A * Algoritmo para gráficos muy grandes, ¿alguna idea sobre los accesos directos de almacenamiento en caché?
Estoy escribiendo una simulación de mensajería/logística en mapas de OpenStreetMap y me he dado cuenta de que el algoritmo básico A* como se muestra a continuación no va a ser lo suficientemente rápido para mapas grandes (como el Gran Londres).
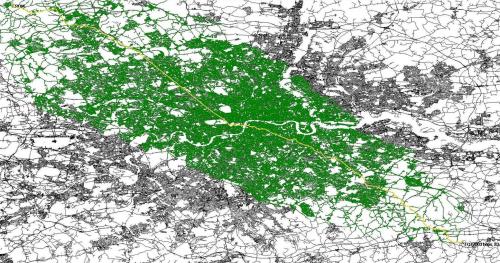
Los nodos verdes corresponden a los que se pusieron en la cola de conjunto abierto/prioridad y debido al gran número (todo el mapa es algo así como 1-2 millones), se tarda 5 segundos más o menos para encontrar la ruta en la foto. Desafortunadamente 100ms por ruta es sobre mi absoluto limite.
Actualmente, los nodos se almacenan tanto en una lista de adyacencia como en una matriz espacial 2D de 100x100.
Estoy buscando métodos donde pueda intercambiar el tiempo de preprocesamiento, el espacio y, si es necesario, la optimalidad de la ruta, por consultas más rápidas. La fórmula de Haversine en línea recta para el coste heurístico es la función más cara según el perfilador - he optimizado mi A * básico tanto como puedo.
Por ejemplo, estaba pensando si elegía un nodo arbitrario X de cada cuadrante de la matriz 2D y ejecutar un* entre cada uno, puedo almacenar las rutas al disco para simulaciones posteriores. Al realizar una consulta, puedo ejecutar una búsqueda* solo en los cuadrantes, para llegar entre la ruta precalculada y la X.
Hay una versión más refinada de lo que he descrito anteriormente o tal vez un método diferente que debería seguir. ¡Muchas gracias!
Para el registro, aquí hay algunos resultados de referencia para ponderar arbitrariamente el costo heurístico y calcular la ruta entre 10 pares de nodos seleccionados al azar:
Weight // AvgDist% // Time (ms)
1 1 1461.2
1.05 1 1327.2
1.1 1 900.7
1.2 1.019658848 196.4
1.3 1.027619169 53.6
1.4 1.044714394 33.6
1.5 1.063963413 25.5
1.6 1.071694171 24.1
1.7 1.084093229 24.3
1.8 1.092208509 22
1.9 1.109188175 22.5
2 1.122856792 18.2
2.2 1.131574742 16.9
2.4 1.139104895 15.4
2.6 1.140021962 16
2.8 1.14088128 15.5
3 1.156303676 16
4 1.20256964 13
5 1.19610861 12.9
Sorprendentemente, aumentar el coeficiente a 1.1 casi redujo a la mitad el tiempo de ejecución, manteniendo la misma ruta.
9 answers
Usted debe ser capaz de hacerlo mucho más rápido mediante el comercio de la optimalidad. Ver Admisibilidad y optimalidad en wikipedia.
La idea es usar un valor epsilon que conducirá a una solución no peor que 1 + epsilon veces la ruta óptima, pero que hará que el algoritmo considere menos nodos. Tenga en cuenta que esto no significa que la solución devuelta siempre será 1 + epsilon veces la ruta óptima. Este es el peor caso. No se exactamente como se comportaría en para tu problema, pero creo que vale la pena explorar.
Se le da una serie de algoritmos que se basan en esta idea en wikipedia. Creo que esta es su mejor apuesta para mejorar el algoritmo y que tiene el potencial de ejecutarse en su límite de tiempo mientras sigue devolviendo buenos caminos.
Dado que su algoritmo se ocupa de millones de nodos en 5 segundos, supongo que también utiliza montones binarios para la implementación, ¿correcto? Si los implementó manualmente, asegúrese de que son implementados como arrays simples y que son montones binarios.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-04-15 17:56:37
Hay algoritmos especializados para este problema que hacen mucho pre-cálculo. Desde la memoria, el pre-cómputo agrega información al gráfico que A * usa para producir una distancia heurística mucho más precisa que la distancia en línea recta. Wikipedia da los nombres de varios métodos en http://en.wikipedia.org/wiki/Shortest_path_problem#Road_networks y dice que el etiquetado de Hub es el líder. Una búsqueda rápida en esto aparece http://research.microsoft.com/pubs/142356/HL-TR.pdf . Una más antigua, usando un*, está en http://research.microsoft.com/pubs/64505/goldberg-sp-wea07.pdf .
¿Realmente necesita usar Haversine? Para cubrir Londres, hubiera pensado que podrías haber asumido una tierra plana y usado Pitágoras, o almacenado la longitud de cada enlace en el gráfico.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-04-15 18:05:12
Hay un gran artículo que Microsoft Research escribió sobre el tema:
Http://research.microsoft.com/en-us/news/features/shortestpath-070709.aspx
El documento original se encuentra aquí (PDF):
Http://www.cc.gatech.edu/~thad / 6601-gradAI-fall2012 / 02-search-Gutman04siam. pdf
Esencialmente hay algunas cosas que puedes probar:
- Comience tanto desde la fuente como desde el destino. Esto ayuda a minimizar el cantidad de trabajo desperdiciado que realizaría al atravesar desde la fuente hacia el destino.
- Use puntos de referencia y carreteras. Esencialmente, encuentre algunas posiciones en cada mapa que son rutas comúnmente tomadas y realice algunos cálculos previos para determinar cómo navegar eficientemente entre esos puntos. Si puede encontrar un camino desde su origen a un punto de referencia, luego a otros puntos de referencia, luego a su destino, puede encontrar rápidamente una ruta viable y optimizar desde alli.
- Explora algoritmos como el algoritmo "reach". Esto ayuda a minimizar la cantidad de trabajo que harás al atravesar el gráfico al minimizar el número de vértices que deben considerarse para encontrar una ruta válida.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-04-15 18:05:26
GraphHopper hace dos cosas más para obtener un enrutamiento rápido, no heurístico y flexible (nota: Soy el autor y puedes probarlo en línea aquí)
- Una optimización no tan obvia es evitar la asignación 1:1 de nodos OSM a nodos internos. En su lugar, GraphHopper utiliza solo uniones como nodos y guarda aproximadamente 1/8 de los nodos atravesados.
- Tiene implementaciones eficientes para A*, Dijkstra o, por ejemplo, Dijkstra de uno a muchos. Lo que hace posible una ruta en menores de 1 toda Alemania. La versión bidireccional (no heurística) de A* hace que esto sea aún más rápido.
Así que debería ser posible conseguir rutas rápidas para el gran Londres.
Además, el modo predeterminado es el modo de velocidad que hace que todo sea un orden de magnitudes más rápido (por ejemplo, 30 ms para rutas de ancho europeo) pero menos flexible, ya que requiere preprocesamiento (Jerarquías de contracción). Si no te gusta esto, simplemente deshabilitarlo y también afinar aún más el incluido calles para automóviles o probablemente mejor crear un nuevo perfil para camiones-por ejemplo, excluir las calles de servicio y las vías que deberían darle un aumento adicional del 30%. Y como con cualquier algoritmo bidireccional podría implementar fácilmente una búsqueda paralela.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-05-19 16:43:57
Creo que vale la pena trabajar en su idea con "cuadrantes". Más estrictamente, yo lo llamaría una búsqueda de ruta de baja resolución.
Puede elegir X nodos conectados que estén lo suficientemente cerca y tratarlos como un solo nodo de baja resolución. Divida su gráfico entero en tales grupos, y usted consigue un gráfico de baja resolución. Esta es una etapa de preparación.
Para calcular una ruta del origen al destino, primero identifique los nodos de baja resolución a los que pertenecen y encuentre la ruta de baja resolución. Entonces mejore su resultado encontrando la ruta en el gráfico de alta resolución, sin embargo restringiendo el algoritmo solo a nodos que pertenecen a nodos de baja resolución hte de la ruta de baja resolución (opcionalmente también puede considerar nodos vecinos de baja resolución hasta cierta profundidad).
Esto también puede generalizarse a múltiples resoluciones, no solo altas/bajas.
Al final debe obtener una ruta que esté lo suficientemente cerca de óptima. Es localmente óptimo, pero puede ser algo peor que óptimo a nivel mundial en cierta medida, lo que depende del salto de resolución (es decir, la aproximación que haga cuando un grupo de nodos se define como un solo nodo).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-04-15 18:25:09
Hay docenas de variaciones A* que pueden encajar aquí. Sin embargo, tienes que pensar en tus casos de uso.
- ¿Está limitado por la memoria (y también por la caché)?
- ¿Puedes paralelizar la búsqueda?
- ¿Se utilizará su implementación de algoritmo en un solo lugar (por ejemplo, el Gran Londres y no Nueva York o Mumbai o donde sea)?
No hay forma de que sepamos todos los detalles de los que usted y su empleador están al tanto. Su primera parada por lo tanto debe ser CiteSeer o Google Scholar: busque documentos que traten la búsqueda de caminos con el mismo conjunto general de restricciones que usted.
Luego, seleccione tres o cuatro algoritmos, haga el prototipado, pruebe cómo se escalan y finetune ellos. Debe tener en cuenta que puede combinar varios algoritmos en la misma gran rutina de búsqueda de caminos basada en la distancia entre los puntos, el tiempo restante o cualquier otro factor.
Como ya se ha dicho, basado en la pequeña escala de su objetivo Haversine es probablemente su primer paso para ahorrar un tiempo precioso en costosas evaluaciones trigonométricas. NOTA: No recomiendo usar la distancia euclidiana en coordenadas lat, lon-reproyecta tu mapa en un Mercator transversal, por ejemplo, cerca del centro y usa coordenadas cartesianas en yardas o metros!
La precomputación es la segunda, y cambiar de compiladores puede ser una tercera idea obvia (cambie a C o C++ - vea https://benchmarksgame.alioth.debian.org / para detalles).
Los pasos adicionales de optimización pueden incluir deshacerse de la asignación dinámica de memoria, y el uso de indexación eficiente para la búsqueda entre los nodos (piense en R-tree y sus derivados/alternativas).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-04-15 19:21:35
Trabajé en una importante compañía de navegación, por lo que puedo decir con confianza que 100 ms deberían conseguirte una ruta de Londres a Atenas incluso en un dispositivo integrado. Greater London sería un mapa de prueba para nosotros, ya que es convenientemente pequeño (cabe fácilmente en RAM - esto no es realmente necesario)
En primer lugar, A* está completamente desactualizado. Su principal ventaja es que "técnicamente" no requiere preprocesamiento. En la práctica, debe preprocesar un mapa de OSM de todos modos, por lo que no tiene sentido beneficio.
La técnica principal para darte un gran impulso de velocidad son las banderas de arco. Si divide el mapa en, por ejemplo, secciones de 5x6, puede asignar 1 posición de bits en un entero de 32 bits para cada sección. Ahora puede determinar para cada borde si alguna vez es útil cuando viaja a sección {X,Y} desde otra sección. Muy a menudo, las carreteras son bidireccionales y esto significa que solo una de las dos direcciones es útil. Así que una de las dos direcciones tiene ese bit establecido, y la otra lo tiene despejado. Este puede no parecer un beneficio real, pero significa que en muchas intersecciones se reduce el número de opciones a considerar de 2 a solo 1, y esto requiere solo una operación de bits.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-04-16 08:53:34
Por lo general, A* viene con demasiado consumo de memoria en lugar de problemas de tiempo.
Sin embargo, creo que podría ser útil calcular primero solo con nodos que son parte de "calles grandes", elegiría una carretera en lugar de un pequeño callejón generalmente.
Supongo que ya puede usar esto para su función de peso, pero puede ser más rápido si usa alguna Cola de prioridad para decidir qué nodo probar a continuación para viajar más.
También podría intentar reducir el gráfico a solo nodos que son parte de bordes de bajo costo y luego encontrar una manera de comenzar/terminar al más cercano de estos nodos. Así que tienes 2 caminos desde el inicio hasta la " calle grande "y la" calle grande " hasta el final. Ahora puede calcular la mejor ruta entre los dos nodos que forman parte de las" calles grandes " en un gráfico reducido.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2015-04-22 16:33:42
Vieja pregunta, pero todavía:
Trate de usar diferentes montones que "montón binario". 'El mejor montón de complejidad asintótica' es definitivamente el montón de Fibonacci y su página wiki tiene una buena visión general:
Https://en.wikipedia.org/wiki/Fibonacci_heap#Summary_of_running_times
Tenga en cuenta que el montón binario tiene un código más simple y se implementa sobre una matriz y el recorrido de la matriz es predecible, por lo que la CPU moderna ejecuta operaciones de montón binario mucho más rápido.
Sin embargo, dado conjunto de datos lo suficientemente grande, otros montones ganarán sobre montón binario, debido a sus complejidades...
Esta pregunta parece un conjunto de datos lo suficientemente grande.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/ajaxhispano.com/template/agent.layouts/content.php on line 61
2017-07-08 12:20:50