Ayúdame a mejorar mi flujo de trabajo de implementación continua
He estado desarrollando un flujo de trabajo para practicar un ciclo de despliegue continuo en su mayoría automatizado para un proyecto PHP. Me gustaría recibir comentarios sobre posibles cuellos de botella técnicos o de proceso en este flujo de trabajo, sugerencias para mejorar e ideas sobre cómo automatizar mejor y aumentar la facilidad de uso para mi equipo.
Componentes Básicos:
-
HudsonCI server -
GityGitHub -
PHPUnitpruebas unitarias Selenium RC-
Sauce OnDemandpara pruebas automatizadas, entre navegadores y en la nube conSelenium RC -
Puppetpara automatizar implementaciones de servidores de prueba -
Gerritpara revisión de código Git -
Gerrit TriggerparaHudson
EDIT : He cambiado el gráfico del flujo de trabajo para tener en cuenta las contribuciones de ircmaxwell: eliminando la extensión de PHPUnit para Selenium RC y ejecutar esas pruebas solo como parte de la etapa de control de calidad; agregar una etapa de control de calidad; mover las pruebas de la interfaz de usuario después de la revisión del código pero antes de las fusiones; mover las fusiones después de la etapa de control de calidad; mover la implementación después de la fusión.
Este gráfico de flujo de trabajo describe el proceso. Mis preguntas / pensamientos / preocupaciones siguen.
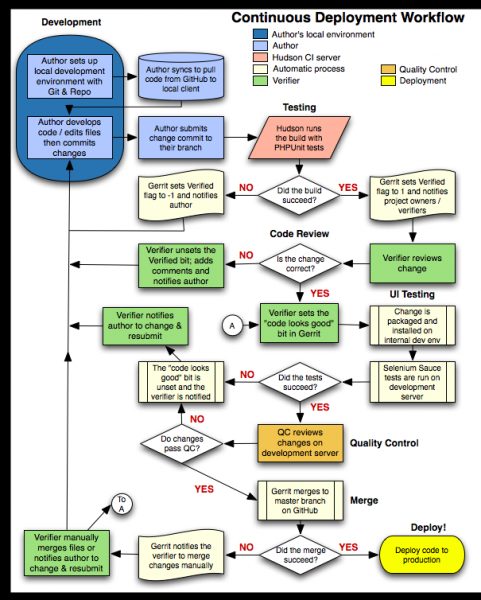
Mis preocupaciones / pensamientos / preguntas:
Dificultad general para usar este sistema.
Hora participación.
Dificultad para emplear
Gerrit.Dificultad para emplear
Puppet.Estaremos implementando en instancias
Amazon EC2más tarde. Si estamos configurandoDebianpaquetes conPuppety desplegándolos enLinodesectores ahora, ¿existe la posibilidad de que una implementación en funcionamiento enLinodese rompa enEC2? ¿Deberíamos hacer nuestras compilaciones e implementaciones enEC2desde el primer momento?Otra pregunta re:
EC2yPuppet. También estamos considerando usar Scalr como una solución. ¿Tendría tanto sentido evitar la sobrecarga dePuppetpara esto solo e invertir en Scalr en su lugar? Tengo una secundaria (¡ja!) preocupación aquí sobre el costo; las pruebasSeleniumno deberían estar funcionando que a menudo, las instancias de compilación deEC2se ejecutarán 24/7, pero para algo así como una compilación de cinco minutos, pagar por una hora de uso deEC2parece un poco demasiado.Posibles cuellos de botella en el proceso fusionar.
¿Se podría mover "A"?
Créditos : Partes de este flujo de trabajo están inspiradas en la impresionante publicación de Digg sobre el despliegue continuo. El gráfico de flujo de trabajo anterior está inspirado en el proyecto del sistema operativo Android.
4 answers
¿Cuánta gente está trabajando en ello? Si solo tienes tal vez 10 o 20 desarrolladores, no estoy seguro de que tenga sentido poner un flujo de trabajo tan elaborado en su lugar. Si estás manejando 500, seguro...
Mi sentimiento personal es el BESO. Mantenlo Simple, Estúpido... Quieres un proceso que sea eficiente y más importante: simple. Si es complicado, o nadie va a hacerlo bien, o después de tiempo las partes se resbalarán. Si lo haces simple, se convertirá en una segunda naturaleza y después de unos pocos semanas nadie cuestionaría el proceso (Bueno, la semántica del mismo de todos modos)...
Y el otro sentimiento personal es siempre ejecutar todas sus pruebas UNITARIAS. De esa manera, puede omitir un árbol de decisiones completo en su diagrama de flujo. Después de todo, lo que es más caro, unos minutos de tiempo de CPU, o los ciclos cerebrales para entender la diferencia entre la prueba parcial que pasa y la prueba masiva que falla. Recuerde, un fallo es un fallo, y no hay ninguna razón práctica por la que el código debe mostrarse a un revisor que tiene el potencial de fallar la compilación.
Ahora, las pruebas de selenio suelen ser bastante caras, por lo que podría estar de acuerdo en posponerlas hasta que el revisor las apruebe. Pero tendrás que pensar en eso...
Oh, y si estuviera implementando esto, pondría una etapa formal de control de calidad allí. Quiero que los probadores humanos miren cualquier cambio que se esté haciendo. Sí, el selenio puede verificar las cosas que sabes, pero solo un humano puede encontrar cosas en las que no pensaste. Feed back sus hallazgos en nuevas pruebas de Selenio e Integración para prevenir regresiones...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-09-13 19:06:53
Importent para hacer sus pruebas extremadamente rápido, es decir, sin IO y la capacidad de ejecutar paralelo y pruebas distribuidas. No sé qué tan aplicable es con php, pero si puede probar unidades de código con la base de datos de memoria y burlarse del entorno, estará mejor.
Si tiene un QA/QC o cualquier humano en el camino entre el commit y la producción, tendría un problema para llegar a un despliegue continuo completo. La clave es su confianza en sus pruebas, monitoreo y auto respuesta (sistema inmune) suficiente para eliminar el proceso propenso a errores humanos en evolución de su sistema.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-09-14 04:03:39
Todos los traspasos entre funciones tienen el efecto de ralentizar las cosas, y con eso, un aumento de la cantidad de cambio (y por lo tanto de riesgo) que entra en un despliegue.
Las puertas de calidad manuales son, por definición, una aceptación de que la calidad no se ha incorporado desde el principio. El único código de denegación que debe revisarse más tarde es porque hay cierta creencia de que la calidad no es lo suficientemente buena ya.
Actualmente estoy tratando de eliminar la revisión formal de código de nuestras canalizaciones exactamente por esta razón. Causa retrasos en la retroalimentación, y citando a Martin Fowler:
"El objetivo de la Integración Continua es proporcionar retroalimentación rápida. Nada chupa la sangre de una actividad de IC más que una acumulación que toma mucho tiempo. "
En su lugar me gustaría hacer revisión de código algo que los remitentes solicitan si es necesario, o de lo contrario se hace en el momento de la codificación por los miembros del equipo, tal vez un par de programación la XP.
Creo que debería ser su objetivo que una vez que el código se fusiona con el control de código fuente, que no hay absolutamente ninguna más intervención manual.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2012-09-06 22:23:42
No se si esto es relevante para PHP, pero puede reemplazar al menos parte de la etapa de revisión de código con análisis estático.
La calidad de las revisiones de código se basa en la calidad de los revisores, mientras que el análisis estático se basa en las mejores prácticas y patrones, y es completamente automático. No estoy diciendo que las revisiones de código deben ser abandonadas, simplemente creo que se puede hacer fuera de línea.
Véase
Http://en.wikipedia.org/wiki/Static_code_analysis
Http://en.wikipedia.org/wiki/List_of_tools_for_static_code_analysis
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2010-09-14 11:46:56