Agrupación de texto con distancias Levenshtein
Tengo un conjunto (2k - 4k) de cadenas pequeñas (3-6 caracteres) y quiero agruparlas. Dado que uso cadenas, respuestas anteriores en ¿Cómo funciona la agrupación en clústeres (especialmente la agrupación en clústeres de cadenas)?, me informó que Levenshtein distance es bueno para ser utilizado como una función de distancia para cadenas. Además, dado que no conozco de antemano el número de clústeres, la agrupación jerárquica es el camino a seguir y no k-significa.
Aunque entiendo el problema en su forma abstracta, no sé cuál es la manera más fácil de hacerlo. Por ejemplo, es MATLAB o R una mejor opción para la implementación real de la agrupación jerárquica con la función personalizada (distancia de Levenshtein). Para ambos programas, uno puede encontrar fácilmente una implementación a distancia de Levenshtein. La parte de agrupamiento parece más difícil. Por ejemplo Clustering text en MATLAB calcula la matriz de distancia para todas las cadenas, pero no puedo entender cómo usar la matriz de distancia para obtener realmente la agrupación. ¿Puede alguno de ustedes gurús mostrarme la manera de implementar la agrupación jerárquica en MATLAB o R con una función personalizada?
4 answers
Esto puede ser un poco simplista, pero aquí hay un ejemplo de código que utiliza la agrupación jerárquica basada en la distancia de Levenshtein en R.
set.seed(1)
rstr <- function(n,k){ # vector of n random char(k) strings
sapply(1:n,function(i){do.call(paste0,as.list(sample(letters,k,replace=T)))})
}
str<- c(paste0("aa",rstr(10,3)),paste0("bb",rstr(10,3)),paste0("cc",rstr(10,3)))
# Levenshtein Distance
d <- adist(str)
rownames(d) <- str
hc <- hclust(as.dist(d))
plot(hc)
rect.hclust(hc,k=3)
df <- data.frame(str,cutree(hc,k=3))
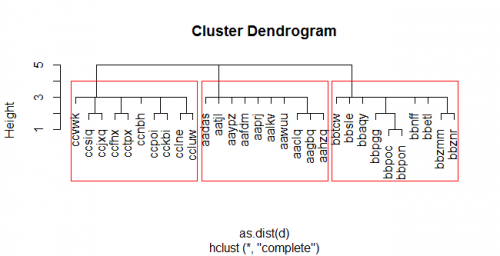
En este ejemplo, creamos un conjunto de 30 cadenas char(5) aleatorias artificialmente en 3 grupos (comenzando con "aa", "bb" y "cc"). Calculamos la matriz de distancias de Levenshtein usando adist(...), y ejecutamos el clustering heirarchal usando hclust(...). Luego cortamos el dendrograma en tres clústeres con cutree(...) y agregamos los id del clúster al original cadena.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-02-02 18:39:23
ELKI incluye Levenshtein distance, y ofrece una amplia variedad de algoritmos avanzados de clustering, por ejemplo OPTICS clustering.
El apoyo a la agrupación de textos fue contribuido por Felix Stahlberg, como parte de su trabajo sobre:
Stahlberg, F., Schlippe, T., Vogel, S., & Schultz, T.
Segmentación de palabras a través de la alineación de palabras a fonemas en varios idiomas.
Taller de Tecnología del Lenguaje Hablado (SLT), 2012 IEEE. IEEE, 2012.
Nosotros por supuesto, agradecería contribuciones adicionales.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-02-03 14:47:07
Mientras que la respuesta depende en cierto grado del significado de las cadenas, en general su problema se resuelve mediante la familia de técnicas de análisis de secuencias. Más específicamente, Análisis de Coincidencia Óptima (OMA).
Muy a menudo el OMA se lleva a cabo en tres pasos. Primero, defines tus secuencias. De su descripción puedo asumir que cada letra es un "estado" separado, el bloque de construcción en una secuencia. En segundo lugar, empleará uno de los varios algoritmos para calcular el distancias entre todas las secuencias del conjunto de datos, obteniendo así la matriz de distancias. Finalmente, alimentará esa matriz de distancia en un algoritmo de agrupación, como la agrupación jerárquica o la partición Alrededor de Medoids (PAM), que parece ganar popularidad debido a la información adicional sobre la calidad de los clústeres. Este último lo guía en la elección del número de clústeres, uno de los varios pasos subjetivos en el análisis de secuencias.
En R el más conveniente paquete con un gran número de funciones es TraMineR, el sitio web se puede encontrar aquí . Su guía de usuario es muy accesible, y los desarrolladores están más o menos activos en él también.
Es probable que encuentre que la agrupación no es la parte más difícil, excepto por la decisión sobre el número de agrupaciones. La guía para TraMineR muestra que la sintaxis es muy directa, y los resultados son fáciles de interpretar basados en gráficos de secuencia visual. Aquí hay un ejemplo de la guía del usuario:
clusterward1 <- agnes(dist.om1, diss = TRUE, method = "ward")
dist.om1 es la matriz de distancia obtenida por OMA, la pertenencia al clúster está contenida en el objeto clusterward1, que puede hacer lo que quiera: trazado, recodificación como variables, etc. La opción diss=TRUE indica que el objeto de datos es la matriz de disimilitud (o distancia). Fácil, eh? La opción más difícil (no sintácticamente, sino metodológicamente) es elegir el algoritmo de distancia adecuado, adecuado para su aplicación particular. Una vez que usted tiene que ser capaz de justificar la elección, el resto es bastante fácil. ¡Buena suerte!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-02-02 16:34:25
Si desea una explicación clara de cómo usar el agrupamiento particional (que seguramente será más rápido) para resolver su problema, consulte este documento: Métodos Efectivos de Corrección Ortográfica Utilizando Algoritmos de Agrupamiento. https://www.researchgate.net/publication/255965260_Effective_Spell_Checking_Methods_Using_Clustering_Algorithms?ev=prf_pub
Los autores explican cómo agrupar un diccionario usando una versión modificada (similar a PAM) de IK-Means.
¡Mucha suerte!
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2014-02-03 09:56:01