Cómo calcular el parámetro de regularización en regresión lineal
Cuando tenemos un polinomio lineal de alto grado que se usa para ajustar un conjunto de puntos en una configuración de regresión lineal, para evitar el sobreajuste, usamos la regularización e incluimos un parámetro lambda en la función de costo. Esta lambda se utiliza para actualizar los parámetros theta en el algoritmo de descenso de gradiente.
Mi pregunta es ¿cómo calculamos este parámetro de regularización lambda?
3 answers
El parámetro de regularización (lambda) es una entrada a su modelo, así que lo que probablemente desee saber es cómo selecciona el valor de lambda. El parámetro de regularización reduce el sobreajuste, lo que reduce la varianza de los parámetros de regresión estimados; sin embargo, lo hace a expensas de agregar sesgo a su estimación. El aumento de lambda resulta en menos sobreajuste, pero también mayor sesgo. Así que la verdadera pregunta es " ¿Cuánto sesgo estás dispuesto a tolerar en tu estimación?"
Un enfoque que puede tomar es submuestrar aleatoriamente sus datos varias veces y observar la variación en su estimación. Luego repita el proceso para obtener un valor ligeramente mayor de lambda para ver cómo afecta la variabilidad de su estimación. Tenga en cuenta que cualquier valor de lambda que decida que es apropiado para sus datos submuestrados, es probable que pueda usar un valor más pequeño para lograr una regularización comparable en el conjunto de datos completo.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-08-29 16:24:35
FORMA CERRADA (TIKHONOV) VERSUS DESCENSO DE GRADIENTE
Hola! bonitas explicaciones para los enfoques matemáticos intuitivos y de primera categoría allí. Solo quería agregar algunas especificidades que, donde no "resolución de problemas", definitivamente pueden ayudar a acelerar y dar cierta consistencia al proceso de encontrar un buen hiperparámetro de regularización.
Asumo que estás hablando de la regularización L2 (a.k. "weight decay"), linealmente ponderada por el lambda término, y que está optimizando los pesos de su modelo ya sea con la forma cerrada Ecuación de Tikhonov (muy recomendable para modelos de regresión lineal de baja dimensión), o con alguna variante de descenso de gradiente con backpropagation. Y que en este contexto, desea elegir el valor para lambda que proporciona la mejor capacidad de generalización.
FORMA CERRADA (TIKHONOV)
Si usted es capaz de ir a la Forma de Tikhonov con su modelo ( Andrew Ng dice bajo dimensiones 10k, pero esta sugerencia tiene al menos 5 años) Wikipedia - determinación del factor de Tikhonov ofrece una interesante solución de forma cerrada, que se ha demostrado que proporciona el valor óptimo . Pero esta solución probablemente plantea algún tipo de problemas de implementación (complejidad temporal/estabilidad numérica) de los que no soy consciente, porque no hay un algoritmo convencional para realizarla. This 2016 sin embargo, paper parece muy prometedor y puede valer la pena intentarlo si realmente tiene que optimizar su modelo lineal al máximo.
- Para una implementación de prototipo más rápida, esto 2015 El paquete Python parece lidiar con él iterativamente, podría dejarlo optimizar y luego extraer el valor final para la lambda:
En este nuevo método innovador, hemos derivado un enfoque iterativo para resolver el problema general de regularización de Tikhonov, que converge a la solución silenciosa, no depende fuertemente de la elección de lambda, y aún así evita el problema de inversión.
Y del GitHub README del proyecto:
InverseProblem.invert(A, be, k, l) #this will invert your A matrix, where be is noisy be, k is the no. of iterations, and lambda is your dampening effect (best set to 1)
DESCENSO DEL GRADIENTE
Todos los enlaces de esta parte son del increíble libro en línea de Michael Nielsen "Neural Networks and Deep Learning", conferencia recomendada!
Para este enfoque parece ser aún menos que decir: la función de costo es generalmente no convexo, la optimización se realiza numéricamente y el rendimiento del modelo se mide por alguna forma de validación cruzada (ver Sobreajuste y Regularización y ¿por qué la regularización ayuda a reducir el sobreajuste si no ha tenido suficiente de eso). Pero incluso cuando se realiza la validación cruzada, Nielsen sugiere algo: es posible que desee echar un vistazo a esta explicación detallada sobre cómo la regularización L2 proporciona un efecto de descomposición del peso, pero el resumen es que es inversamente proporcional al número de muestras n, así que al calcular la ecuación de descenso de gradiente con el término L2,
Simplemente use backpropagation, como de costumbre, y luego agregue
(λ/n)*wa la derivada parcial de todos los términos de peso.
Y su conclusión es que, cuando se desea un efecto de regularización similar con un número diferente de muestras, lambda tiene que cambiarse proporcionalmente: {[18]]}
Necesitamos modificar la parámetro de regularización. La razón es porque el tamaño
ndel conjunto de entrenamiento ha cambiado den=1000an=50000, y esto cambia el factor de decaimiento de peso1−learning_rate*(λ/n). Si continuamos usandoλ=0.1eso significaría mucho menos decaimiento de peso, y por lo tanto mucho menos de un efecto de regularización. Compensamos cambiando aλ=5.0.
Esto solo es útil cuando se aplica el mismo modelo a diferentes cantidades de los mismos datos, pero creo que abre la puerta a alguna intuición sobre cómo debería funcionar, y, lo que es más importante, acelere el proceso de hiperparametrización al permitirle ajustar lambda en subconjuntos más pequeños y luego escalar.
Para elegir los valores exactos, sugiere en sus conclusiones sobre cómo elegir los hiperparámetros de una red neuronal el enfoque puramente empírico: comience con 1 y luego multiplique y divida progresivamente por 10 hasta encontrar el orden adecuado de magnitud, y luego haga una búsqueda local dentro de esa región. En los comentarios de esta SE pregunta relacionada, el usuario Brian Borchers sugiere también un método muy conocido que puede ser útil para esa búsqueda local:
- Tomar pequeños subconjuntos de los conjuntos de entrenamiento y validación (para poder hacer muchos de ellos en un tiempo razonable)
- Comenzando con
λ=0y aumentando en pequeñas cantidades dentro de alguna región, realice un entrenamiento y validación rápidos del modelo y trace ambas funciones de pérdida - Observarás tres cosas:
- El CV la función de pérdida será consistentemente más alta que la de entrenamiento, ya que su modelo está optimizado para los datos de entrenamiento exclusivamente (EDITAR: Después de algún tiempo he visto un caso MNIST donde agregar L2 ayudó a la pérdida de CV a disminuir más rápido que la de entrenamiento hasta la convergencia. Probablemente debido a la consistencia ridícula de los datos y una hiperparametrización subóptima aunque ).
- La función de pérdida de entrenamiento tendrá su mínimo para
λ=0, y luego aumentará con la regularización, ya que evitar que el modelo se ajuste de manera óptima a los datos de entrenamiento es exactamente lo que hace la regularización. - La función de pérdida de CV comenzará alta en
λ=0, luego disminuirá y luego comenzará a aumentar nuevamente en algún momento ( EDITAR: esto asumiendo que la configuración es capaz de sobreajustar paraλ=0, es decir, el modelo tiene suficiente potencia y no se aplican otros medios de regularización en gran medida).
- El valor óptimo para
λserá probablemente en algún lugar alrededor del mínimo de la función de pérdida de CV, también puede depender un poco de cómo se ve la función de pérdida de entrenamiento. Vea la imagen para una posible (pero no la única) representación de esto: en lugar de "complejidad del modelo" debe interpretar el eje x comoλsiendo cero a la derecha y aumentando hacia la izquierda.
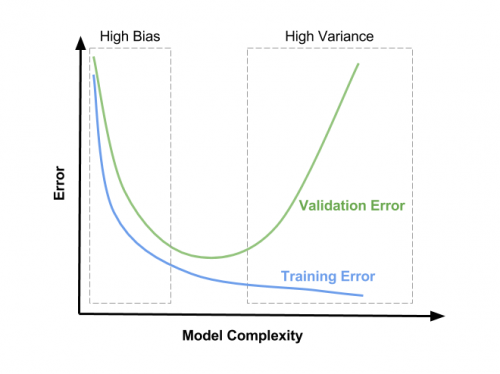
Espero que esto ayude! Salud,
Andres
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2018-04-05 01:41:39
La validación cruzada descrita anteriormente es un método utilizado a menudo en el Aprendizaje automático. Sin embargo, la elección de un parámetro de regularización confiable y seguro sigue siendo un tema muy candente de investigación en matemáticas. Si necesita algunas ideas (y tener acceso a una biblioteca universitaria decente) puede echar un vistazo a este documento: http://www.sciencedirect.com/science/article/pii/S0378475411000607
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2013-10-18 16:29:02