específicos de PySpark. Otro posible problema es resaltado por HashPartitioner documentación:
Los arrays Java tienen hashCodes que se basan en las identidades de los arrays en lugar de su contenido, por lo que intenta particionar un RDD [Array []] o RDD [(Array[], _)] el uso de un HashPartitioner producirá un resultado inesperado o incorrecto.
En Python 3 tienes que asegurarte de que el hash sea consistente. Ver ¿Qué hace la excepción: La aleatoriedad del hash de la cadena debe desactivarse a través de PYTHONHASHSEED significa en ¿pyspark?
El particionador Hash no es ni inyectivo ni sobreyectivo. Se pueden asignar varias claves a una sola partición y algunas particiones pueden permanecer vacías.
Tenga en cuenta que actualmente los métodos basados en hash no funcionan en Scala cuando se combinan con clases de caso definidas por REPL (Igualdad de clase de caso en Apache Spark).
HashPartitioner(o cualquier otroPartitioner) baraja los datos. A menos que la partición se reutilice entre múltiples operaciones no reduce la cantidad de datos que se deben barajar.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-02-10 12:11:31
RDD se distribuye esto significa que se divide en un cierto número de partes. Cada una de estas particiones está potencialmente en una máquina diferente. El particionador Hash con arument numPartitions elige en qué partición colocar par (key, value) de manera predeterminada:
- Crea exactamente
numPartitionsparticiones. - Coloca
(key, value)en la partición con el númeroHash(key) % numPartitions
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-07-15 10:01:15
El método HashPartitioner.getPartition toma una clave como argumento y devuelve el índice de la partición a la que pertenece la clave. El particionador tiene que saber cuáles son los índices válidos, por lo que devuelve números en el rango correcto. El número de particiones se especifica a través del argumento constructor numPartitions.
La implementación devuelve aproximadamente key.hashCode() % numPartitions. Ver Particionador.scala para más detalles.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-07-15 10:42:05