¿Cómo determino k cuando uso k-means clustering?
He estado estudiando acerca de k-means clustering, y una cosa que no está clara es cómo elegir el valor de k. ¿Es solo una cuestión de ensayo y error, o hay más en ello?
15 answers
Puede maximizar el Criterio de Información Bayesiano (BIC):
BIC(C | X) = L(X | C) - (p / 2) * log n
Donde L(X | C) es el log-verosimilitud del conjunto de datos X según el modelo C, p es el número de parámetros en el modelo C, y n es el número de puntos en el conjunto de datos.
Ver "X-means: extending K-means with efficient estimation of the number of clusters" por Dan Pelleg y Andrew Moore en ICML 2000.
Otro enfoque es comenzar con un valor grande para k y sigue quitando centroides (reduciendo k) hasta que ya no reduzca la longitud de la descripción. Ver "MDL principle for robust vector quantisation" por Horst Bischof, Ales Leonardis, y Alexander Selb en Pattern Analysis and Applications vol. 2, p. 59-72, 1999.
Finalmente, puede comenzar con un clúster y luego seguir dividiendo clústeres hasta que los puntos asignados a cada clúster tengan una distribución gaussiana. En "Aprendiendo el k en k -significa" (NIPS 2003), Greg Hamerly y Charles Elkan muestran cierta evidencia de que esto funciona mejor que BIC, y que BIC no penaliza la complejidad del modelo con la suficiente fuerza.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-11-15 20:11:11
Básicamente, desea encontrar un equilibrio entre dos variables: el número de clústeres ( k) y la varianza promedio de los clústeres. Usted desea minimizar el primero mientras que también minimiza el segundo. Por supuesto, a medida que aumenta el número de grupos, la varianza promedio disminuye (hasta el caso trivial de k=n y varianza = 0).
Como siempre en el análisis de datos, no hay un enfoque verdadero que funcione mejor que todos los demás en todos los casos. Al final, tienes para usar tu mejor criterio. Para eso, ayuda a trazar el número de clústeres contra la varianza promedio (lo que supone que ya ha ejecutado el algoritmo para varios valores de k). A continuación, puede utilizar el número de grupos en la rodilla de la curva.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2009-11-24 23:06:31
Sí, puede encontrar el mejor número de clústeres usando el método Elbow, pero me pareció problemático encontrar el valor de los clústeres de elbow graph usando script. Puedes observar el gráfico del codo y encontrar el punto del codo tú mismo, pero fue mucho trabajo encontrarlo desde el guión.
Así que otra opción es usar Método de silueta para encontrarlo. El resultado de la silueta cumple completamente con el resultado del método del codo en R.
Esto es lo que hice.
#Dataset for Clustering
n = 150
g = 6
set.seed(g)
d <- data.frame(x = unlist(lapply(1:g, function(i) rnorm(n/g, runif(1)*i^2))),
y = unlist(lapply(1:g, function(i) rnorm(n/g, runif(1)*i^2))))
mydata<-d
#Plot 3X2 plots
attach(mtcars)
par(mfrow=c(3,2))
#Plot the original dataset
plot(mydata$x,mydata$y,main="Original Dataset")
#Scree plot to deterine the number of clusters
wss <- (nrow(mydata)-1)*sum(apply(mydata,2,var))
for (i in 2:15) {
wss[i] <- sum(kmeans(mydata,centers=i)$withinss)
}
plot(1:15, wss, type="b", xlab="Number of Clusters",ylab="Within groups sum of squares")
# Ward Hierarchical Clustering
d <- dist(mydata, method = "euclidean") # distance matrix
fit <- hclust(d, method="ward")
plot(fit) # display dendogram
groups <- cutree(fit, k=5) # cut tree into 5 clusters
# draw dendogram with red borders around the 5 clusters
rect.hclust(fit, k=5, border="red")
#Silhouette analysis for determining the number of clusters
library(fpc)
asw <- numeric(20)
for (k in 2:20)
asw[[k]] <- pam(mydata, k) $ silinfo $ avg.width
k.best <- which.max(asw)
cat("silhouette-optimal number of clusters:", k.best, "\n")
plot(pam(d, k.best))
# K-Means Cluster Analysis
fit <- kmeans(mydata,k.best)
mydata
# get cluster means
aggregate(mydata,by=list(fit$cluster),FUN=mean)
# append cluster assignment
mydata <- data.frame(mydata, clusterid=fit$cluster)
plot(mydata$x,mydata$y, col = fit$cluster, main="K-means Clustering results")
Espero que ayuda!!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-08-05 11:07:30
Mira este documento, "Aprendiendo la k en k-significa" por Greg Hamerly, Charles Elkan. Utiliza una prueba gaussiana para determinar el número correcto de grupos. Además, los autores afirman que este método es mejor que el BIC que se menciona en la respuesta aceptada.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-04-07 21:33:52
Puede ser alguien principiante como yo buscando ejemplo de código. información para silhouette_score está disponible aquí.
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
range_n_clusters = [2, 3, 4] # clusters range you want to select
dataToFit = [[12,23],[112,46],[45,23]] # sample data
best_clusters = 0 # best cluster number which you will get
previous_silh_avg = 0.0
for n_clusters in range_n_clusters:
clusterer = KMeans(n_clusters=n_clusters)
cluster_labels = clusterer.fit_predict(dataToFit)
silhouette_avg = silhouette_score(dataToFit, cluster_labels)
if silhouette_avg > previous_silh_avg:
previous_silh_avg = silhouette_avg
best_clusters = n_clusters
# Final Kmeans for best_clusters
kmeans = KMeans(n_clusters=best_clusters, random_state=0).fit(dataToFit)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-01-24 04:25:40
Primero construya un árbol de expansión mínimo de sus datos.
La eliminación de los bordes K-1 más caros divide el árbol en grupos K,
para que pueda construir el MST una vez, mire los espaciamientos / métricas del clúster para varios K,
y toma la rodilla de la curva.
Esto solo funciona para Single-linkage_clustering,
pero para eso es rápido y fácil. Además, los MST son buenos visuales.
Véase, por ejemplo, el gráfico MST en
estadísticas.software de visualización stackexchange para clustering .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-04-13 12:44:14
Hay algo llamado Regla General. Dice que el número de racimos se puede calcular por k = (n/2)^0,5, donde n es el número total de elementos de su muestra. Puede comprobar la veracidad de esta información en el siguiente documento:
Http://www.ijarcsms.com/docs/paper/volume1/issue6/V1I6-0015.pdf
También hay otro método llamado G-means, donde su distribución sigue una Distribución Gaussiana, o Distribución Normal. Consiste en aumentar k hasta que todos sus grupos k sigan una distribución Gaussiana. Requiere muchas estadísticas, pero se puede hacer. Aquí está la fuente:
Http://papers.nips.cc/paper/2526-learning-the-k-in-k-means.pdf
Espero que esto ayude!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-03-09 14:21:20
Si utiliza MATLAB, cualquier versión desde 2013b es decir, puede hacer uso de la función evalclusters para averiguar cuál debe ser el k óptimo para un conjunto de datos dado.
Esta función le permite elegir entre 3 algoritmos de clustering - kmeans, linkage y gmdistribution.
También le permite elegir entre 4 criterios de evaluación de clustering- CalinskiHarabasz, DaviesBouldin, gap y silhouette.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-03-15 11:26:13
Me sorprende que nadie haya mencionado este excelente artículo: http://www.ee.columbia.edu / ~dpwe / papers / PhamDN05-kmeans. pdf
Después de seguir varias otras sugerencias, finalmente me encontré con este artículo mientras leía este blog: https://datasciencelab.wordpress.com/2014/01/21/selection-of-k-in-k-means-clustering-reloaded/
Después lo implementé en Scala, una implementación que para mis casos de uso proporciona muy buenos resultados. Aquí está el código:
import breeze.linalg.DenseVector
import Kmeans.{Features, _}
import nak.cluster.{Kmeans => NakKmeans}
import scala.collection.immutable.IndexedSeq
import scala.collection.mutable.ListBuffer
/*
https://datasciencelab.wordpress.com/2014/01/21/selection-of-k-in-k-means-clustering-reloaded/
*/
class Kmeans(features: Features) {
def fkAlphaDispersionCentroids(k: Int, dispersionOfKMinus1: Double = 0d, alphaOfKMinus1: Double = 1d): (Double, Double, Double, Features) = {
if (1 == k || 0d == dispersionOfKMinus1) (1d, 1d, 1d, Vector.empty)
else {
val featureDimensions = features.headOption.map(_.size).getOrElse(1)
val (dispersion, centroids: Features) = new NakKmeans[DenseVector[Double]](features).run(k)
val alpha =
if (2 == k) 1d - 3d / (4d * featureDimensions)
else alphaOfKMinus1 + (1d - alphaOfKMinus1) / 6d
val fk = dispersion / (alpha * dispersionOfKMinus1)
(fk, alpha, dispersion, centroids)
}
}
def fks(maxK: Int = maxK): List[(Double, Double, Double, Features)] = {
val fadcs = ListBuffer[(Double, Double, Double, Features)](fkAlphaDispersionCentroids(1))
var k = 2
while (k <= maxK) {
val (fk, alpha, dispersion, features) = fadcs(k - 2)
fadcs += fkAlphaDispersionCentroids(k, dispersion, alpha)
k += 1
}
fadcs.toList
}
def detK: (Double, Features) = {
val vals = fks().minBy(_._1)
(vals._3, vals._4)
}
}
object Kmeans {
val maxK = 10
type Features = IndexedSeq[DenseVector[Double]]
}
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-03-13 10:54:19
Mi idea es usar Coeficiente de silueta para encontrar el número óptimo de clúster(K). La explicación detallada está aquí.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-04-13 12:44:17
Suponiendo que tenga una matriz de datos llamada DATA, puede realizar particiones alrededor de medoids con estimación del número de clusters (por análisis de silueta) de la siguiente manera:
library(fpc)
maxk <- 20 # arbitrary here, you can set this to whatever you like
estimatedK <- pamk(dist(DATA), krange=1:maxk)$nc
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-06-29 20:12:11
Una posible respuesta es usar un Algoritmo Meta Heurístico como un Algoritmo Genético para encontrar k. Eso es simple. puede usar random K (en algún rango) y evaluar la función de ajuste del Algoritmo Genético con alguna medición como Silhouette Y encuentre la mejor base K en la función de ajuste.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-06-19 17:19:12
km=[]
for i in range(num_data.shape[1]):
kmeans = KMeans(n_clusters=ncluster[i])#we take number of cluster bandwidth theory
ndata=num_data[[i]].dropna()
ndata['labels']=kmeans.fit_predict(ndata.values)
cluster=ndata
co=cluster.groupby(['labels'])[cluster.columns[0]].count()#count for frequency
me=cluster.groupby(['labels'])[cluster.columns[0]].median()#median
ma=cluster.groupby(['labels'])[cluster.columns[0]].max()#Maximum
mi=cluster.groupby(['labels'])[cluster.columns[0]].min()#Minimum
stat=pd.concat([mi,ma,me,co],axis=1)#Add all column
stat['variable']=stat.columns[1]#Column name change
stat.columns=['Minimum','Maximum','Median','count','variable']
l=[]
for j in range(ncluster[i]):
n=[mi.loc[j],ma.loc[j]]
l.append(n)
stat['Class']=l
stat=stat.sort(['Minimum'])
stat=stat[['variable','Class','Minimum','Maximum','Median','count']]
if missing_num.iloc[i]>0:
stat.loc[ncluster[i]]=0
if stat.iloc[ncluster[i],5]==0:
stat.iloc[ncluster[i],5]=missing_num.iloc[i]
stat.iloc[ncluster[i],0]=stat.iloc[0,0]
stat['Percentage']=(stat[[5]])*100/count_row#Freq PERCENTAGE
stat['Cumulative Percentage']=stat['Percentage'].cumsum()
km.append(stat)
cluster=pd.concat(km,axis=0)## see documentation for more info
cluster=cluster.round({'Minimum': 2, 'Maximum': 2,'Median':2,'Percentage':2,'Cumulative Percentage':2})
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-08-26 06:37:21
Otro enfoque es el uso de Mapas Autoorganizados (SOP) para encontrar el número óptimo de clústeres. El SOM (Mapa Auto-Organizado) es un sistema neural no supervisado metodología de red, que solo necesita la entrada se utiliza para clustering para la resolución de problemas. Este enfoque se utilizó en un documento sobre la segmentación de clientes.
La referencia del artículo es
Abdellah Amine y otros, Modelo de Segmentación de Clientes en E-commerce Utilizando Técnicas de Clustering y Modelo LRFM: El Caso de Tiendas en Línea en Marruecos, Academia Mundial de Ciencia, Ingeniería y Tecnología International Journal of Computer and Information Engineering Vol: 9, No:8, 2015, 1999 - 2010
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-07-31 08:48:54
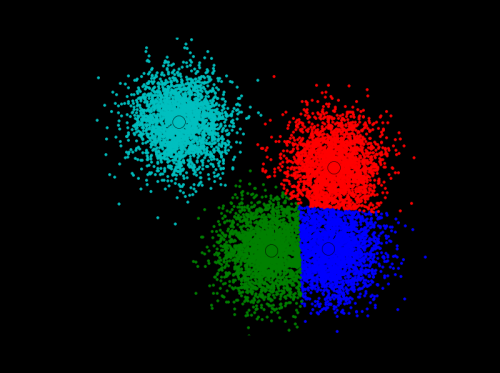
Usé la solución que encontré aquí: http://efavdb.com/mean-shift / y funcionó muy bien para mí:
import numpy as np
from sklearn.cluster import MeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs
import matplotlib.pyplot as plt
from itertools import cycle
from PIL import Image
#%% Generate sample data
centers = [[1, 1], [-.75, -1], [1, -1], [-3, 2]]
X, _ = make_blobs(n_samples=10000, centers=centers, cluster_std=0.6)
#%% Compute clustering with MeanShift
# The bandwidth can be automatically estimated
bandwidth = estimate_bandwidth(X, quantile=.1,
n_samples=500)
ms = MeanShift(bandwidth=bandwidth, bin_seeding=True)
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
n_clusters_ = labels.max()+1
#%% Plot result
plt.figure(1)
plt.clf()
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(n_clusters_), colors):
my_members = labels == k
cluster_center = cluster_centers[k]
plt.plot(X[my_members, 0], X[my_members, 1], col + '.')
plt.plot(cluster_center[0], cluster_center[1],
'o', markerfacecolor=col,
markeredgecolor='k', markersize=14)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-02-15 00:31:03