Chispa en la comprensión del concepto de hilo
Estoy tratando de entender cómo se ejecuta spark en el cluster/cliente de YARN. Tengo la siguiente pregunta en mi mente.
¿Es necesario que spark esté instalado en todos los nodos del clúster de yarn? Creo que debería porque los nodos de trabajo en el clúster ejecutan una tarea y deben ser capaces de decodificar el código(API de spark) en la aplicación spark enviada al clúster por el controlador?
Dice en la documentación " Asegúrese de que
HADOOP_CONF_DIRoYARN_CONF_DIRapunta al directorio que contiene el (del lado del cliente) archivos de configuración para el clúster de Hadoop". ¿Por qué el nodo cliente tiene que instalar Hadoop cuando envía el trabajo al clúster?
3 answers
Estamos ejecutando trabajos de spark en YARN (usamos HDP 2.2).
No tenemos spark instalado en el clúster. Solo añadimos el Spark assembly jar a los HDFS.
Por ejemplo para ejecutar el ejemplo Pi:
./bin/spark-submit \
--verbose \
--class org.apache.spark.examples.SparkPi \
--master yarn-cluster \
--conf spark.yarn.jar=hdfs://master:8020/spark/spark-assembly-1.3.1-hadoop2.6.0.jar \
--num-executors 2 \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 4 \
hdfs://master:8020/spark/spark-examples-1.3.1-hadoop2.6.0.jar 100
--conf spark.yarn.jar=hdfs://master:8020/spark/spark-assembly-1.3.1-hadoop2.6.0.jar - Este config decir el hilo de fueron a tomar el conjunto de chispa. Si no lo usa, cargará el jar desde donde ejecuta spark-submit.
Acerca de su segunda pregunta: El nodo cliente no necesita tener instalado Hadoop. Solo necesita la configuración file. Puede copiar el directorio del clúster al cliente.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2016-06-12 12:03:18
Añadiendo a otras respuestas..
- ¿Es necesario que spark esté instalado en todos los nodos de yarn ¿cluster?
No , Si el trabajo de spark está programando en YARN(ya sea en modo client o cluster). La instalación de Spark se necesita en muchos nodos solo para el modo independiente .
Estas son las visualizaciones de los modos de implementación de aplicaciones de spark.
Clúster independiente de Spark
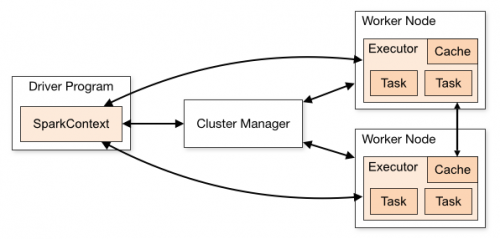
En modo cluster controlador estará sentado en uno de los nodos de Spark Worker mientras que en el modo client estará dentro de la máquina que lanzó el trabajo .
YARN cluster mode
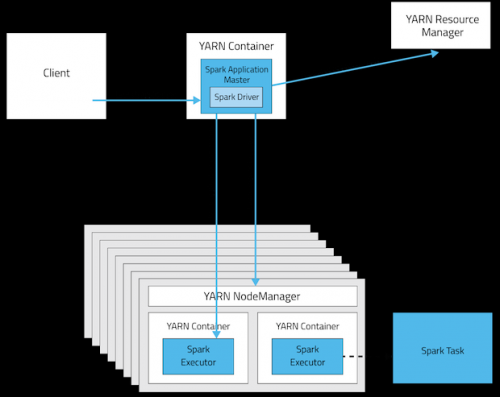
Modo cliente de YARN
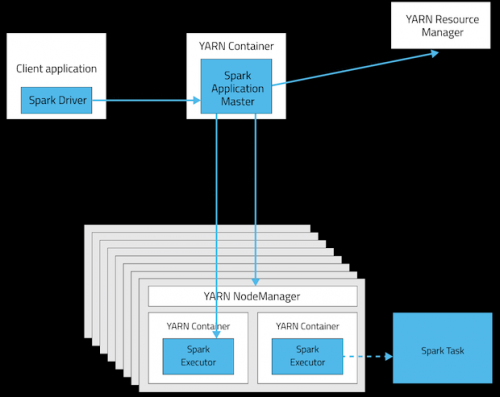
Esta tabla ofrece una lista concisa de las diferencias entre estos modos:

- Dice en la documentación " Asegúrese de que HADOOP_CONF_DIR o YARN_CONF_DIR apunta a el directorio que contiene el (lado del cliente) archivos de configuración para el clúster de Hadoop". Por qué el nodo cliente tiene ¿para instalar hadoop cuando envía el trabajo al clúster?
La instalación de Hadoop no es obligatoria, pero las configuraciones lo son!. Estas podrían ser las dos razones principales.
- La configuración contenida en el directorio
HADOOP_CONF_DIRserá distribuido al clúster de HILADO para que todos los contenedores utilizados por el la aplicación utiliza la misma configuración. - En el modo YARN la dirección del ResourceManager se recoge de la
Configuración Hadoop (
yarn-default.xml). Por lo tanto, el parámetro--masteresyarn.
Actualizar: (2017-01-04)
Spark 2.0 + ya no requiere un frasco de ensamblaje de grasa para la producción despliegue. fuente
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-02-16 06:21:59
1-Spark si sigue la arquitectura slave / master. Así que en tu cluster, tienes que instalar un spark master y N spark slaves. Puede ejecutar spark en modo independiente. Pero el uso de la arquitectura Yarn le dará algunos beneficios. Hay una muy buena explicación de esto aquí: http://blog.cloudera.com/blog/2014/05/apache-spark-resource-management-and-yarn-app-models/
2 - Es necesario si desea utilizar Yarn o HDFS, por ejemplo, pero como he dicho antes se puede ejecutar en modo independiente.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-02-10 00:58:53